









文章目录
前言:只是粗读,仅作记录用,大段都是全文翻译来的,挺不准确的,但大概意思是可以理解的,所以想精读文章的同学推荐读原文。
摘要
受ViT的影响,作者重新审视了CNN的大型核设计,并且指出是用少量大型核比使用很多小型核表现更好。作者共提出了五点方案,使用再参数化 (未知) 的大卷积核(31*31)提出了纯粹的CNN网络RepLKNet,代码和模型:https:
//github.com/megvii-research/RepLKNet
.
介绍
为什么ViTs超级强大?人们普遍认为,ViTs中 的多头自我注意(MHSA)机制起着关键作用。例如,之前 的研究表明,与卷积相比,MHSA具有更灵活的[50],能 够(更少的归纳偏差)[19],对失真[66,98]更鲁棒,能 够建模长期依赖[69,88],等等。然而,另一方面,最近 的一些研究挑战了MHSA[115]的必要性,将ViTs的高性能 归因于适当的构建块[32]、动态稀疏权值[38,110]等。
图1。ResNet-101/152和RepLKNet-13/31的有效接受野(ERF)。 暗区分布越广,表示ERF越大。更多的层。g.)在扩大erf方面收 效甚微。相反,我们的大型内核模型RepLKNet有效地获得了大 的erf。
在ViTs中,MHSA通常被设计为全局[33,75,93] 或局部[33,75,93],但具有较大的接受域[59,70,87](e 。g., ≥7×7),因此,来自单个MHSA层的每个输出都能 够从一个相对较大的区域收集信息。因此,然而,大型 内核在cnn中并不普遍使用(除了第一层[40])。相反, 一种典型的方式是使用许多小的空间卷积的堆栈 1[40,44,47, 68, 74, 79, 108] (e.g.,3×3)扩大最先 进的cnn的接受域。只有一些老式的网络,如AlexNet[53] 、灵感[76–78]和一些来自神经结构搜索[37,43,56,116] 的架构,采用大的空间卷积(其大小大于5)作为主要部 分。这一观察结果自然提出了一个问题:如果我们为传 统的cnn引入一些大内核而不是许多小内核会怎么样?大 的内核是弥合性能差距的关键吗?
我们的网络一般遵循Swin变压 器[59]的宏架构,只做了一些修改,同时用大的深度卷 积取代了多头自聚焦。我们主要对相对较大的模型进行 基准测试,因为ViTs过去被认为在大数据和模型上超过 了cnn。在ImageNet分类中,我们的基本结构的内核大小 高达31×31,仅在ImageNet-1K数据集上训练即可达到 84.8%的前1精度。
使用大卷积的指南
在深度卷积中使用大核
人们认为,大 核卷积在计算上是昂贵的,因为核的大小二次地增加了 参数和FLOPs的数量。通过应用深度级(DW)卷积[16,44] ,可以极大地克服这个缺点。例如,在我们提出的 RepLKNet中(详见表5),在从[3,3,3,3]到 [31,29,27,13]的不同阶段增加内核大小只会使FLOPs和 参数数量分别增加18.6%和10.4%,这是可以接受的。剩 下的1×1卷积实际上主导了大部分复杂度的工作。
简单说,深层网络的参数不太受某一层卷积核大小的影响
有人可能会担心,DW卷积在像gpu这样的现代并行计算 设备上可能非常低效。传统的DW3×3内核也是如此 [44,72, ,因为DW操作引入了较低的计算比率与。内存访问成本 为[64],这对现代计算架构并不友好。然而,我们发现 当内核大小变大时,计算密度会增加:例如,在 DW11×11内核中,每次我们从特征图中加载一个值时, 它最多可以参加121次乘法,而在3×3内核中,数字只有 9。因此,根据车顶线模型,当内核大小变大时,实际延 迟不应该比FLOPs的增加增加那么多。
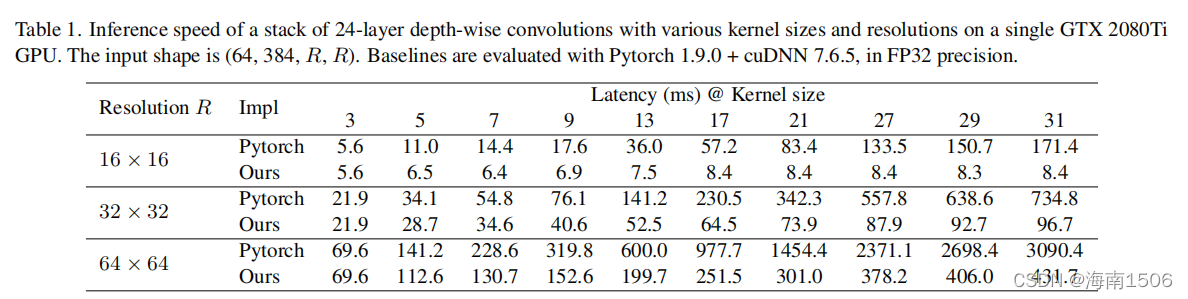
备注1。不幸的是,我们发现现成的深度学习工具(如 Pytorch)对大型DW卷积的支持很差,如表1所示。因此, 我们尝试了几种方法来优化CUDA内核。基于FFT的方法 [65]在实现大卷积方面似乎是合理的。然而,在实践中 ,我们发现的是块级的(逆的)implicit gemm算法是一种较好的选择。该实现已经集成到开 源框架MegEngine[1]中,我们在这里省略了细节。表1显 示,与Pytorch基线相比,我们的实现效率要高得多。通 过我们的优化,RepLKNet中DW卷积的延迟贡献从49.5%减 少到12.3%,这大致与FLOPs的占用成比例。
shotcut的使用
备注2。该指南也适用于ViTs。[32]最近的一项研究发现 ,如果没有身份捷径,注意力会随深度呈双指数下降, 导致过度平滑问题。虽然大核cnn可能以不同于ViT的机 制退化,但我们也观察到,如果没有捷径,网络很难捕 获局部细节。从与[89]类似的角度来看,快捷方式使模 型成为一个由许多具有不同接受域(RFs)的模型组成的隐 式集合,因此它可以从更大的最大射频中获益,而不会 失去捕获小规模模式的能力。
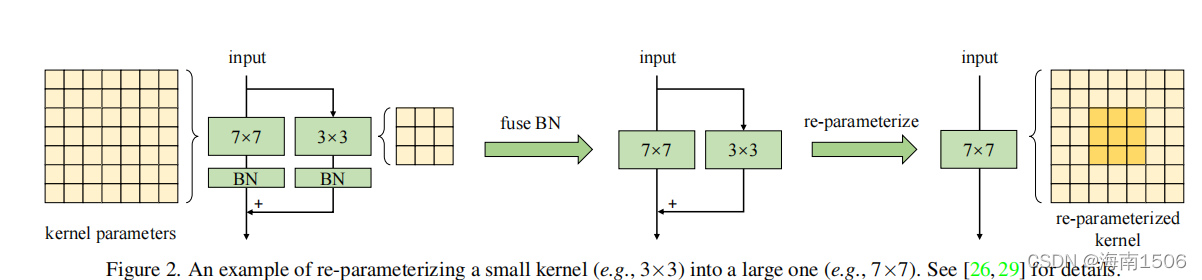
用小内核重新参数化[29]有助于弥补优化问题
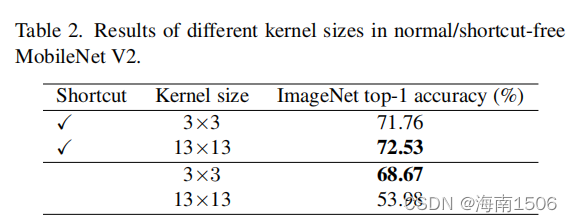
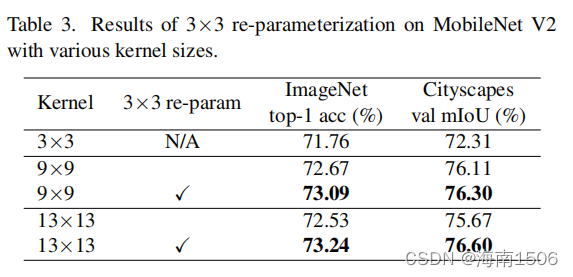
我们将MobileNetV2的3×3层分别替换为9×9和13×13, 并可选择采用结构再参数化[25,26,29]方法。具体来说 ,我们构建了一个平行于大层的3×3层,然后在Batch归 一化(BN)[49]层后相加它们的输出(图。2).经过训练后 ,我们将小核和BN参数合并到大核中,因此得到的模型 与训练模型等价,但不再有小核。表3显示了直接将内核 大小从9增加到13降低了准确性,而重新参数化解决了这 个问题。
没看懂!!!
备注3。众所周知,ViTs存在优化问题,特别是在小数据 集[33,57]上。一个常见的解决方法是引入卷积先验,例 如,在每个自注意块[17,96]中添加一个DW3×3卷积,这 与我们的方法类似。这些策略在网络之前引入了额外的 平移等方差和局部性,使得对小数据集更容易进行优化 而不失去通用性。与ViT行为的[33]类似,我们还发现, 当预训练数据集增加到7300万张图像时(参见下一节中的 RepLKNet-XL)时,重新参数化可以被省略而不退化。
对比提升ImageNet分类效果,大型卷积更能提升下游任务的效果
表 3(重新解析后)显示,将MobileNetV2的内核大小从 3×3增加到9×9,ImageNet的精度提高了1。33%,但城 市景观的mIoU为3.99%。表5显示了一个 类似的趋势:随着内核大小从[3,3,3,3]增加到 [31,29,27,13],ImageNet的准确率仅提高了0.96%,而 ADE20K[114]上的mIoU提高了3.12%。这种现象表明simi 模型 LarImageNet分数在下游任务中可能有非常不同的 能力(就像表5中底部的3个模型一样)。
备注4。是什么 导致了这种现象?首先,大型内核设计显著增加了有效 接受域(ERFs)[63]。许多工作已经证明了“上下文”信 息,这意味着大的erf,在许多下游任务中至关重要,如 目标检测和 语义分割[61,67,91,101,102]。我们 将在第二节中讨论这个话题。5.1.其次,我们认为另一 个原因可能是大型内核设计对网络造成了更多的形状偏 差。简单地说,图像网的图片可以根据纹理或 形状, 如在[7,34]中提出的那样。然而,人类识别物体的依据 主要是基于形状线索而不是纹理 因此,具有较强形状 偏差的模型可以更好地转移到下游任务。[86]最近的一项研究指出,ViTs具有强烈的 形状偏差,这部分解释了为什么ViTs在转移任务中超级 强大。相比之下,在ImageNet上训练的传统cnn倾向于偏 向于纹理[7,34]。幸运的是,我们发现简单地扩大cnn的 核大小可以有效地改善形状偏差。请参阅Sec。5.2详细 信息。
大型内核(eg.,13×13)即使是在小的特征地图(eg.,7×7)
为了验证它,我们将MobileNetV2的最 后阶段将DW卷积扩大到7×7或13×13,因此内核大小与 特征映射大小(默认为7×7)相当,甚至更大。我们按 照指南3的建议,对大型内核进行重新参数化应用。表4 显示,虽然在最后一阶段的卷积已经涉及到非常大的接 受域,进一步在- 折减内核大小仍然会导致性能改进,特别是在下游任务 上,如城市景观。
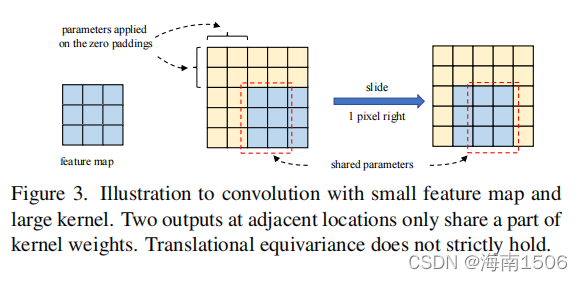
备注5。当核大小变大时,请注意,cnn的平移等方差并 不严格成立。如图3所示。两个输出在相邻的空间低- 阳离子只共享核权重的一小部分,即, 是通过不同的映射进行转换的。属性也 符合vits的“哲学”-放松共生关系- 在获得更多的容量之前。有趣的是,我们发现了二维 相对位置嵌入(RPE)[4,73],其应用广泛 在变压器社区中使用的,也可以被视为a 大的深度级内核大小(2H−1)×(2W−1),其中 大型内核不仅有助于学习概念之间的相对位置,而且由 于填充效应[51]而对绝对位置信息进行编码。
RepLKNet:一个大型内核体系结构
根据上述指导方针,在本节中,我们提出了RepLKNet ,这是一个具有大型内核设计的纯CNN架构。据我们所知 ,到目前为止,cnn仍然主导着小型型号的[107,109], 而视觉变压器被认为在更复杂的预算下比cnn更好。因此 ,在本文中,我们主要关注相对较大的模型(其复杂度与 ResNet-152[40]或Swin-B[59]相同或大于),以验证大的 内核设计是否可以消除cnn和ViTs之间的性能差距。
体系结构规范
我们在图4中绘制了RepLKNet的架构。茎指的是起始层。由于我们的目标是下游密集预测任 务的高性能,因此我们希望在开始时通过几个conv层捕 获更多细节。在前3×降采样3×之后,我们安排了一个 DW3×3层来捕获低水平模式,一个1×1conv,另一个 DW3×3层进行降采样。
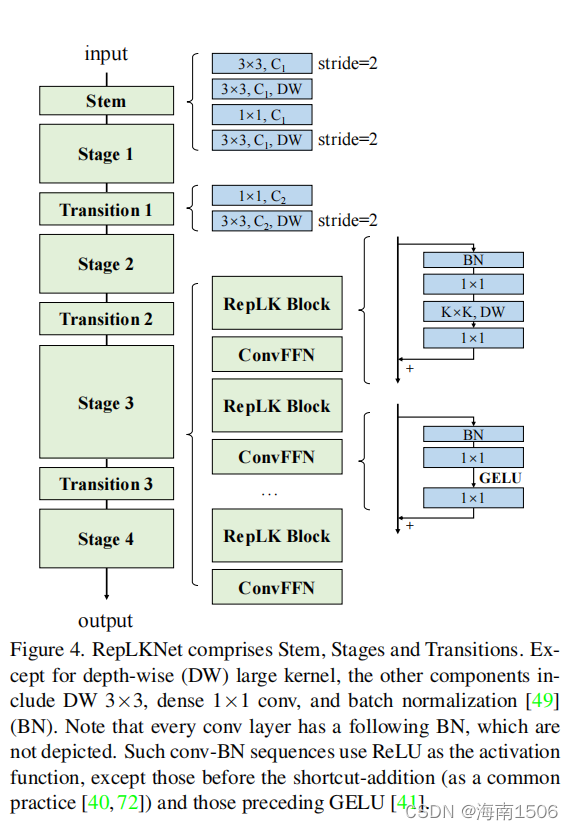
第1-4阶段每个都包含几个RepLK块,它们使用快捷方 式(指南1)和DW大型内核(指南2)。我们使用DWconv 前后的1×1conv作为一种常见的做法。请注意,每个DW 大型conv使用一个5×5内核进行重新参数化(指南3), 这在图中没有显示。4.除了提供足够的接受域和聚集空 间信息的能力外,模型的表征能力也与深度密切相关。 为了提供更多的非线性和跨通道的信息通信,我们希望 使用1×1层来增加深度。受到在变压器[33,59]和 MLPs[25,82,83]中广泛使用的前馈网络(FFN)的启发,我 们使用了一个类似的cnn风格的块,由快捷方式、BN、两 个1×1层和GELU[41]组成,因此它被称为ConvFFN块。与 经典的FFN使用层或-在全连接层之前,BN的优点是可以融合到conv中进行有 效的推断。通常情况下,ConvFFN块的内部通道数量为 4×作为输入。简单地遵循ViT和Swin,它们交织着注意 力和FFN块,我们在每个RepLK块之后放置一个ConvFFN。过渡块被放置在两个阶段之间,首先 通过1×1conv增加通道尺寸,然后使用DW3×3conv进行 2×降采样。 综上所述,每个阶段都有三个架构超参数:RepLK块的 数量B、通道维度C和内核大小K。因此,RepLKNet体系结 构将由[B]定义1,B2,B3,B4], [C1,C2,C3,C4], [K1,K2,K3,K4].
使大的内核甚至更大
我们通过固定B=[2,2,18,2],C=[128,256,512,1024] ,改变K,并观察分类和语义分割的性能,继续评估 RepLKNet上的大型内核。在没有仔细调整超参数的情况 下,我们随意地将内核大小分别设置为[13,13,13,13]、 [25,25,25,13]、[31,29,27,13],并将模型称为 RepLKNet-13/25/31。我们还构造了两个小内核基线尺寸都为3或7(RepLKNet-3/7)。
在ImageNet上,我们使用AdamW[62]优化器、随机增强 [21]、混合[106]、CutMix[105]、Rand擦除[112]和随机 深度[48]训练了120个时代,遵循最近的工作 [3,59,60,84]。详细的培训配置见附录A。
对于语义分割,我们使用ADE20K[114],这是一个广泛 使用的大规模语义分割数据集,包含150个类别的20K图 像用于训练,2K用于验证。我们使用imagenet训练的模 型作为骨干,采用MMS分割[18]实现的UperNet[97]和80k 迭代训练设置,并测试单尺度的mIoU。
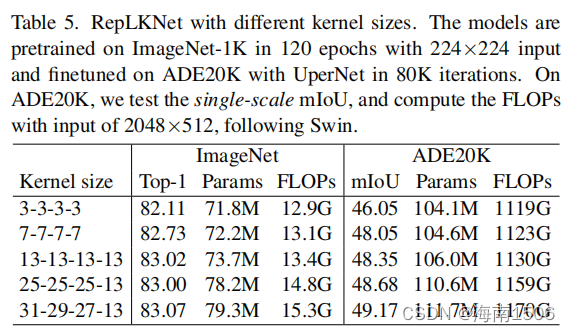
表5显示了我们在不同内核大小下的结果。在ImageNet 上,虽然将内核大小从3增加到13可以提高精度,但使它 们更大并不会带来进一步的改进。.82然而,在ADE20K上 ,将内核从[13,13,13,13]扩展到[31,29,27,13]会带来0 个更高的mIoU,只增加了5.3%的参数和3.5%的FLOPs,这 突出了大型内核对于下游任务的重要性。
在下面的小节中,我们使用具有更强训练配置的 RepLKNet31,与ImageNet分类、城市景观/ADE20K语义分 割和COCO[55]目标检测进行比较。我们将上述模型称为 RepLKNet-31B(B表示Base),将C=[192,384,768,1536]的 更宽模型称为RepLKNet31L(Large)。我们用RepLK块的 C=[256,512,1024,20282]和1.5×倒置瓶颈设计构建了另 一个RepLKNet-xl。e., DW大型转换层的通道为1.5×作 为输入)。
ImageNet分类
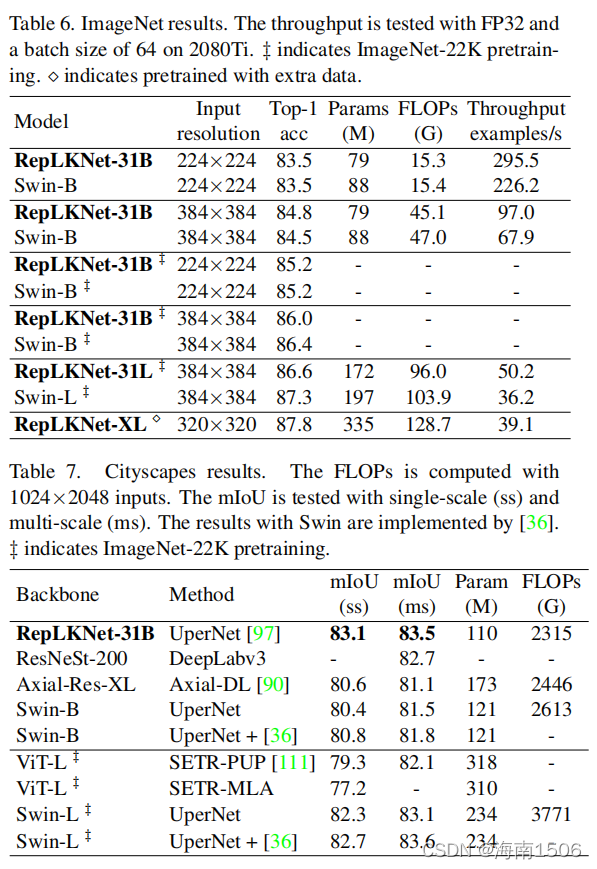
由于RepLKNet的整体架构类似于Swin,所以我们希望 首先做一个比较。对于ImageNet-1K上的RepLKNet-31B, 我们将上述训练计划扩展到300个ch,以进行公平的比较 。然后,利用输入分辨率为384×384,对30个时代进行 微调,使总训练成本要低得多 而不是Swin-B模型,它是用384×384训练的从头做起然后,我们在ImageNet-22K上预训练RepLKNet- B/L模型,并在ImageNet-1K上进行微调。RepLKNetXL是 在我们名为MegData73M的私有半监督数据集上进行预训 练的,该数据集在附录中介绍。我们还提供了在相同的 2080TiGPU上的批量大小为64的吞吐量测试。培训配置在 附录中介绍。
表6显示,虽然非常大的内核不是用于ImageNet分类, 但我们的RepLKNet模型显示了准确性和效率之间的良好 权衡。值得注意的是,仅通过ImageNet-1K训练, RepLKNet-31B的准确率达到84.8%,比Swin-B高0.3%,运 行速度快43%。尽管RepLKNet-XL比Swin-L有更高的流量 ,但它运行得更快,这突出了非常大的内核的效率。
语义分割
然后,我们使用预先训练好的模型作为城市景观(表7 )和ADE20K(表8)上的骨干。具体来说,我们使用由 MMS分割[18]实现的UperNet[97],城市景观采用80K迭代 训练计划,ADE20K采用160K。因为我们想进行评估只使用主干,我们不使用任何先进的技术,技巧,或自 定义算法。 在城市景观上,ImageNet-1k预训练的RepLKNet31B的 性能显著优于Swin-B(单尺度mIoU为2.7),甚至优于 ImageNet22k预训练的Swin-L。即使配备了为视觉变压器 定制的技术分流补丁[36],22k预训练的Swin-L的单尺度 mIoU仍然低于我们的1k预训练的RepLKNet-31B,尽管前 者有2个×参数。 在ADE20K上,RepLKNet-31B在1K和22K预训练前都优于 Swin-B,且单尺度mIoU的边缘尤其显著。使用我们的半 监督数据集MegData73M进行预训练,RepLKNet-XL实现了 56.0的mIoU,显示了大规模视觉应用的可伸缩性。

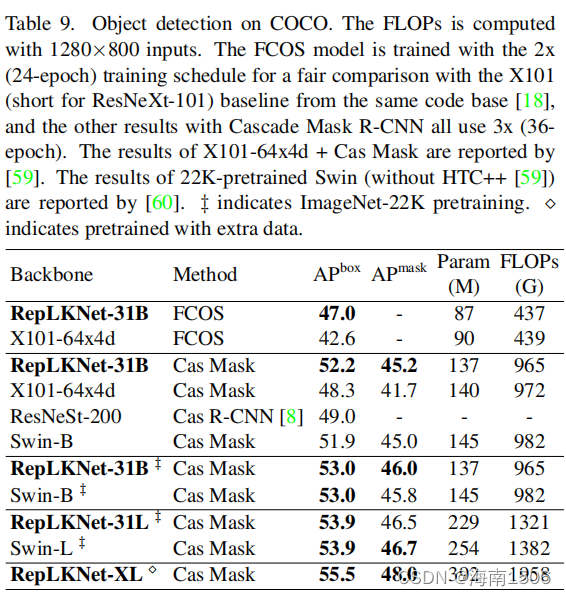
目标检测
掩模R-CNN[8,39]的主干,它们分别是一阶段和两阶段 检测方法的代表。我们使用2x(24时代)或3x)(36训练 计划和MM检测[12]中的默认配置。为了公平的比较,我 们采用ResNeXt-101-64x4d[99]背端,来自与竞争对手相 同的代码库。同样,我们只是替换了主干,而不使用任 何先进的技术。
讨论
大核cnn比深度小核模型
到目前为止,我们已经证明了大型内核设计可以显著 提高cnn的性能(特别是在下游任务上)。但是,值得注 意的是,大的核可以用一系列的小卷积[74]来表示:例 如,一个7×7的卷积可以分解成三个3×3核的堆栈而不 丢失信息3.考虑到这一事实,自然就出现了一个问题: 为什么传统的cnn可能包含数十或数百个小卷积(e。g., ResNets[40]),仍然表现得不如大核网络吗?
我们认为,在获得大的接受域方面,单个大内核比许 多小内核更有效。首先,根据有效接受性的理论 字段 (ERF)[63],ERF的大小与O(K^L)成正比,其中K为核大小 ,L为深度,i。e., 层数换句话说,ERF随核大小线性增 长,随深度亚线性增长。其次,深度的增加引入了优化 的难度

尽管ResNets似乎克服了这个困境,成功地训练了 一个数百层的网络,但一系列研究表明ResNets可能不是 这样尽管他们看起来很深。例如,[89]认为ResNets的行为就 像浅层网络的集合,这意味着即使深度显著增加, ResNets的ERFs仍然可能非常有限。这种现象在以前的著 作中也有经验观察到。g., [52].综上所述,大型内核设 计需要更少的层来获得大的erf,也避免了深度的增加带 来的优化问题。
为了支持我们的观点,我们选择ResNet101/152和上述 RepLKNet-13/31作为小核和大核模型的代表,这些模型 都在ImageNet上受过良好的训练,并使用来自ImageNet 验证集中的50张图像进行测试,调整大小为1024×1024 。为了可视化ERF,我们在[52]之后使用了一种简单而有 效的方法,如附录B中所述。简而言之,我们生成一个聚 合贡献分数矩阵A(1024×1024),其中每个条目 A(0≤a≤1)度量输入图像上对应的像素对最后一层产生 的特征图的中心点的贡献。图1显示了ResNet-101的高贡 献像素聚集在中心点周围,但外部点的贡献很低,表明 ERF有限。ResNet-152也表现出类似的模式,表明更多的 3个×3层并没有显著增加ERF。另一方面,图中的高贡献 像素。1©分布更均匀,表明RepLKNet-13关注更多的外 部像素。对于较大的内核,RepLKNet-31使高贡献像素的 扩散更加均匀,表明ERF更大。
表10提供了一个定量分析,其中我们报告了一个最小 矩形的高贡献面积比率T,它覆盖了给定阈值t上的贡献 分数。例如,ResNet-101的20%的像素贡献(A值)位于中 心的103×103区域内,因此面积比为(103/1024) 2=1.0%,t=为20%。 我们做了几个有趣的观察。1)ResNet的erf比RepLKNet小 得多。例如,ResNet-101的99%以上的贡献分数位于一个 小区域内,而这只占总区域的23.4%,而RepLKNet-31的 面积比为98.6%,这意味着大部分像素对最终的预测有很大的贡献。2)在ResNet-101中添加 更多的层并不能有效地扩大ERF,而扩大内核可以提高 ERF。
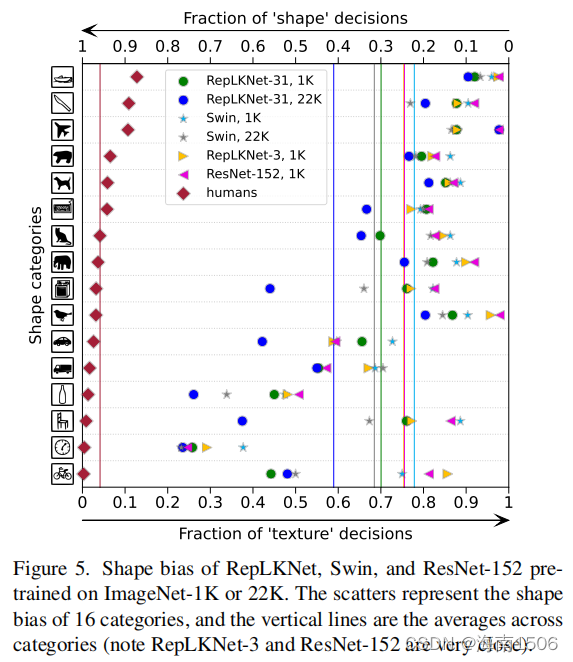
大核模型更类似于人类的形状偏差
[86]最近的一项研究报告称,视觉转换器更类似于人 类的视觉系统,它们的预测更多基于物体的整体形状, 而cnn则更多地关注局部纹理。我们不知道 降低其方法,并使用其工具箱[5]来获得在IMageNet-1K 或22K上预训练的RepLKNet-31B和Swin-B的形状偏差(例 如,基于形状,而不是纹理的预测的部分),以及两个 小核基线RepLKNet-3和ResNet-152。图5表明RepLKNet比 Swin具有更高的形状偏差。考虑到RepLKNet和Swin具有 相似的整体架构,我们认为形状偏差与有效接受场密切 相关,而不是自我注意的具体公式(即查询-键-值设计 )。这也解释了1)高形状偏差的振动[33]由[86]报道( 因为[33]采用全球关注),2)低形状偏差的双胞胎(关 注本地窗口),和3)的形状偏差小核基线RepLKNet-3, 非常接近ResNet-152(两个模型都是由3×3卷积)。
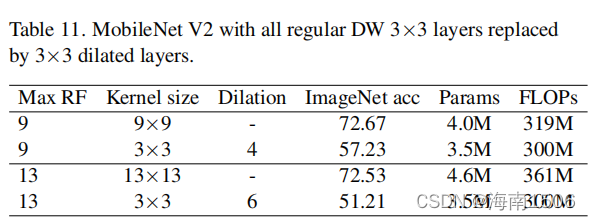
密集的卷积vs稀释的卷积
作为实现大卷积的另一种替代方法,扩张卷积[13,101] 是增加接受野(RF)的共同组成部分。然而,表11显示, 尽管深度的扩张卷积可能与深度密集卷积具有相同的最 大射频,但其表示容量要低得多,这是意料之中的,因 为它在数学上等同于稀疏的大卷积。文献(如[92,98]) 进一步表明,扩展的卷积可能会出现网格问题。我们认 为膨胀卷积的缺点可以通过混合不同膨胀的卷积来克服 ,这将在未来进行研究。
限制
尽管大型内核设计极大地改进了ImageNet和下游任务 上的cnn,然而,根据表6,随着数据和模型规模的增加 ,RepLKNet开始落后于Swin变形金刚,e。g., RepLKNet -31L的ImageNet前1位精度为0。比使用ImageNet-22K预 训练时的Swin-L低7%(而下游的分数仍然具有可比性) 。目前尚不清楚这种差距是由于次优超参数调整造成的 ,还是由于数据/模型扩展时cnn的其他基本缺陷造成的 。我们正在研究这个问题,例如,研究一个更强大的CNN 基线(例如,ConNvNeXt[60])是否有助于通过大型内核设 计超过ViT的上界。
结论
本文回顾了在CNN架构设计中长期以来被忽视的大型卷 积核。我们证明,使用一些大内核而不是许多小内核可 以更有效地获得更大的有效的接受域,提高CNN的性能, 特别是在下游任务上,当数据和模型扩大时,大大缩小 了CNN和vit之间的性能差距。我们希望我们的工作能够 促进cnn和ViTs的研究。一方面,对于CNN社区来说,我 们的研究结果建议我们应该特别关注ERFs,这可能是实 现高绩效的关键。另一方面,对于ViT社区,由于大卷积作为具有类似行为的多头自我注意的替代品,它可能 有助于理解自我注意的内在机制。














 880
880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









