








-
这是中科大发表在CVPR2023的一篇论文,提出了一个module和一个损失项,能够提高现有exposure correction网络的性能。这已经是最近第三次看到这种论文了,前两篇分别是CVPR2022的ENC(和这篇文章是同一个一作作者)和CVPR2023的SKF,都是类似即插即用地提出一些模块来提高现有方法的性能,实验结果都是以方法A+XX比方法A性能提高,方法B+xx比方法B性能提高的方式展示。
-
文章的动机是,在多曝光数据集上训练时,同一个batch可能同时出现需要增亮的样本和需要抑制过曝的样本,而这两种样本的优化方向是相反的,从而产生负面影响。为了解决这个问题,本文提出通过学习一个batch的样本间的关系。不过我个人觉得这个逻辑上说不通,需要增亮的样本和需要抑制过曝的样本的优化方向相反问题通过归一化可以解决,通过样本间的关系解决就很奇怪了,本来样本间也没有什么关系。
-
而样本间关系主要是通过把特征转到 B × C B\times C B×C然后batch之间做注意力实现的,如下图所示,将encoder提取的 B C H W B C H W BCHW的特征reshape成 B × C ′ B\times C' B×C′,再attention,再resize回去,再decoder得到结果。这个过程是很直观简单的。比较复杂的是训练流程。首先丢掉中间的transformer的部分,先用reconstruction任务train encoder decoder,然后fix encoder decoder的参数只训练transformer的参数,这一阶段的训练仍然是reconstruction任务,但是不再是对 I I I和 I ′ I' I′算L1损失,而是取其相位分量算损失(从而剥离亮度因素)。文章认为,transformer本身自带的交互会影响这一重建任务,所以通过这一重建任务可以使得样本之间的内容交互作用被抑制,从而使得整个BCM模块只进行亮度交互作用
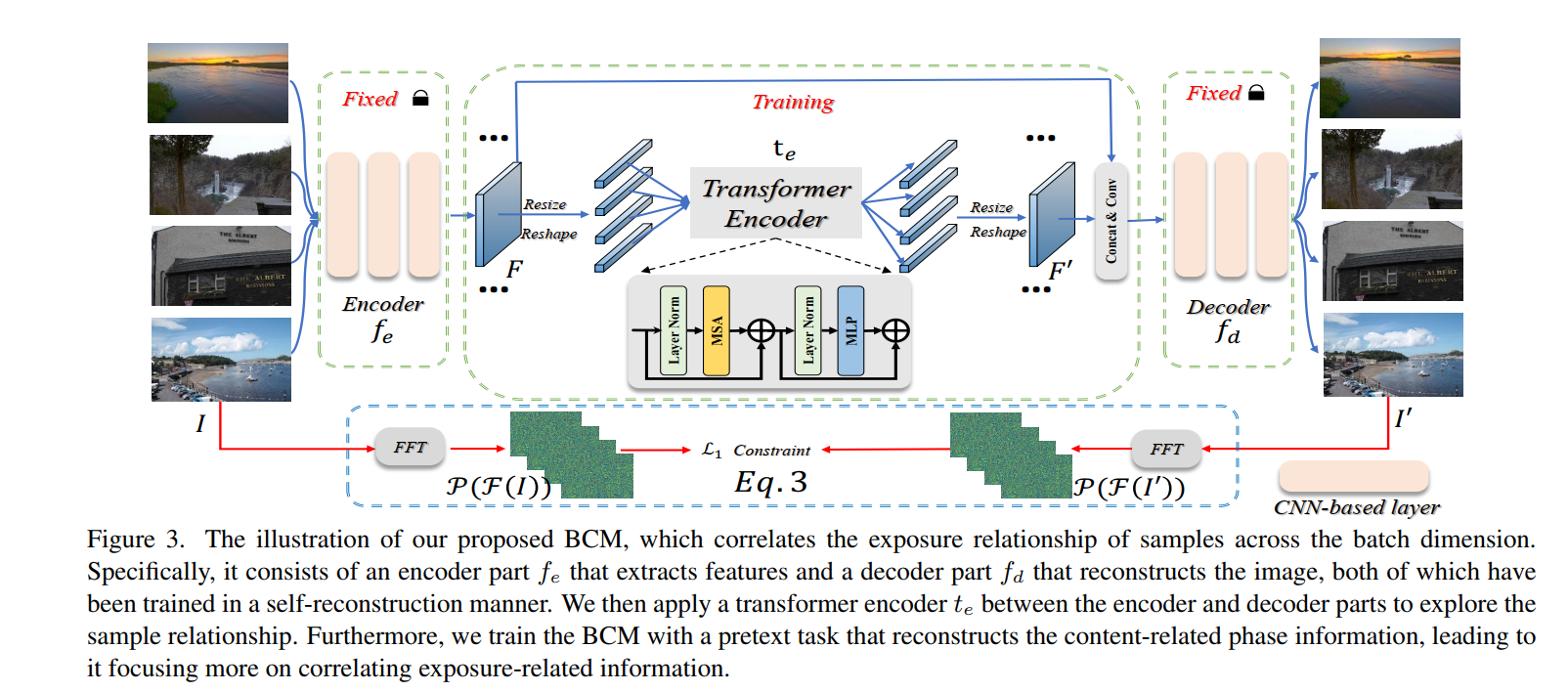
-
上面这个模型训练完之后呢,就产生了一个可以进行样本间交互的模块,然后在训练现有的exposure correction模型的时候,可以按下图的方式去利用上述模型的encoder和transformer去获取隐空间特征,计算GT和增强结果的隐空间特征的L1距离作为额外的损失:
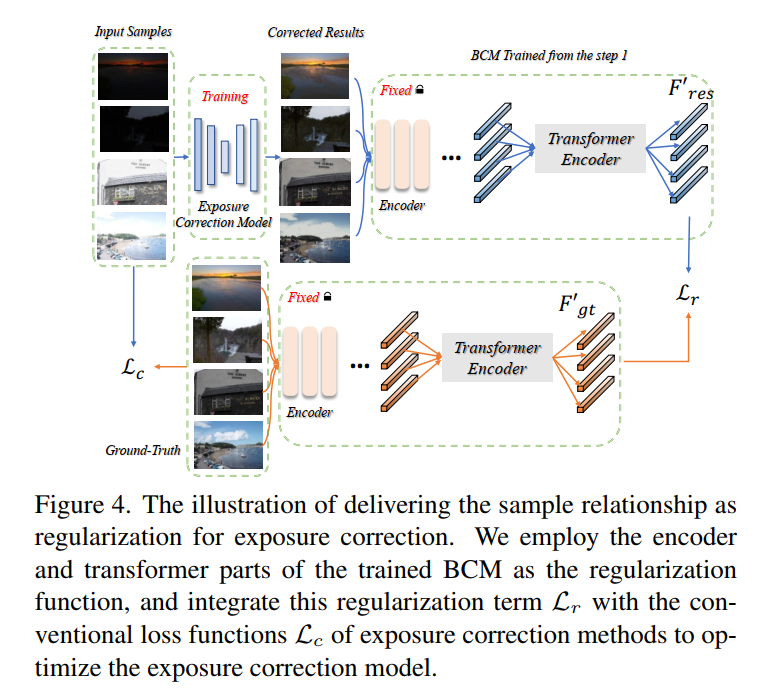
-
实验结果显示,通过这个方法可以提高一些现有方法的性能:
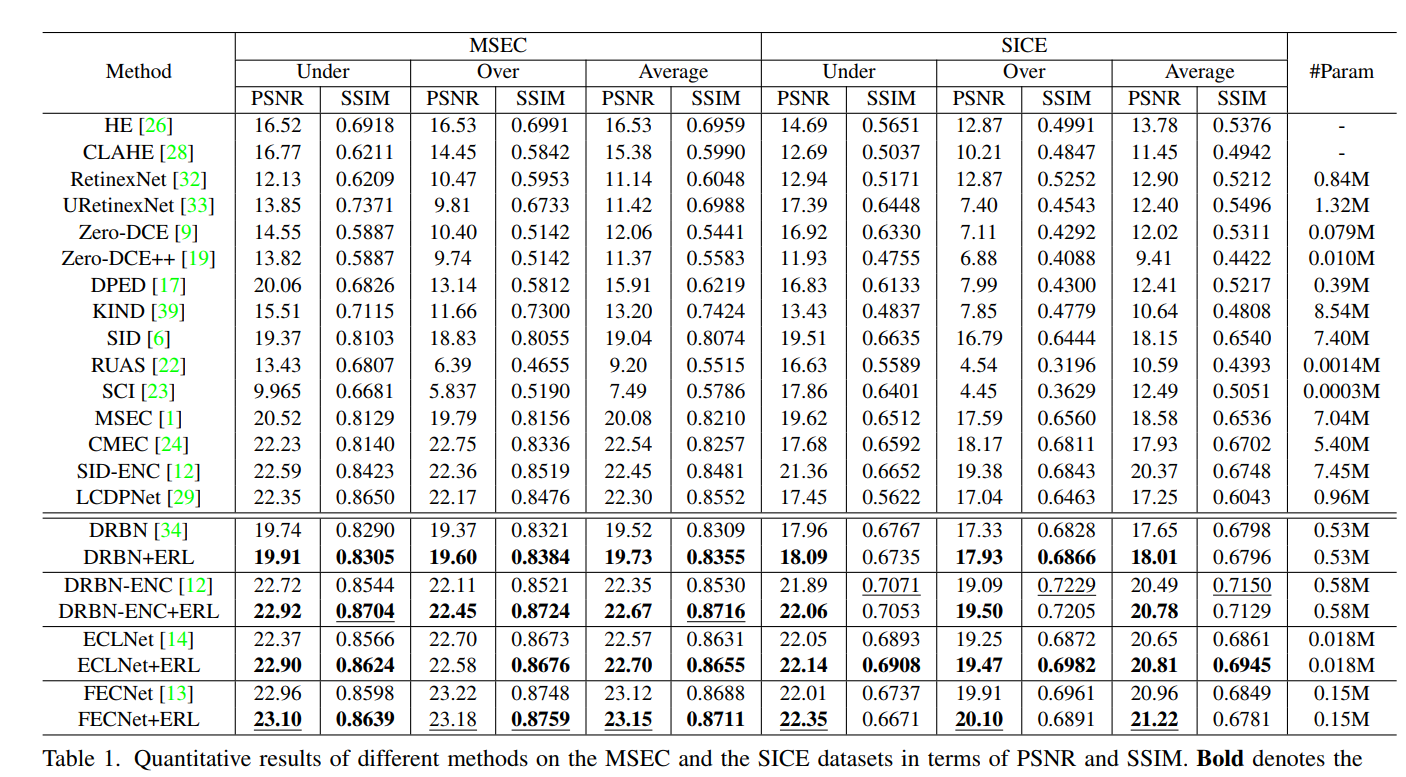
-
评价:角度很新奇,如果是真的,说明现有expsoure correction模型的潜能还没有被完全发掘出来,通过更合理的训练策略和损失函数,可以提高现有模型的性能,同时还不增加推理的计算负担。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









