








- 这是ICLR2024的一篇用VLM做multi-task image restoration的论文
- 首页图看起来就很猛啊,一个unified模型搞定10个任务:
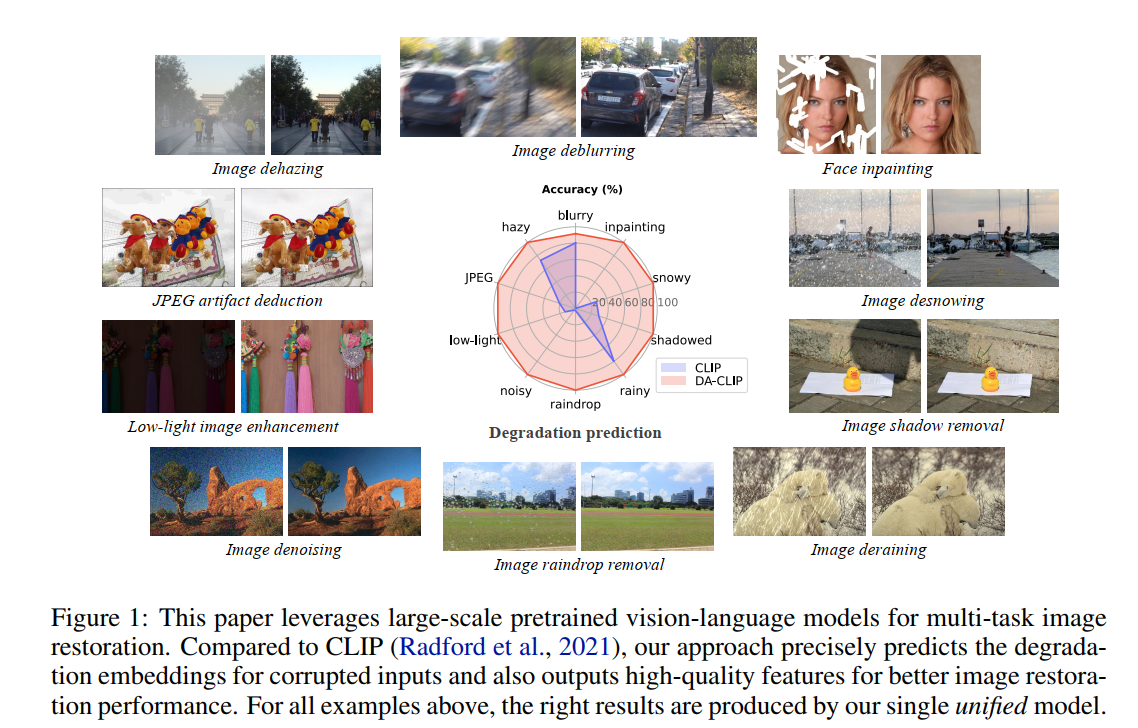
- 文章的贡献点主要是两个,一个是提出一个利用Image Controller,CLIP,cross-attention 和 diffusion restoration network 来实现 unified image restoration 的框架,一个是提出了一个数据集,有10种 degradation types 同时配有 hig-quality 的 synthetic captions。
- 文章提出的框架如下图所示,要train的是两个东西,一个是image controller,一个是restoration network:
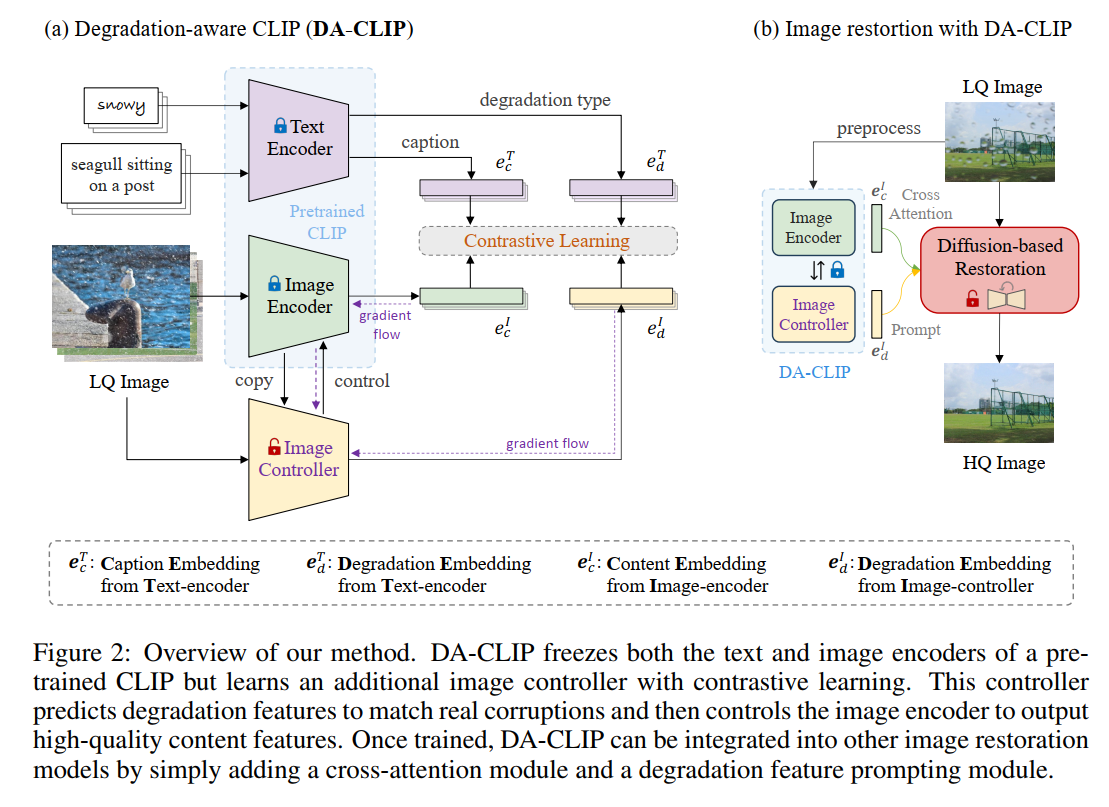
- Image controller的作用是从corrupted image feature 变成 high quality image feature,同时输出degradation type。train好的controller可以用来提取degradation prompt,同时把image encoder的特征变成HQ的特征,prompt用来指导restoration 的diffusion,HQ特征用来和diffusion的特征算cross attention,从而实现一个unified 模型解决multi-task restoration。
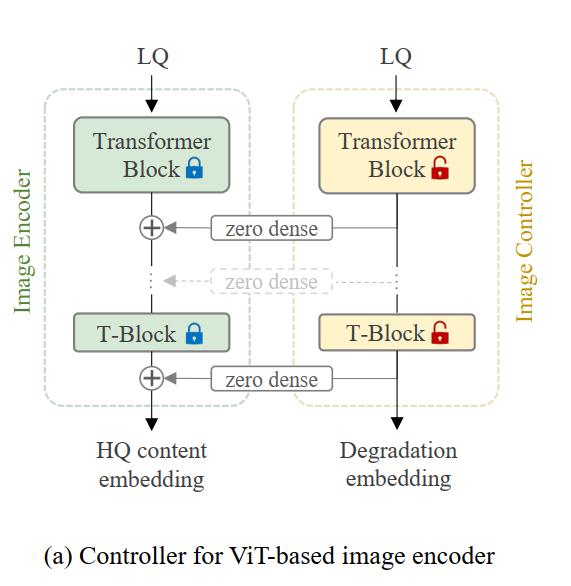
- Image Controller是从CLIP copy过来的一个image encoder,和CLIP 的image encoder之间用全连接相连,全连接初始化为0(Adding conditional control to text-to-image diffusion models),对CLIP image encoder的影响是通过残差的方式,直接加到每一层上面去:
- train这个模型用的是对比损失,需要的数据集是LQ图片,对应每张LQ图片需要有两个text,一个是对LQ图片内容的clean描述,即描述中不包含degradation,一个是degradation的描述,损失如下。其实就是对controller的两个输出分别算损失,degradation prompt的输出要和degradation的描述提取的text feature计算对比损失,controller控制到的image encoder的输出要和clean的描述提取的text feature计算对比损失:

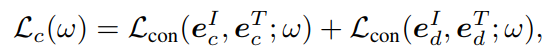
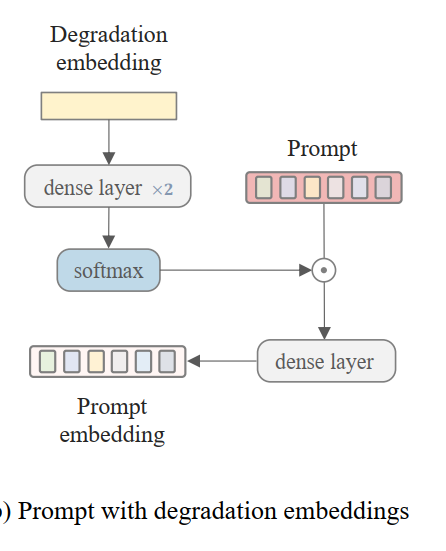
- train完这个模块,只需要把从LQ上提取到的图像特征和text特征注入到diffusion的网络中作为输入之一,在包括多种degradation的成对数据集上train这个diffusion网络即可,注入的方法和使用的网络都是现有的工作(包括用作diffusion模型的IR-SDE(Image restoration with mean-reverting stochastic differential equations),用了这个工作的cross attention(High-resolution image synthesis with latent diffusion models)),文章就没有仔细介绍。text特征在注入前用了prompt learning(Learning to prompt for visionlanguage models)的方式,加了个模块才注入:
实验结果
- 首先确实是有效的,从两点可以证明,一点是相比没有加DA-CLIP的baseline模型,性能是提高了的。第二点是相比直接用原来的CLIP提取的特征进行cross attention,用DA-CLIP提取的特征进行cross attention效果更好(没有加degradation prompt)。文章其实做了非常非常多的实验,感兴趣可以自己去论文中看,直观感受是虽然通用性是提高了,但是每个任务上的性能其实并不是很高,从Figure8就可以看出来无论是inpainting还是denoising,效果都并不是很好。
- 此外,我比较好奇的是,这样一种unified image restoration的思路,能不能在训练完后,对混合视觉增强,即一张图上同时有多种degradation,来实现restoration呢。从附录本文给的LIMITATION可以看到,作者认为是不能的,证据是一张有阴影的雨图,模型只进行了去雨,没有把阴影去掉。说明prompt并没有混合degradation,而是体现了效应最明显的degradation。

















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









