






 本文重新审视CNN中大型内核设计,提出五条设计准则并构建RepLKNet架构。实验表明,大内核CNN比小内核模型有更大有效感受野和更高形状偏见,能缩小与ViT的性能差距,在ImageNet和下游任务中表现出色,但大模型在ImageNet顶级精度上有差距。
本文重新审视CNN中大型内核设计,提出五条设计准则并构建RepLKNet架构。实验表明,大内核CNN比小内核模型有更大有效感受野和更高形状偏见,能缩小与ViT的性能差距,在ImageNet和下游任务中表现出色,但大模型在ImageNet顶级精度上有差距。
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
提升至31x31的内核:重新审视现代卷积神经网络(CNN)中的大型内核设计
论文链接:http://arxiv.org/abs/2203.06717
代码链接:https://github.com/megvii-research/RepLKNet
https://github.com/DingXiaoH/RepLKNet-pytorch
1、摘要
文中重新审视了现代卷积神经网络(CNN)中大型内核设计。受近期视觉Transformer(ViT)进展的启发,文中表明使用少数大型卷积内核,而非堆叠小内核,可能是一种更强大的范式。文中提出了五条设计高效高性能大型内核CNN的准则,例如应用重参数化的大型深度卷积。遵循这些准则,文中提出了一种名为RepLKNet的纯CNN架构,其内核大小达到了31x31,与通常使用的3x3内核相比显著增大。RepLKNet极大地缩小了CNN与ViT之间的性能差距,例如在ImageNet和一些典型下游任务上达到或超过了Swin Transformer的表现,同时具有更低的延迟。RepLKNet还展示了良好的大数据和大模型扩展性,例如在ImageNet上的top-1精度达到87.8%,在ADE20K上的mIoU达到56.0%,在类似模型规模的最先进的方法中表现出色。作者研究进一步揭示,与小内核CNN相比,大型内核CNN具有更大的有效感受野和更高的形状偏见,而非纹理偏见。

目录
- Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
- 1、摘要
- 2、关键问题
- 3、五个大型内核CNN的准则
- 4、原理
- 5、实验
- ImageNet Classification
- Semantic Segmentation
- Object Detection
- Large-Kernel CNNs have Larger ERF than Deep Small-Kernel Models
- Large-Kernel Models are More Similar to Human in Shape Bias
- Large Kernel Design is a Generic Design Element that Works with ConvNeXt
- Large Kernels Outperform Small Kernels with High Dilation Rates
- Limitations
- 6、总结
2、关键问题
- 如果在传统的CNN中使用少数大卷积核而非众多小卷积核,会怎样?是大卷积核还是构建大感受野的方式是缩小CNN与ViTs性能差距的关键?
3、五个大型内核CNN的准则
五个实用的指导准则:1)实际上,非常大的内核仍然可以保持高效(表1,表5);2)对于具有非常大内核的网络,Identity shortcut至关重要(表2);3)使用小内核的重参数化有助于解决优化问题(图2);4)大内核对下游任务的提升远超过ImageNet(表3);5)即使在小特征图上,大内核也具有价值(图3)。



4、原理
Models with Large Kernels
使用了更大的窗口大小的三个代表性工作是全局滤波网络(GFNets)[74]、CK-Conv[76]和FlexConv[75]。GFNet在频域优化空间连接权重,这在空间域等同于圆周全局卷积。CK-Conv将内核形式化为处理序列数据的连续函数,可以构建任意大的内核。FlexConv为不同层学习不同的内核大小,可以达到特征图的大小。
Concurrent works
[90]的ConvMixer采用高达 9 × 9 9 \times 9 9×9的卷积来替代视觉Transformer(ViTs)[35]或多层感知器(MLPs)[87,88]中的“混合器”组件。MetaFormer[108]提出池化层可以作为自注意力的替代方案。ConvNeXt[62]利用 7 × 7 7 \times 7 7×7的深度卷积来设计强大的架构,推动了卷积神经网络性能的极限。尽管这些工作展示了卓越的表现,但它们并未显示出使用更大卷积(如 31 × 31 31 \times 31 31×31)的优势。
Model Scaling Techniques
对于小型模型,为了提升性能,通常会进行规模扩展,因此,scaling策略在最终的精度与效率权衡中占据关键地位。在卷积神经网络(CNNs)中,现有的扩展方法主要关注模型的深度model depth、宽度width、输入分辨率input resolution[32,70,84]、瓶颈比bottleneck ratio和组宽度group width[32,70]。然而,kernel size(内核大小)这一维度常常被忽视。
Structural Re-parameterization
结构重参数化[27][28][29][30][31]是一种通过转换参数来等效转换模型结构的方法。例如,RepVGG的目标是构建一个深度的、类似VGG(如无分支)的模型,且在训练过程中会添加额外的ResNet风格的短路连接,与
3
×
3
3 \times 3
3×3层并行。与实际的VGG模型相比,这种模型训练起来更为困难[42],但这些短路连接有助于模型达到满意的性能。训练完成后,这些短路连接通过一系列线性变换融入到并行的
3
×
3
3 \times 3
3×3核中,使得最终模型成为类似VGG的结构。本文运用这种方法将一个相对较小的(如3×3或5×5)核与一个非常大的核相结合。这样,大核就能够捕捉到小尺度的模式,从而提升模型的性能。


Architecture Specification
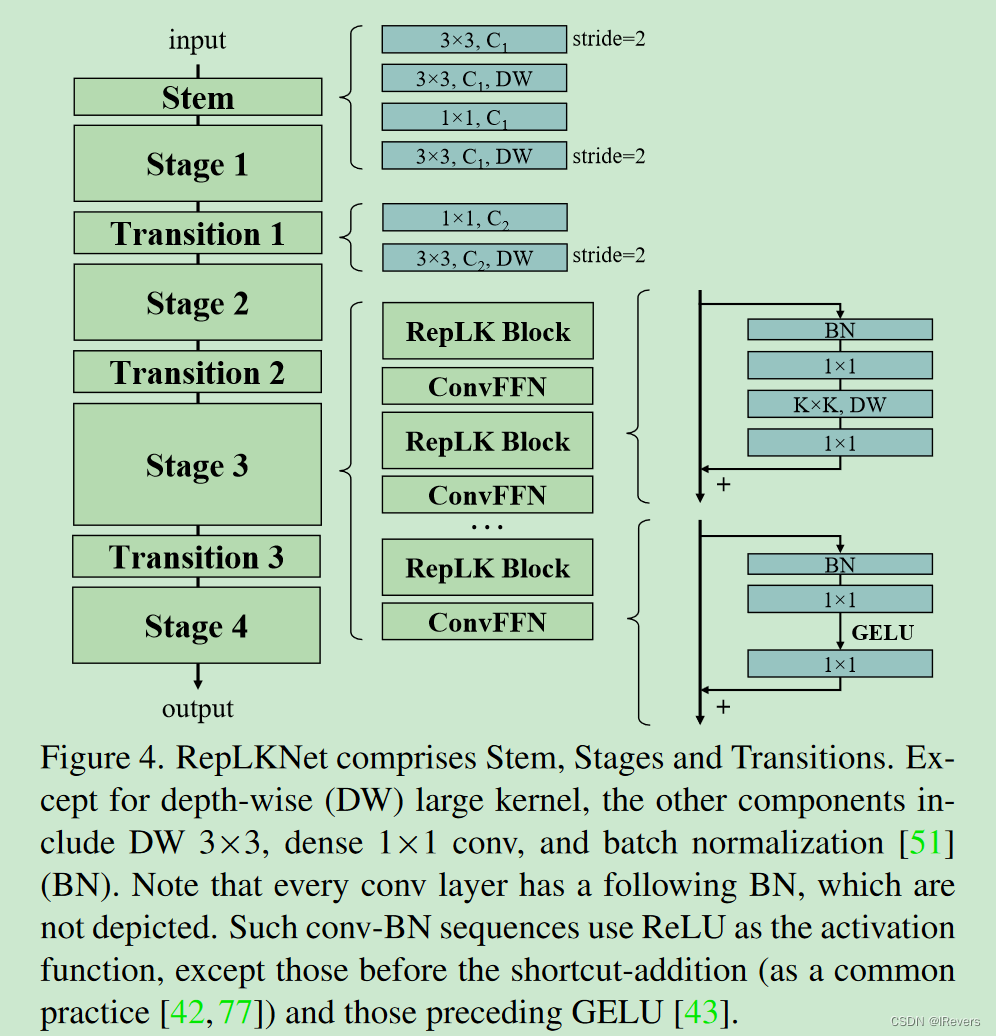
在图4中概述了RepLKNet的架构:Stem部分指的是开始的几层。由于文中专注于下游密集预测任务的高性能,作者希望通过初期的几个卷积层来捕捉更多的细节。在第一个 3 × 3 3 \times 3 3×3卷积层(具有2倍下采样)之后,文中安排了一个深度卷积(DW) 3 × 3 3 \times 3 3×3层来捕捉低级模式,接着是一个 1 × 1 1 \times 1 1×1卷积层,以及另一个DW 3 × 3 3 \times 3 3×3层进行下采样。
Stage1-4包含多个RepLK块,它们利用跳跃连接(准则2)和大深度卷积核(准则1)。我们在DW卷积前后使用 1 × 1 1 \times 1 1×1卷积,这是常见的做法。请注意,每个大深度卷积使用 5 × 5 5 \times 5 5×5的卷积核进行参数重排(准则3),这在图4中未显示。除了提供足够大的感受野和空间信息聚合能力的大卷积层外,模型的表征能力还与深度密切相关。为了提供更多的非线性以及跨通道的信息交流,使用 1 × 1 1 \times 1 1×1层来增加深度。受到在Transformer[35,61]和MLP[27,87,88]中广泛应用的前馈网络(FFN)的启发,使用了一个类似的CNN风格块,由跳跃连接、BN、两个 1 × 1 1 \times 1 1×1层和GELU[43]组成,因此称为ConvFFN块。与经典FFN在全连接层前使用层归一化[3]不同,BN的优势在于可以与卷积融合,以实现更高效的推理。按照惯例,ConvFFN块的内部通道数是输入的4倍。文中没有像ViT和Swin那样交替使用注意力和FFN块,而是每个RepLK块后都放置一个ConvFFN。
Transition Blocks放置在阶段之间,首先通过
1
×
1
1 \times 1
1×1卷积增加通道维度,然后接上BN。需要注意的是,每个卷积层后面都跟着BN,但图中未显示。除了在跳跃连接添加前和GELU前的卷积层,这些Conv-BN序列使用ReLU作为激活函数。总结来说,每个阶段有三个架构超参数:RepLK块的数量B、通道维度C和卷积核大小K。因此,一个RepLKNet架构由以下参数定义:
[B1, B2, B3, B4], [C1, C2, C3, C4], [K1, K2, K3, K4]。
Making Large Kernels Even Larger
在RepLKNet上评估大尺寸的卷积核,通过固定B=[2, 2, 18, 2],C=[128, 256, 512, 1024],并改变K的大小,观察分类和语义分割的性能。作者没有细致地调整超参数,而是随意设置卷积核尺寸为[13, 13, 13, 13]、[25, 25, 25, 13]和[31, 29, 27, 13],分别称为RepLKNet-13/25/31。文中还构建了两个小核尺寸的基线,所有核大小为3或7(RepLKNet-3/7)。
在ImageNet上,实验使用AdamW [64]优化器训练120个epoch,同时应用RandAugment [23]、mixup [111]和CutMix [110]。对于语义分割,使用ADE20K [120],这是一个广泛使用的大型语义分割数据集,包含20K张150类图像用于训练,2K用于验证。实验使用ImageNet预训练的模型作为backbones,并采用MMSegmentation [20]实现的UperNet [102],采用80K迭代的训练设置,测试单尺度的mIoU。

表5展示了不同核尺寸的结果。在ImageNet上,从3到13的核尺寸增加确实提高了准确度,但进一步增大核尺寸并未带来额外提升。然而,在ADE20K上,从[13, 13, 13, 13]扩展到[31, 29, 27, 13],仅增加了5.3%的参数和3.5%的计算量,mIoU却提高了0.82,这突显了大核对于下游任务的重要性。
在接下来的子节中,使用更强的训练配置,将RepLKNet-31与ImageNet分类、Cityscapes/ADE20K语义分割和COCO [57]对象检测的最新研究进行比较。文中称上述模型为RepLKNet-31B(B代表base),以及具有C=[192, 384, 768, 1536]的更宽模型为RepLKNet-31L(大)。实验还构建了一个更宽的RepLKNet-XL,其C=[256, 512, 1024, 2048],并在RepLK块中采用1.5倍的inverted bottleneck设计(即DW大卷积层的通道是输入的1.5倍)。
5、实验
ImageNet Classification

对于在ImageNet-1K上的RepLKNet-31B,实验将其先前的训练计划延长至300个epoch以实现公平对比。然后,实验进行了30个epoch的微调,输入分辨率调整为 384 × 384 384 \times 384 384×384,这样总的训练成本显著降低。还在附录中提供了在相同2080Ti GPU上的64批次吞吐量测试结果。训练配置详情见附件。表6显示,尽管非常大的内核并非专为ImageNet分类设计,但RepLKNet模型在准确性和效率之间展现出了良好的权衡。值得注意的是,仅凭ImageNet-1K的训练,RepLKNet-31B就达到了84.8%的精度,比Swin-B高出0.3%,并且运行速度快43%。尽管RepLKNet-XL的计算量(FLOPs)高于Swin-L,但其运行速度更快,这突显了非常大内核的高效性。
Semantic Segmentation


利用预训练模型作为Cityscapes(表7)和ADE20K(表8)的后处理基础。具体来说,在&MMSegmentation[20]实现的UperNet[102]上进行实验,Cityscapes采用80K迭代训练方案,而ADE20K则采用160K。由于文章专注于评估后处理部分,因此不使用任何高级技术、技巧或定制算法。
在Cityscapes上,ImageNet-1K预训练的RepLKNet-31B明显优于Swin-B(单尺度mIoU提高了2.7),甚至超过了ImageNet-22K预训练的Swin-L。尽管配备了专为视觉Transformer设计的DiversePatch[38]技术,ImageNet-22K预训练的Swin-L的单尺度mIoU仍然低于我们的1K预训练RepLKNet-31B,尽管后者参数量只有前者的两倍。
在ADE20K上,RepLKNet-31B无论使用1K或22K预训练都优于Swin-B,单尺度mIoU的差距尤为显著。当使用半监督数据集MegData73M预训练时,RepLKNet-XL达到了56.0的mIoU,这表明它在大规模视觉应用中具有可行性。
Object Detection

在目标检测任务中,采用RepLKNets作为FCOS [86]和Cascade Mask R-CNN [9,41]的后处理基础,它们分别代表了一阶段和两阶段检测方法的代表,并且遵循MMDetection [13]的默认配置。为了公平比较,使用2x (24epoch)的训练计划来训练FCOS模型,与同一代码库中的X101(即ResNeXt-101 [104])基线进行对比。其他使用Cascade Mask R-CNN的结果则采用3x(36epoch)的训练。仅替换后处理部分,没有使用任何高级技术。表9显示,尽管RepLKNets拥有更少的参数和更低的计算量(FLOPs),其性能比ResNeXt-101-64x4d提高了多达4.4 mAP。需要注意的是,通过采用HTC [12]、HTC++ [61]、Soft-NMS [7]等高级技术或6x(72epoch)的训练计划,性能可能进一步提升。与Swin相比,RepLKNets在参数更少、计算量更低的情况下,实现了更高的或相当的mAP。尤其引人注目的是,RepLKNet-XL达到了55.5的mAP,再次证明了其可扩展性。
Large-Kernel CNNs have Larger ERF than Deep Small-Kernel Models
上述已经证明了大核设计能显著提升卷积神经网络(CNN)的表现,特别是在下游任务上。然而,值得注意的是,大核可以通过一系列小卷积来表达,例如一个 7 × 7 7 \times 7 7×7的卷积可以分解为三个 3 × 3 3 \times 3 3×3的卷积而不会丢失信息(分解后需要增加更多的通道以保持自由度)。
考虑到这一点,一个自然的问题是:为什么包含数十或数百个小卷积(如ResNet[42])的传统CNN仍然表现逊于大核网络?**就获取大感受野而言,单个大核远比多个小核更有效。**首先,根据有效感受野(ERF)理论[65],ERF与核大小K和深度L的关系为 O ( K L ) O(K \sqrt{L}) O(KL),即ERF随核大小线性增长,而与深度的增加次线性。其次,深度增加会引入优化难题[42]。尽管ResNet看似克服了这一困境,能够训练数百层的网络,但一些研究[26,94]指出,ResNet可能不像看起来那么深。例如,[94]提出ResNet的行为类似于浅层网络的集合,这意味着即使深度大幅增加,ResNet的ERF可能仍然非常有限。这种现象在先前的工作中也得到了实证观察[54]。总之,大核设计需要更少的层来获得大ERF,并避免深度增加带来的优化问题。如图1。
为了支持文中的观点,选择了ResNet-101/152和上述的RepLKNet-13/31作为小核和大核模型的代表,它们都在ImageNet上进行了良好训练,并使用ImageNet验证集的50张
1024
×
1024
1024 \times 1024
1024×1024大小的图像进行测试。为了可视化ERF,实验采用了简单而有效的方法(代码在[2]中发布),如附录B中所述。简而言之,生成了一个贡献得分矩阵A(
1024
×
1024
1024 \times 1024
1024×1024),其中每个元素a(
0
≤
a
≤
1
0≤a≤1
0≤a≤1)衡量输入图像中对应像素对最后一层特征图中心点的贡献。图1显示ResNet-101的高贡献像素集中在中心点附近,但外围点的贡献很低,表明ERF有限。ResNet-152也显示出类似模式,表明增加更多的
3
×
3
3 \times 3
3×3层并未显著增加ERF。另一方面,图1(C)中的高贡献像素分布更均匀,表明RepLKNet-13更关注外围像素。随着核大小的增大,RepLKNet-31使高贡献像素分布更均匀,表明ERF更大。

表10提供了定量分析,报告了覆盖给定阈值t的贡献得分的最小矩形的高贡献区域比r。例如,ResNet-101的20%贡献得分(A值)位于中心 103 × 103 103 \times 103 103×103区域,当t=20%时,面积比为 ( 103 / 1024 ) 2 = 1.0 (103/1024)^{2}=1.0% (103/1024)2=1.0。实验观察到一些有趣的现象:1)尽管ResNet深度显著,但其ERF远小于RepLKNet。例如,ResNet-101的贡献得分中超过99%集中在仅占总面积23.4%的小区域内,而RepLKNet-31的这一比例为98.6%,意味着大多数像素对最终预测有重大贡献。2)向ResNet-101添加更多层并未有效扩大ERF,而增大核尺寸则在几乎不增加计算成本的情况下提高了ERF。
Large-Kernel Models are More Similar to Human in Shape Bias
RepLKNet-31B的形状偏见显著高于Swin Transformer和小内核CNN。最近的一项研究[91]指出,视觉Transformer在预测时更倾向于基于物体的整体形状,而CNN则更侧重于局部纹理。实验遵循其方法论,并使用其工具包[6]来计算在ImageNet-1K或22K预训练的RepLKNet-31B、Swin-B以及两个小内核基线(RepLKNet-3和ResNet-152)的形状偏见。

图5显示,RepLKNet的形状偏见高于Swin。考虑到RepLKNet和Swin在整体架构上的相似性,作者认为形状偏见与有效感受野密切相关,而非自注意力的具体实现(即查询-键-值设计)。这也解释了[91]报告的ViTs(由于使用全局注意力)的高形状偏见,以及1K预训练的Swin(注意力集中在局部窗口)的低形状偏见。此外,小内核基线RepLKNet-3的形状偏见接近ResNet-152(两者都由 3 × 3 3 \times 3 3×3卷积组成),这表明形状偏见与内核大小关系不大。
Large Kernel Design is a Generic Design Element that Works with ConvNeXt
大kernel设计是一种通用的设计元素,它与ConvNeXt架构相结合时效果显著。在ConvNeXt [62]中,将
7
×
7
7 \times 7
7×7的卷积层替换为
31
×
31
31 \times 31
31×31的大内核,能够带来显著的性能提升,例如,ConvNeXt-Tiny + 大kernel > ConvNeXt-Small,以及ConvNeXt-Small + 大kernel > ConvNeXt-Base。

实验选择最近提出的ConvNeXt [62]作为基准架构,来评估大内核作为通用设计元素的效果。简单地将ConvNeXt [62]中的 7 × 7 7 \times 7 7×7卷积层替换为 31 × 31 31 \times 31 31×31的大内核。在ImageNet(120个epoch)和ADE20K(80,000个迭代)上的训练配置与Making Large Kernels Even Larger节所示的结果保持一致。表11显示,尽管原始内核已经为 7 × 7 7 \times 7 7×7,但进一步增大内核尺寸仍然带来了显著的改进,特别是在下游任务上:使用 31 × 31 31 \times 31 31×31的大内核,ConvNeXt-Tiny的表现优于原始的ConvNeXt-Small,而大内核的ConvNeXt-Small则优于原始的ConvNeXt-Base。这再次证明了内核尺寸是一个重要的扩展维度。
Large Kernels Outperform Small Kernels with High Dilation Rates
请参阅附录C以获取详细信息。
在"Large Kernels Outperform Small Kernels with High Dilation Rates"这一节中,详细探讨了高膨胀率下的大内核在性能上的优势。实验发现,通过增加内核的膨胀率,大内核能够在保持相同计算资源的情况下,提供更大的感受野,从而实现更好的特征融合和表示能力。实验结果显示,相比于小内核,大内核在高膨胀率下能够取得更好的分类和定位性能。这一发现挑战了传统的内核设计观念,表明在特定的网络架构和任务中,大内核策略可能是更有效的选择。附录C中提供了这些实验的详细设置、结果以及对这一现象的深入分析。
Limitations
尽管大尺度内核设计显著提升了卷积神经网络(CNN)在ImageNet和下游任务上的性能,然而,根据表6所示,随着数据和模型规模的增大,RepLKNet-31L在ImageNet-22K预训练下的ImageNet顶级精度比Swin-L低0.7%(尽管下游任务的性能仍然相当)。目前尚不清楚这一差距是由超参数调优不足还是当数据/模型规模扩大时CNN固有的其他潜在劣势导致的。
6、总结
论文重新审视了大型卷积核,这一设计在构建CNN架构时曾被长期忽视。实验证明,使用少数大型卷积核而非众多小型卷积核能更有效地实现更大的有效感受野,从而显著提升CNN在下游任务中的性能,并极大地缩小了CNN与ViT在数据和模型规模扩大时的性能差距。



















 1998
1998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











