







 文章提出了一种结合低光照增强和去模糊的LEDNet网络,解决了现有方法在处理低光照模糊图像时的问题。通过创建LOL-Blur数据集模拟黑暗环境的模糊和亮度低的情况,LEDNet在模拟和真实数据集上表现良好。数据模拟使用了修改后的Zero-DCE和高斯核来模拟模糊和噪声,网络结构包括PPM和CurveNLU模块,以有效处理混合模糊和噪声的图像。最终的损失函数结合了多个监督项,以优化去模糊和增强效果。
文章提出了一种结合低光照增强和去模糊的LEDNet网络,解决了现有方法在处理低光照模糊图像时的问题。通过创建LOL-Blur数据集模拟黑暗环境的模糊和亮度低的情况,LEDNet在模拟和真实数据集上表现良好。数据模拟使用了修改后的Zero-DCE和高斯核来模拟模糊和噪声,网络结构包括PPM和CurveNLU模块,以有效处理混合模糊和噪声的图像。最终的损失函数结合了多个监督项,以优化去模糊和增强效果。

- 文章提出了一个数据模拟的pipeline。可以模拟黑暗环境下拍照产生的模糊和亮度低的情况,并用该方法生成了一个数据集 LOL-Blur,同时提出了一个低光照图像增强并去模糊的网络 LEDNet,能够在模拟数据集和真实图像数据集上都取得好的效果。
- 现有的方法都是单独处理 debluring 或 low-light enhancement的,如果简单地将现有模型串联起来起不到好的效果。现有 low light enhancement 的方法会导致亮度饱和的地方模糊化的效应被放大;并且先 low light enhancement 会导致用于 debluring 的细节线索丢失(主要是由于low light enhancement 中 denoising环节的平滑化);而现有的debluring的方法又是设计在白天的,直接用在低光照图片上效果并不好,用于deblur的线索在黑暗的照片上几乎不可见;并且由于低光照图片部分区域过曝导致的模糊和正常工作图片由于运动引发的模糊形成原理并不相同,原有的建模方法不适应该种模糊。
- 数据集的生成方式是这样的,用修改后的Zero-DCE对一段高帧率的视频序列进行调暗,然后对时序取窗口滑动平均以获得blur的效果。并且用高斯核来模拟失焦的模糊效果,并添加了噪声。
- 现有的模糊模型是这样的:
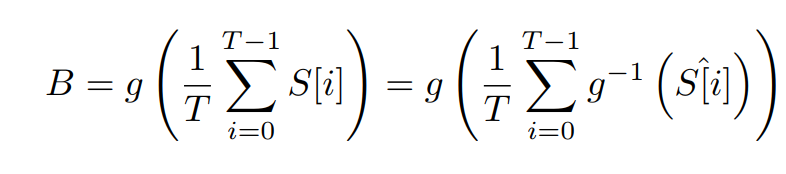
其中,g表示将相机元件记录的模拟量转为0-255的数字量的Gamma映射,其中 γ \gamma γ 值为2.2,所以中间的式子表示每帧的图片是模拟量在时间上窗口滑动平均得到的新的模拟量进行 gamma 映射的结果,设 S ^ [ i ] = g ( S [ i ] ) \hat S[i]=g(S[i]) S^[i]=g(S[i]),则可以得到右边的等式 - 然而上述式子并不能很好的建模由于亮度饱和导致的模糊效应,这些饱和值通常是被剪切为255的,即 S ^ [ i ] = C l i p ( g ( S [ i ] ) ) \hat S[i]=Clip(g(S[i])) S^[i]=Clip(g(S[i])),所以中间和右边的式子之间的等号就不成立了。
生成数据的pipeline
- 用相机记录200个高帧率(250fps)的视频,然后下采样并用VBM4D进行去噪。然后切成7或9个连续帧的片段,这些片段的中间帧作为GT
- 把这些片段用修改了的Zero-DCE进行调暗,修改方法是将loss函数中的亮度值约束改为想要的指定参数,因此根据不同参数进行训练可以获得了多个能够生成各种亮度的图片的Zero-DCE模型。
- 然后用一个模型把帧率插值为2000(8倍),以防止模糊的不连续
- 然后是对模糊效应的模拟,由于上面提到的饱和剪切效应,将公式修改为:
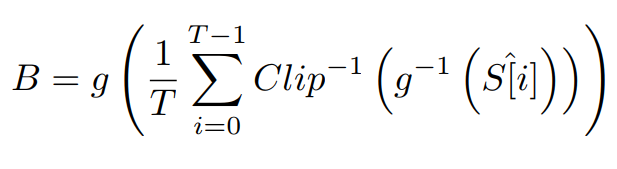
很明显剪切是不可逆的,因此这里的 C l i p − 1 ( ⋅ ) Clip^{-1}(·) Clip−1(⋅)表示的是一个近似函数,当s饱和时, C l i p − 1 ( s ) = s + r Clip^{-1}(s)=s+r Clip−1(s)=s+r,否则等于s,其中r是[20,100]的随机数。而判断饱和的依据是在Lab彩色空间中的L(0到100)大于98. - 取平均的对象是每个插帧后的片段,也即 7 × 8 7\times8 7×8 或 9 × 8 9\times8 9×8 的连续帧
- 最后是用高斯核加失焦模糊和用CycleISP加噪声。
LEDNet
-
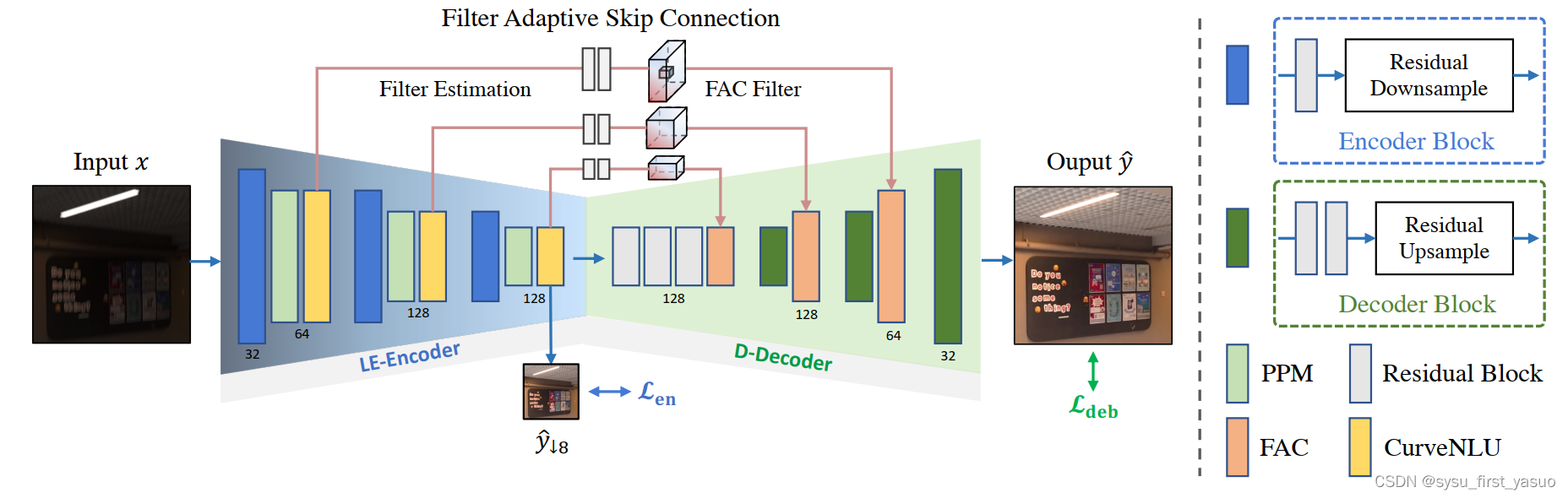
网络结构如下图所示:
-
PPM模块在这个工作中能够很好地消除由于模糊和噪声同时存在带来的纹理
-
CurveNLU模块则是参考了Zero-DCE的公式:
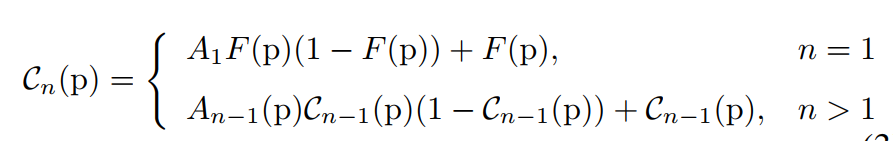
其中 A n A_n An 是用网络预测的 pixel-wise 的参数,整体可视化出来是这样的结构:
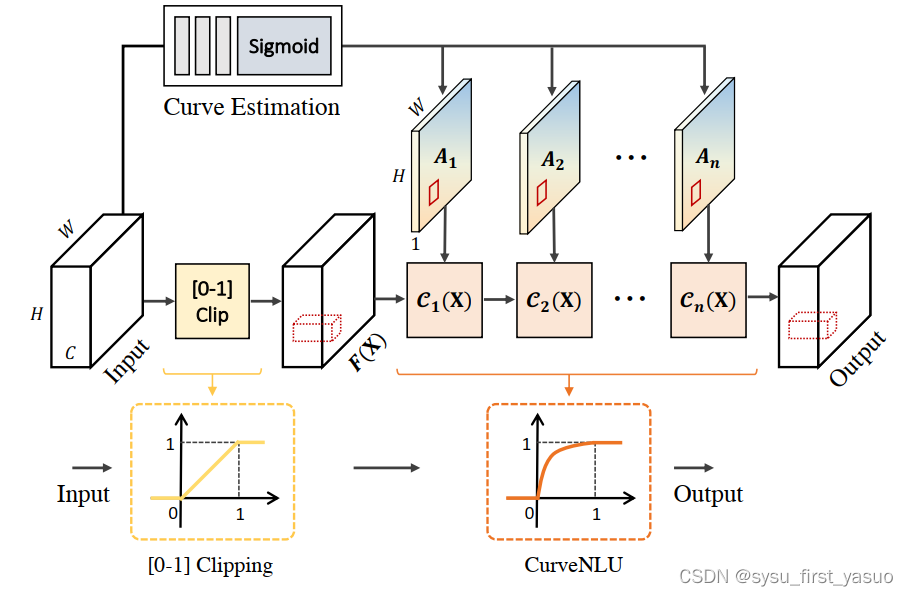
-
与Zero-DCE不同的是,对于不同的通道,采用的是相同的参数。
-
然后是FASC模块和FAC模块,先用3个3x3和一个1x1卷积层从encoder的特征图中提取 K ∈ R H × W × C d 2 K\in \mathbb R^{H\times W\times Cd^2} K∈RH×W×Cd2,也就是说对于decoder中同尺度的特征图( H × W × C H\times W\times C H×W×C),特征图上的每个元素有一个专门的 d × d d\times d d×d的卷积核,这也就是decoder中的FAC模块。本文将d设为5.
Loss 函数
- 用GT下采样8倍来监督encoder的输出:
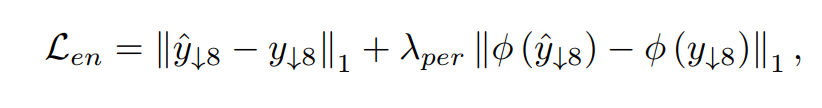
其中 ϕ ( ⋅ ) \phi(·) ϕ(⋅)表示用VGG19提取多尺度的特征。 - 对最后的输出也是做debluring的监督
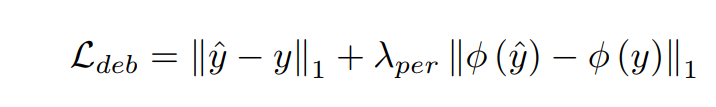
- 因此最终的loss函数是:

其中 λ p e r \lambda_{per} λper, λ e n \lambda_{en} λen, λ d e b \lambda_{deb} λdeb分别为0.01,0.8和1
待阅读论文
- Zero-DCE++
- 失焦加的高斯模糊核(Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-ESRGAN: Training real-world blind super-resolution with pure synthetic data. In ICCVW, 2021. 2, 4, 14)
- 加噪的CycleISP
- FAC的论文(Shangchen Zhou, Jiawei Zhang, Jinshan Pan, Haozhe Xie, Wangmeng Zuo, and Jimmy Ren. Spatio-temporal filter adaptive network for video deblurring. In ICCV, 2019. 2, 3, 6)

















 2132
2132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









