







Java技术栈 —— 如何实现一个自己的DataX插件?
一、概要
DataX 是阿里云 DataWorks数据集成 的开源版本(可以理解为DataWorks的阉割版),实现一个自己的DataX插件可以有助于各种异构数据源的导入导出,从业务角度与提升自己的技术视野两个方面来说,实现一款自己的DataX插件是很有必要的一件事。
二、实现流程与技术细节
2.1 认识DataX
DataX采用FrameWork+plugin的方式,插件只需关心数据的读取或者写入本身,而同步的共性问题,比如:类型转换、性能、统计,则交由框架来处理。[3]
Job是DataX数据同步的最小业务单元
Task是DataX数据同步的最小执行单元,相当于对Job的拆分
| 参考文章或视频链接 |
|---|
| [1] 《如何开发一个自己的datax插件》 |
| [2] DataX - Github |
| [3] 官方文档重点参考 DataX插件开发宝典 - Github |
| [4] 系列文章值得一看 DataX学习指南(一)–基础介绍 |
| [5] 打包报错,Maven版本不可过高,我使用的是3.6.3 Could not find goal ‘assembly‘ in plugin org.apache.maven.plugins:maven-assembly-plugin: among avai |
| [6] 《DataX与Kettle,深度对比分析》 - 51CTO |
2.2 运行DataX
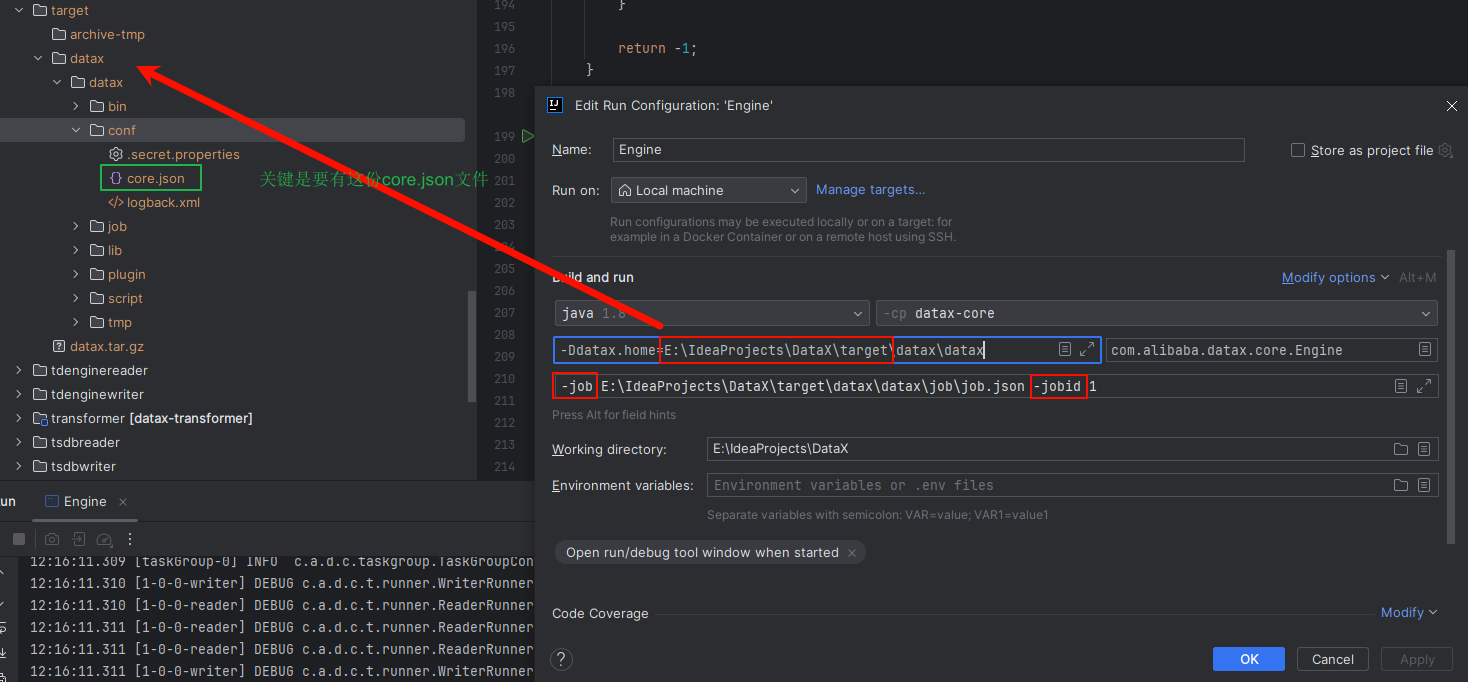
对参考文章3的纠正,的确可以用IDEA把DataX运行起来,但datax.home有讲究,运行Engine.java传入的参数方式也有说法,你配置的datax.home,一定要有conf目录及其下的core.json文件
# -jobid你自己填,总之不要是-1
-job E:\IdeaProjects\DataX\target\datax\datax\job\job.json -jobid 1
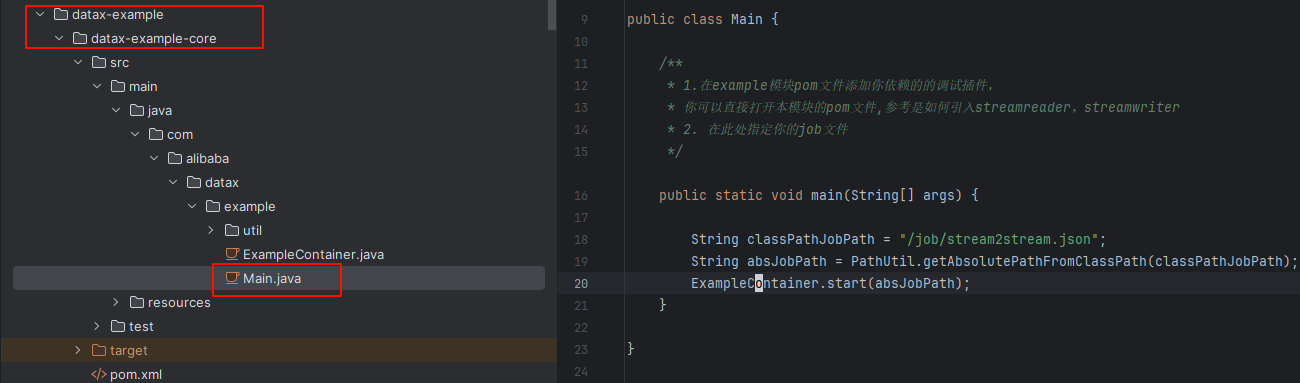
其实关于DataX在IDEA中的调用,datax-example项目里有写,所以并不像参考文章三说的那样,官方没有IDEA运行的示例文档,只是写在了代码中,不过这一点确实容易误导开发者,可说到底,python datax.py也只是一种用python调度java程序运行的方式,一个java项目,不可能存在IDEA运行不起来的情况。
| 参考文章或视频链接 |
|---|
| [1] 《DataX学习指南(四)-- 项目运行》 |
| [2] 《如何开发一个自己的datax插件》 |
| [3] 《DataX教程(02)- IDEA运行DataX完整流程(填完所有的坑)》 |
2.3 开发DataX的JSONReader插件
读取JSON文件里的数据至数据库中
该插件在windows下运行有转义符问题
@Override
public void prepare() {
LOG.debug("prepare() begin...");
// warn:make sure this regex string
// warn:no need trim
for (String eachPath : this.path) {
// String regexString = eachPath.replace("*", ".*").replace("?",".?"); //原代码
String regexString = eachPath.replace("\\","\\\\")
.replace("*", ".*")
.replace("?",".?"); //修改后代码
Pattern patt = Pattern.compile(regexString);
this.pattern.put(eachPath, patt);
this.sourceFiles = this.buildSourceTargets();
}
LOG.info(String.format("您即将读取的文件数为: [%s]", this.sourceFiles.size()));
}
且json数据的文件,一个json体必须写成单独一行,不能有换行的存在,否则会读取文件末尾失败,认为这不是一个正规的json数据体,对于该项目来说,当存在多个json体时,你必须这样写才能把所有数据读入,jsonfilereader
{"a":"asdf", "b":"bsdf", "c":"csdf"},
{"a":"asdf1", "b":"bsdf1", "c":"csdf1"},
{"a":"asdf2", "b":"bsdf2", "c":"csdf2"},
{"a":"asdf3", "b":"bsdf3", "c":"csdf3"},
| 2.3 参考文章或视频链接 |
|---|
| [1] 《增加对json文件格式读取的插件》- Github |
2.4 给DataX新增Column数据类型
| 2.4 参考文章或视频链接 |
|---|
| [1] 《datax值转换使用以及源码分析》- CSDN |
2.5 使用DataX的Transformer
| 2.5 参考文章或视频链接 |
|---|
| [1] 《DataX-自定义Transformer的使用和扩展以及运行参数调优》 |
三、技术名词解释
3.1 Assembly打包
DataX使用assembly打包,assembly的使用方法,什么是assembly打包?
assembly 是 Maven 提供的一种插件,用于将项目构建成一个可分发的压缩包,这个压缩包中包含了项目的所有依赖项、源代码、文档等,方便用户直接使用或部署。
具体来说,assembly 插件允许你定义一个打包描述文件(通常命名为 assembly.xml 或者 package.xml),在这个描述文件中,你可以指定哪些文件和目录需要被包含在最终的打包结果中,以及它们的组织方式。例如,你可以指定项目的依赖 JAR 文件被放置在一个特定的目录下,或者将某些配置文件放在压缩包的根目录等。
assembly 插件非常灵活,它支持多种打包格式,包括但不限于 ZIP、TAR、JAR 等。通过使用 assembly 插件,你可以定制化你的发布包,确保用户或者部署者能够获得一个完整的、可执行的应用程序或服务。
在 DataX 的背景下,assembly 打包可能用于将 DataX 的插件(如 neo4jwriter)打包成一个独立的分发包,其中包含了插件的代码、依赖库、配置文件等,这样用户可以方便地将插件部署到 DataX 环境中。
| 三、参考文章或视频链接 |
|---|
| [1] 《maven 使用assembly 进行打包》 |
| [2] 《Maven Assembly插件介绍》 |
四、遇到的问题
4.1 package遇到的问题
打包DataX,我使用的是jdk1.8与maven3.6.3,并且与官方的-Dmaven.test.skip=true命令有区别,可能是maven版本不同造成的差异
#下面的两个命令都可以,推荐后面那个
mvn -U clean package assembly:assembly -DskipTests
mvn -U clean package assembly:assembly "-Dmaven.test.skip=true"
| 4.1 参考文章或视频链接 |
|---|
| [1] 《DataX源码编译遇到的坑》 |
| [2] DataX源码编译时报错 - Github |
| [3] Maven error “Unknown lifecycle phase “.test.skip=true”…” - StackOverflow |
DataX的插件所需的配置文件,其内部的配置项支持扩展吗?
五、小结
| 五、 参考文章或视频链接 |
|---|
| [1] 阿里云开发者社区 |















 4054
4054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









