









学习记录
(一)激活函数
1. 什么是激活函数
在神经网络中,我们经常可以看到对于某一个隐藏层的节点,该节点的激活值计算一般分为两步:
(1)输入该节点的值为 x1,x2时,在进入这个隐藏节点后,会先进行一个线性变换,计算出值
z
[
1
]
=
w
1
x
1
+
w
2
x
2
+
b
[
1
]
=
W
[
1
]
x
+
b
[
1
]
z^{[1]} = w_1 x_1 + w_2 x_2 + b^{[1]} = W^{[1]} x + b^{[1]}
z[1]=w1x1+w2x2+b[1]=W[1]x+b[1],上标 1 表示第 1 层隐藏层。
(2)再进行一个非线性变换,也就是经过非线性激活函数,计算出该节点的输出值(激活值) a(1)=g(z(1)) ,其中 g(z)为非线性函数。
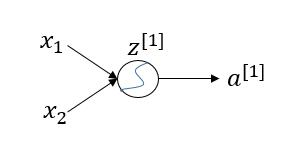
2. 常用的激活函数
在深度学习中,常用的激活函数主要有:sigmoid函数,tanh函数,ReLU函数。下面 一一介绍。
2.1 sigmoid函数
在逻辑回归中我们介绍过sigmoid函数,该函数是将取值为 (−∞,+∞)
的数映射到 (0,1)
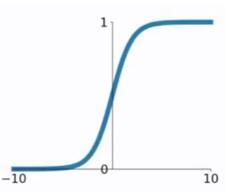
之间。sigmoid函数的公式以及图形如下:
g ( z ) = 1 1 + e − z g(z) = \frac{1}{1+e^{-z}} g(z)=1+e−z1
对于sigmoid函数的求导推导为:
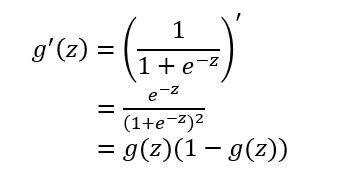
sigmoid函数作为非线性激活函数,但是其并不被经常使用,它具有以下几个缺点:
(1)当 z值非常大或者非常小时,通过上图我们可以看到,sigmoid函数的导数 g′(z) 将接近 0 。这会导致权重 W 的梯度将接近 0,使得梯度更新十分缓慢,即梯度消失。下面我们举例来说明一下,假设我们使用如下一个只有一层隐藏层的简单网络:
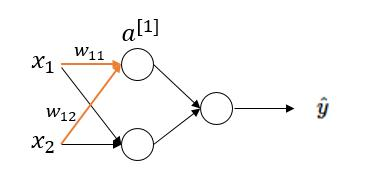
对于隐藏层第一个节点进行计算,假设该点实际值为 a,激活值为 a[1] 。于是在这个节点处的代价函数为(以一个样本为例):
J
[
1
]
(
W
)
=
1
2
(
a
[
1
]
−
a
)
2
J^{[1]}(W) = \frac{1}{2} (a{[1]}-a)2
J[1](W)=21(a[1]−a)2
而激活值
a
[
1
]
a^{[1]}
a[1]的计算过程为:
z [ 1 ] = w 11 x 1 + w 12 x 2 + b [ 1 ] z^{[1]} = w_{11}x_1 + w_{12}x_2 + b^{[1]} z[1]=w11x1+w12x2+b[1]
a [ 1 ] = g ( z [ 1 ] ) a^{[1]} = g(z^{[1]}) a[1]=g(z[1])
于是对权重 w 11 w_{11} w11求梯度为:
Δ
J
[
1
]
(
W
)
Δ
w
11
=
(
a
[
1
]
−
a
)
⋅
(
a
[
1
]
)
′
=
(
a
[
1
]
−
a
)
⋅
g
′
(
z
[
1
]
)
⋅
x
1
\frac{\Delta J^{[1]}(W)}{\Delta w_{11}} = (a^{[1]} - a) \cdot (a^{[1]})' = (a^{[1]} - a) \cdot g'(z^{[1]}) \cdot x_1
Δw11ΔJ[1](W)=(a[1]−a)⋅(a[1])′=(a[1]−a)⋅g′(z[1])⋅x1
由于
g
′
(
z
[
1
]
)
=
g
(
z
[
1
]
)
(
1
−
g
(
z
[
1
]
)
)
,
当
z
[
1
]
g'(z^{[1]}) =g(z{[1]})(1-g(z{[1]})) ,当z^{[1]}
g′(z[1])=g(z[1])(1−g(z[1])),当z[1] 非常大时,
g
(
z
[
1
]
)
≈
1
,
1
−
g
(
z
[
1
]
)
≈
0
g(z^{[1]}) \approx 1 ,1-g(z^{[1]}) \approx 0
g(z[1])≈1,1−g(z[1])≈0因此,
g
′
(
z
[
1
]
)
≈
0
,
Δ
J
[
1
]
(
W
)
Δ
w
11
≈
0
g'(z^{[1]}) \approx 0 , \frac{\Delta J^{[1]}(W)}{\Delta w_{11}} \approx 0
g′(z[1])≈0,Δw11ΔJ[1](W)≈0。当
z
[
1
]
z^{[1]}
z[1] 非常小时,
g
(
z
[
1
]
)
≈
0
g(z^{[1]}) \approx 0
g(z[1])≈0,亦同理。(本文只从一个隐藏节点推导,读者可从网络的输出开始,利用反向传播推导)
(2)函数的输出不是以0为均值,将不便于下层的计算 。
sigmoid函数可用在网络最后一层,作为输出层进行二分类,尽量不要使用在隐藏层。
2.2 tanh函数
tanh函数相较于sigmoid函数要常见一些,该函数是将取值为 (−∞,+∞)
的数映射到 (−1,1)之间,其公式与图形为:
g
(
z
)
=
e
z
−
e
−
z
e
z
+
e
−
z
g(z) = \frac{e^z-e^{-z}}{e^z+e^{-z}}
g(z)=ez+e−zez−e−z
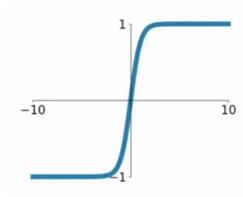
tanh函数在 0附近很短一段区域内可看做线性的。由于tanh函数均值为 0 ,因此弥补了sigmoid函数均值为 0.5的缺点。
对于tanh函数的求导推导为:
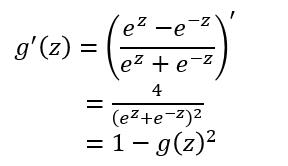
tanh函数的缺点同sigmoid函数的第一个缺点一样,当 z很大或很小时, g ′ ( z ) g'(z) g′(z) 接近于 0
,会导致梯度很小,权重更新非常缓慢,即梯度消失问题。
2.3 ReLU函数
ReLU函数又称为修正线性单元(Rectified Linear Unit),是一种分段线性函数,其弥补了sigmoid函数以及tanh函数的梯度消失问题。ReLU函数的公式以及图形如下:
g ( z ) = { z , if z > 0 0 , if z < 0 g(z)= \begin{cases} z, & \text {if $z>0$ } \\ 0, & \text{if $z<0$} \end{cases} g(z)={z,0,if z>0 if z<0
对于ReLU函数的求导为:
g ′ ( z ) = { 1 , if z > 0 0 , if z < 0 g'(z)= \begin{cases} 1, & \text {if $z>0$ } \\ 0, & \text{if $z<0$} \end{cases} g′(z)={1,0,if z>0 if z<0
ReLU函数的优点:
(1)在输入为正数的时候(对于大多数输入 z空间来说),不存在梯度消失问题。
(2) 计算速度要快很多。ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多。(sigmod和tanh要计算指数,计算速度会比较慢)
ReLU函数的缺点:
(1)当输入为负时,梯度为0,会产生梯度消失问题。
2.4 Leaky ReLU函数
这是一种对ReLU函数改进的函数,又称为PReLU函数,但其并不常用。其公式与图形如下:
g
(
z
)
=
{
z
,
if
z
>
0
a
z
,
if
z
<
0
g(z)= \begin{cases} z, & \text {if $z>0$ } \\ az, & \text{if $z<0$} \end{cases}
g(z)={z,az,if z>0 if z<0
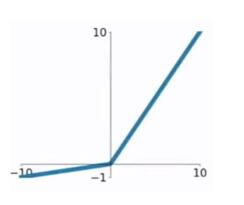
其中 a取值在 (0,1)之间。
Leaky ReLU函数的导数为:
g ( z ) = { 1 , if z > 0 a , if z < 0 g(z)= \begin{cases} 1, & \text {if $z>0$ } \\ a, & \text{if $z<0$} \end{cases} g(z)={1,a,if z>0 if z<0
Leaky ReLU函数解决了ReLU函数在输入为负的情况下产生的梯度消失问题。
3. 为什么要用非线性激活函数?
以这样一个例子进行理解。
假设下图中的隐藏层使用的为线性激活函数(恒等激活函数),也就是说 g(z)=z。

于是可以得出:
z [ 1 ] = W [ 1 ] x + b [ 1 ] z^{[1]} = W^{[1]}x+b^{[1]} z[1]=W[1]x+b[1]
a [ 1 ] = g ( z [ 1 ] ) = z [ 1 ] a^{[1]} = g(z^{[1]}) = z^{[1]} a[1]=g(z[1])=z[1]
z
[
2
]
=
W
[
2
]
a
[
1
]
+
b
[
2
]
=
W
[
2
]
(
W
[
1
]
x
+
b
[
1
]
)
+
b
[
2
]
z^{[2]} = W^{[2]} a^{[1]} + b^{[2]} = W^{[2]} (W^{[1]}x+b^{[1]}) + b^{[2]}
z[2]=W[2]a[1]+b[2]=W[2](W[1]x+b[1])+b[2]
a
[
2
]
=
g
(
z
[
2
]
)
=
z
[
2
]
=
W
[
2
]
(
W
[
1
]
x
+
b
[
1
]
)
+
b
[
2
]
=
W
[
1
]
W
[
2
]
x
+
W
[
2
]
b
[
1
]
+
b
[
2
]
a^{[2]} = g(z^{[2]}) = z^{[2]} = W^{[2]} (W^{[1]}x+b^{[1]}) + b^{[2]} = W^{[1]}W^{[2]} x + W^{[2]}b^{[1]} +b^{[2]}
a[2]=g(z[2])=z[2]=W[2](W[1]x+b[1])+b[2]=W[1]W[2]x+W[2]b[1]+b[2]
y ^ = a [ 2 ] = W [ 1 ] W [ 2 ] x + W [ 2 ] b [ 1 ] + b [ 2 ] \hat{y} = a^{[2]} = W^{[1]}W^{[2]} x + W^{[2]}b^{[1]} +b^{[2]} y^=a[2]=W[1]W[2]x+W[2]b[1]+b[2]
可以看出,当激活函数为线性激活函数时,输出 y ^ \hat{y} y^不过是输入特征 x 的线性组合(无论多少层),而不使用神经网络也可以构建这样的线性组合。而当激活函数为非线性激活函数时,通过神经网络的不断加深,可以构建出各种有趣的函数。
(二)损失函数
1. 损失函数、代价函数与目标函数
- 损失函数(Loss Function):是定义在单个样本上的,是指一个样本的误差。
- 代价函数(Cost Function):是定义在整个训练集上的,是所有样本误差的平均,也就是所有损失函数值的平均。
- 目标函数(Object Function):是指最终需要优化的函数,一般来说是经验风险+结构风险,也就是(代价函数+正则化项)。
2. 常用的损失函数
(1)0-1损失函数(0-1 loss function)
L ( y , f ( x ) ) = { 1 , y ≠ f ( x ) 0 , y = f ( x ) L(y, f(x)) = \begin{cases} 1, & {y \neq f(x) } \\ 0, & {y = f(x)} \end{cases} L(y,f(x))={1,0,y=f(x)y=f(x)
也就是说,当预测错误时,损失函数为1,当预测正确时,损失函数值为0。该损失函数不考虑预测值和真实值的误差程度。只要错误,就是1。
(2)平方损失函数(quadratic loss function)
L ( y , f ( x ) ) = ( y − f ( x ) ) 2 L(y, f(x)) = (y - f(x))^2 L(y,f(x))=(y−f(x))2
是指预测值与实际值差的平方。
(3)绝对值损失函数(absolute loss function)
L ( y , f ( x ) ) = ∣ y − f ( x ) ∣ L(y, f(x)) = | y -f(x) | L(y,f(x))=∣y−f(x)∣
该损失函数的意义和上面差不多,只不过是取了绝对值而不是求绝对值,差距不会被平方放大。
(4)对数损失函数(logarithmic loss function)
L ( y , p ( y ∣ x ) ) = − log p ( y ∣ x ) L(y, p(y|x)) = - \log p(y|x) L(y,p(y∣x))=−logp(y∣x)
这个损失函数就比较难理解了。事实上,该损失函数用到了极大似然估计的思想。P(Y|X)通俗的解释就是:在当前模型的基础上,对于样本X,其预测值为Y,也就是预测正确的概率。由于概率之间的同时满足需要使用乘法,为了将其转化为加法,我们将其取对数。最后由于是损失函数,所以预测正确的概率越高,其损失值应该是越小,因此再加个负号取个反。
(5)Hinge loss
Hinge loss一般分类算法中的损失函数,尤其是SVM,其定义为:
L ( w , b ) = m a x { 0 , 1 − y f ( x ) } L(w,b) = max \{0, 1-yf(x) \} L(w,b)=max{0,1−yf(x)}
其中 y=+1或y=−1,f(x)=wx+b,当为SVM的线性核时。
3. 常用的代价函数
(1)均方误差(Mean Squared Error)
M S E = 1 N ∑ i = 1 N ( y ( i ) − f ( x ( i ) ) ) 2 MSE = \frac{1}{N} \sum_{i=1}^N (y^{(i)} - f(x^{(i)}))^2 MSE=N1i=1∑N(y(i)−f(x(i)))2
均方误差是指参数估计值与参数真值之差平方的期望值; MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。( i表示第 i 个样本,N表示样本总数)
通常用来做回归问题的代价函数。
(2)均方根误差
R M S E = 1 N ∑ i = 1 N ( y ( i ) − f ( x ( i ) ) ) 2 RMSE = \sqrt{\frac{1}{N} \sum_{i=1}^N (y^{(i)} - f(x^{(i)}))^2 } RMSE=N1i=1∑N(y(i)−f(x(i)))2
均方根误差是均方误差的算术平方根,能够直观观测预测值与实际值的离散程度。
通常用来作为回归算法的性能指标。
(3)平均绝对误差(Mean Absolute Error)
M A E = 1 N ∑ i = 1 N ∣ y ( i ) − f ( x ( i ) ) ∣ MAE = \frac{1}{N} \sum_{i=1}^N |y^{(i)} - f(x^{(i)})| MAE=N1i=1∑N∣y(i)−f(x(i))∣
平均绝对误差是绝对误差的平均值 ,平均绝对误差能更好地反映预测值误差的实际情况。
通常用来作为回归算法的性能指标。
(4)交叉熵代价函数(Cross Entry)
H ( p , q ) = − ∑ i = 1 N p ( x ( i ) ) log q ( x ( − i ) ) H(p,q) = - \sum_{i=1}^{N} p(x^{(i)}) \log {q(x^{(-i)})} H(p,q)=−i=1∑Np(x(i))logq(x(−i))
交叉熵是用来评估当前训练得到的概率分布与真实分布的差异情况,减少交叉熵损失就是在提高模型的预测准确率。其中 p(x)
是指真实分布的概率, q(x) 是模型通过数据计算出来的概率估计。
比如对于二分类模型的交叉熵代价函数(可参考逻辑回归一节):
L
(
w
,
b
)
=
−
1
N
∑
i
=
1
N
(
y
(
i
)
log
f
(
x
(
i
)
)
+
(
1
−
y
(
i
)
)
log
(
1
−
f
(
x
(
i
)
)
)
)
L(w,b) = -\frac{1}{N} \sum_{i=1}^{N} (y^{(i)} \log {f(x^{(i)})} + ( 1- y^{(i)}) \log {(1- f(x^{(i)})}))
L(w,b)=−N1i=1∑N(y(i)logf(x(i))+(1−y(i))log(1−f(x(i))))
其中 f(x)可以是sigmoid函数。或深度学习中的其它激活函数。而 y(i)∈0,1 。
通常用做分类问题的代价函数。
(三)学习率
1. 什么是学习率(Learning rate)?
学习率(Learning rate)作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
这里以梯度下降为例,来观察一下不同的学习率对代价函数的收敛过程的影响(这里以代价函数为凸函数为例):
回顾一下梯度下降 :
θ
j
=
θ
j
−
α
Δ
J
(
θ
)
Δ
θ
j
\theta_j = \theta_j - \alpha \frac{\Delta J(\theta)}{\Delta \theta_j}
θj=θj−αΔθjΔJ(θ)
当学习率设置的过小时,收敛过程如下:
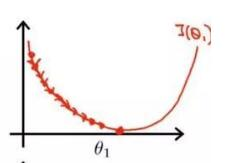
当学习率设置的过大时,收敛过程如下:
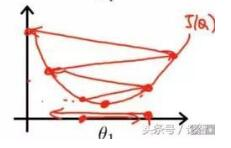
由上图可以看出来,当学习率设置的过小时,收敛过程将变得十分缓慢。而当学习率设置的过大时,梯度可能会在最小值附近来回震荡,甚至可能无法收敛。
我们再来看一下学习率对深度学习模型训练的影响:

可以由上图看出,固定学习率时,当到达收敛状态时,会在最优值附近一个较大的区域内摆动;而当随着迭代轮次的增加而减小学习率,会使得在收敛时,在最优值附近一个更小的区域内摆动。(之所以曲线震荡朝向最优值收敛,是因为在每一个mini-batch中都存在噪音)。
因此,选择一个合适的学习率,对于模型的训练将至关重要。下面来了解一些学习率调整的方法。
2. 学习率的调整
2.1 离散下降(discrete staircase)
对于深度学习来说,每 t轮学习,学习率减半。对于监督学习来说,初始设置一个较大的学习率,然后随着迭代次数的增加,减小学习率。
2.2 指数减缓(exponential decay)
对于深度学习来说,学习率按训练轮数增长指数差值递减。例如:
α = 0.9 5 e p o c h _ n u m ⋅ α 0 \alpha = 0.95^{epoch\_num} \cdot \alpha_0 α=0.95epoch_num⋅α0
又或者公式为:
α = k e p o c h _ n u m \alpha = \frac{k}{\sqrt {epoch\_num}} α=epoch_numk
其中epoch_num为当前epoch的迭代轮数。不过第二种方法会引入另一个超参 k。
2.3 分数减缓(1/t decay)
对于深度学习来说,学习率按照公式 α = α 1 + d e c a y r a t e ∗ e p o c h n u m \alpha = \frac{\alpha}{1+ {decay _ rate} * {epoch _ num}} α=1+decayrate∗epochnumα变化, decay_rate控制减缓幅度。















 1040
1040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









