







面试技术栈 —— 2024网易雷火暑期实习真题
1. 最长递增子序列。
题目链接:最长递增子序列 - leetcode
题目描述:
给你一个整数数组nums,找到其中最长严格递增子序列的长度。子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7]是数组[0,3,1,6,2,2,7]的子序列。
解题思路:
解法: 最长递增子序列 - leetcode官方题解
class Solution:
def lengthOfLIS(self, nums: List[int]) -> int:
n = len(nums)
if n == 0:
return 0
dp = [0] * n
dp[0] = 1
ans = 1
for i in range(1,n):
dp[i] = 1
for j in range(0,i):
if nums[j] < nums[i]:
dp[i] = max(dp[i], dp[j]+1)
ans = max(ans, dp[i])
return ans
2. 集中限流和单机限流你觉得哪个好?
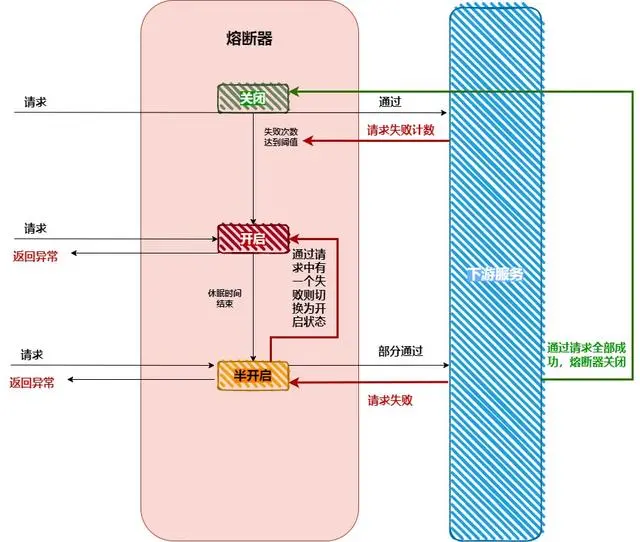
在微服务架构中,集中限流和单机限流是两种常见的限流策略,它们用于控制服务的访问频率,以防止系统过载。
集中限流,也称为分布式限流,是一种服务级的限流策略。它限制对整个微服务集群的访问频率,而不是针对集群中的单个实例。例如,它可以限制特定的调用方,每分钟最多请求多少次某个服务。这种策略允许不同的调用方对不同的接口执行不同的限流规则,因此更适合进行细粒度限流或访问配额管理。集中限流既可以使用单机限流算法,也可以使用分布式限流算法。
单机限流则是一种更细粒度的限流策略,它独立地对集群中的每台实例进行接口限流。例如,它可以限制每台实例接口访问的频率为最大1000次/秒。这种策略的主要目的是防止突发流量压垮单个服务器,因此更适合针对并发进行限制。单机限流一般使用单机限流算法。
从保证系统可用性的角度来看,单机限流更具优势,因为它可以防止个别实例因过高的流量而崩溃。然而,从防止某个调用方过度竞争服务资源的角度来看,集中限流更加适合,因为它可以对不同的调用方实施不同的限流规则。
在实际应用中,可以根据具体的需求和场景选择适当的限流策略。例如,如果API网关是单实例部署,那么使用单机限流算法可能更为合适。
| 参考文章或视频链接 |
|---|
| [1] 《今天一定要搞清楚限流、熔断和降级》 |
| [2] 《10张图带你彻底搞懂限流、熔断、服务降级》 |
| [3] 如何理解微服务中的服务熔断、降级、限流? - bilibili |
| [4] Set Requests and Limits of a Microservice |
| [5] MicroService Patterns: Rate Limiting with Spring Boot |
3. redis部署服务器配置,为什么不用哨兵?
一般来说,Redis是不需要哨兵服务的。Redis本身支持多实例,只要在多服务器上跑一个Redis实例就可以支持客户端跨节点访问,不需要哨兵服务的支持。
| 参考文章或视频链接 |
|---|
| [1] 讲的很好 【趣话Redis第三弹】Redis的高可用是怎么实现的?哨兵是什么原理? |
| [2] 本问题答案 Redis是否需要哨兵服务(redis 需要哨兵吗) |
4. 讲讲分布式session的原理。
分布式Session是指将用户会话数据存储在多个服务器上,以实现负载均衡和高可用性。在传统的单服务器会话管理中,Session数据通常只存储在一个服务器上,这会导致单点故障和性能瓶颈的问题。而分布式Session通过将会话数据分布到多个服务器上,可以有效地解决这些问题。
分布式Session的原理通常涉及以下几个方面:
- 会话数据存储:分布式Session通常使用分布式缓存或数据库来存储会话数据。常见的分布式缓存包括Redis、Memcached等。这些缓存服务器可以在多个节点之间进行数据同步和备份,保证数据的高可用性和一致性。
- 会话数据共享:为了保证不同服务器之间的会话数据共享,可以采用一些技术手段,如Session复制、Session共享和基于缓存的Session共享等。其中,Session复制是指将Session数据复制到多个服务器上,以保证数据的一致性;Session共享是指多个服务器共享同一个Session数据,可以通过负载均衡器将用户的请求分发到任意一个服务器上;基于缓存的Session共享则是将会话数据存储在缓存服务器中,各个服务器通过缓存服务器来获取和更新Session数据。
- 会话数据路由:为了保证用户的请求能够正确地路由到存储了其Session数据的服务器上,可以采用一些路由算法,如基于Hash的路由算法、基于一致性Hash的路由算法等。这些算法可以根据用户的IP地址、请求参数等信息计算出应该路由到哪个服务器上,从而保证用户能够正确地获取到其Session数据。
- 通过分布式Session的实现,可以实现用户会话数据的高可用性和负载均衡,提高系统的性能和稳定性。同时,也需要注意数据的安全性和一致性,避免因为数据不一致或者数据丢失等问题导致用户体验的下降。
5. 数据库:表数据量大了,如何分表?
以MySQL为例,首先要知道MySQL的InnoDB引擎用的是B+树结构作为索引,数据量大,就会导致B+树的高度增加,磁盘I/O次数增加,这是查询变慢的根本原因。
- 水平分表:水平分表也称为数据分片,是将一个表中的记录分散到多个结构相同的表中。通常,这些表会存在于不同的物理存储中。水平分表可以通过多种方式进行,例如根据某个字段的哈希值、范围或列表进行分片。
- 垂直分表:垂直分表是将一个表中的列分散到多个不同的表中。这些表通常具有不同的结构,但它们之间通过某些字段进行关联。垂直分表可以帮助减少单个表的列数和复杂性,提高查询性能。
- 按照时间分表:对于包含时间戳的表,可以根据时间范围将数据分散到不同的表中。例如,每个月或每年创建一个新表,将对应时间范围内的数据存储在相应的表中。
- 按照哈希值分表:通过对某个字段进行哈希运算,将哈希值映射到不同的表中。这种方法可以确保数据在多个表之间均匀分布,提高查询性能。
- 按照范围分表:根据某个字段的值范围将数据分散到不同的表中。例如,根据用户ID的范围将用户数据分散到多个表中。
6. Raft选举的过程,raft选举平票咋办?
首先,节点有3个状态,级别由低到高分别为:Follower、Candidate、Leader。
其次,选举过程为,设置随机超时时间,先达到超时时间的Follower成为Candidate并任期加1,当该Candidate获得半数选票以上,则该节点成为Leader。
最后,若Candidate平票,由于在成为Candidate时会重置并随机选举超时时间,先到达选举超时的时间的就退出选举,这样就避免了平票。
| 参考文章或视频链接 |
|---|
| [1] 【码农Mark】Raft 分布式一致性算法的动画演示 - bilibili |
| [2] Raft分布式一致性算法原理(选举和同步) - 知乎 |
7. java轻量级锁的原理?
Java中的轻量级锁(Lightweight Locking)是一种基于CAS(Compare-And-Swap)操作的锁机制,也被称为自旋锁(Spinlock)。与重量级锁(如ReentrantLock)相比,轻量级锁在获取锁失败时不会使线程进入阻塞状态,而是让线程在一个循环中不断地尝试获取锁,直到成功为止。这种机制避免了线程切换的开销,因此被称为“轻量级”。
轻量级锁的实现通常涉及以下关键步骤:
获取锁:当一个线程尝试获取锁时,它会先检查锁是否已经被其他线程持有。如果锁未被持有,该线程会尝试使用CAS操作将锁的状态设置为已持有。如果CAS操作成功,则该线程获得锁并继续执行。
自旋:如果CAS操作失败(即锁已被其他线程持有),则该线程会进入一个自旋循环,不断检查锁的状态。在自旋循环中,线程会不断尝试使用CAS操作获取锁,直到成功为止。为了避免忙等待(busy-waiting)带来的性能问题,自旋循环通常会设置一个最大自旋次数或自旋超时时间。
等待与唤醒:如果自旋失败,或者自旋超过了设定的最大次数/超时时间,该线程会放弃获取锁,并可能进入等待队列。当持有锁的线程释放锁时,它会唤醒等待队列中的一个线程,使其有机会获取锁。
Java中的java.util.concurrent.locks.AbstractQueuedSynchronizer(AQS)是实现轻量级锁的核心框架。AQS通过内部状态(state)来表示锁的状态,并使用CAS操作来原子地更新状态。AQS还提供了等待队列(Wait Queue)和条件队列(Condition Queue)来支持线程间的同步。
使用轻量级锁时需要注意以下几点:
轻量级锁适用于竞争不激烈的情况,如果锁竞争激烈,可能导致大量线程自旋消耗CPU资源。
轻量级锁通常用于短期锁定,避免长时间持有锁导致其他线程长时间等待。
在使用轻量级锁时,应尽量避免死锁和活锁等并发问题。
总之,Java中的轻量级锁是一种基于CAS操作的锁机制,通过自旋和等待队列来实现线程间的同步。它在竞争不激烈的情况下具有较高的性能优势,但在竞争激烈时可能导致性能问题。因此,在使用轻量级锁时需要根据实际情况进行权衡和选择。
8. 轻量级锁线程队列太多了不会影响效率吗?
如果线程队列中的锁数量过多,线程之间的切换和调度仍然会消耗CPU资源。当线程数量很多时,这种切换和调度的开销可能会变得相当显著,从而降低系统的整体效率。
此外,过多的轻量级锁还可能导致死锁或活锁(一个线程不停自旋尝试获取锁就是活锁,活受罪)的情况,进一步降低系统的性能。
因此,在设计并发系统时,需要权衡线程的数量和锁的使用,避免过多地使用轻量级锁,以提高系统的整体效率。
9. 压测咋测的?
Jmeter软件压测,多组多线程压测。
10. redis持久化的原理?
Redis的持久化是其为了保证数据在故障或重启后不会丢失而设计的一种机制。具体来说,Redis提供了两种持久化方式:RDB(快照) 和 AOF(Append Only File,追加日志文件)日志。
RDB持久化:这种方式是通过生成数据快照来实现的。当满足一定条件时(如指定时间内的改动键的数量大于配置中的指定值),Redis会自动将内存中的所有数据快照存储到磁盘中。这个快照是内存数据的二进制序列化形式,存储上非常紧凑。RDB持久化是Redis的默认持久化方式。
AOF持久化:这种方式是通过记录每次对服务器写的操作来实现的。当服务器重启时,会重新执行这些命令来恢复原始的数据。AOF日志记录的是内存数据修改的指令记录文本。由于AOF日志在长期的运行过程中会变得很大,所以在数据库重启时需要加载AOF日志进行指令重放,这可能会需要很长时间。因此,需要定期进行AOF重写,给AOF日志进行瘦身。
11. 短链生成的原理,短链会重复吗?
短链生成通常是通过一定的算法将长链接转换为短链接,以便于分享和传播。这个过程与Redis持久化的机制无关。
至于是否会重复,这主要取决于短链生成的算法和设计。如果短链生成算法设计得当,那么生成的短链应该是唯一的,不会重复。然而,如果短链生成算法存在缺陷或者设计不当,那么就有可能出现短链重复的情况。这与Redis持久化无关,是短链生成算法自身的问题。
| 参考文章或视频链接 |
|---|
| [1] Java——JDK动态代理 |
| [2] 【java常问面试题】场景面试题:如何设计一个短链系统?- bilibili |
| [3] 短链接是怎么设计的?带你入门 - CSDN |
12. 动态代理的几种方式区别?
JDK原生动态代理:
- (1)该类需要实现一个接口。
- (2)通过
Proxy.newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)静态方法进行代理。 - (3)其中
InvocationHandler h需要实现一个invoke(Object proxy, Method method, Object[] args)钩子方法,具体的代理逻辑就在这个invoke中。
| 参考文章或视频链接 |
|---|
| [1] Java——JDK动态代理 |
13. Redis的内存模型?
| 参考文章或视频链接 |
|---|
| [1] 深度学习Redis(1):Redis内存模型 |
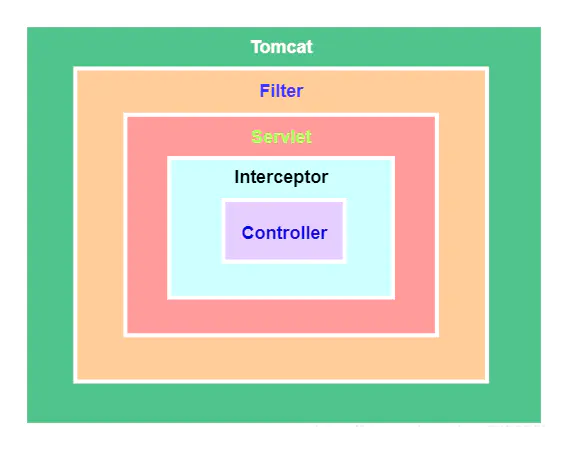
14.过滤器和拦截器的区别?
过滤器和拦截器都是用于处理应用程序中的请求和响应的组件,但它们在实现方式、使用场景和功能上存在一些区别。
实现方式:过滤器(Filter)是基于Servlet规范实现的,依赖于Servlet容器,而拦截器(Interceptor)是基于Java反射机制实现的,不依赖于Servlet容器。因此,过滤器是Servlet规范的一部分,而拦截器是Spring框架提供的功能。
使用场景:过滤器通常用于处理所有进入容器的请求和响应,包括静态资源和动态请求。而拦截器通常用于处理Spring框架中的Action请求,主要对业务逻辑层进行拦截。
功能:过滤器主要用于执行一些预处理和后处理任务,例如身份验证、日志记录、字符集设置等。而拦截器不仅可以执行类似的任务,还可以访问Action上下文、值栈中的对象,并且可以获取IOC容器中的各个bean,执行一些业务逻辑。
综上所述,过滤器和拦截器在实现方式、使用场景和功能上存在一定的区别。过滤器主要基于Servlet规范实现,用于处理所有进入容器的请求和响应,主要执行一些预处理和后处理任务;而拦截器基于Java反射机制实现,主要用于处理Spring框架中的Action请求,并可以执行更复杂的业务逻辑。

| 参考文章或视频链接 |
|---|
| [1] 【Spring学习】过滤器和拦截器 - 知乎 |
| [2] 拦截器和过滤器区别 - CSDN |
| [3] 16-拦截器interceptor实现登录校验 - bilibili |
15. @Controller与@RestController的区别?
功能:
@Controller注解用于标识一个类是Spring MVC的控制器处理器,它可以处理用户发送的请求并返回视图或模型数据。通常在使用@Controller注解时,方法返回的是一个视图名称或模板文件,如JSP、FTL、HTML等。
@RestController 注解是@Controller的一个特殊变体,它主要用于构建RESTful风格的Web服务。与@Controller不同,@RestController注解的方法返回的是数据,通常是以JSON、XML等形式进行输出,而不是视图。在默认情况下,@RestController注解下的方法返回的对象会被转换为JSON或XML格式的响应,并通过HTTP响应直接返回给客户端,而不进行视图解析。
使用:
在 @Controller 注解下,开发者通常需要手动配置视图解析器来将方法返回的字符串解析为相应的视图文件。例如,在Spring MVC中,开发者需要配置一个InternalResourceViewResolver来将返回的字符串解析为JSP文件。
在 @RestController 注解下,开发者无需手动配置视图解析器,因为返回的数据会被直接转换为JSON或XML格式的响应。这使得@RestController注解更适合用于构建RESTful风格的Web服务。
总之,@Controller和@RestController的主要区别在于它们的功能和使用方式。@Controller主要用于处理用户请求并返回视图,而@RestController则主要用于构建RESTful风格的Web服务并返回数据,因此后者@RestController更适合前后端分离。














 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









