







- Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
- Real-ESRGAN: 使用纯合成数据训练真实世界盲超分辨率
- Proceedings of the IEEE/CVF international conference on computer vision.
- 2021: 1905-1914.
- Xintao Wang、Liangbin Xi、Chao Dong、Ying Shan
摘要
-
首先指出目前的盲超分辨率技术的不足:
- 虽然盲超分辨技术尝试来恢复具有未知和复杂退化的低分辨率图像,但是对于现实世界的退化图像,其重建技术的泛化性还不高。
-
然后提出本文的Real-ESRGAN:
- Real-ESRGAN: 通过使用合成图像来训练网络模型, 能够将ESRGAN来泛化到真实世界。
-
接着简要介绍Real-ESRGAN的创新点
(1)通过引入高阶退化过程,来模拟复杂的真实世界退化问题。
(2)考虑了重建过程中出现的振铃伪影和过冲伪影。
(3)使用具有谱归一化的U-Net,来作为GAN的判别器。 -
最后说明,Real-ESRGAN实现了SOTA,。
引言
- 首先说明了“经典的SISR获取LR图像的不足“:
- 之前的大多数方法都是用的bicubic downsampling (双三次下采样)来获取LR,但是这与实际的退化不同,使得这些方法在现实场景中不切实际。
- 然后介绍了盲超分辨率(Blind super-resulotion):
- 目的是:恢复遭受未知和复杂退化的低分辨率图像
- 可分为两类:
- explicit modeling(显式建模):
- 常采用经典的一阶退化模型,包括:
- blur,downsampling,noise,JPEG compression
- 缺点:
- 现实世界的退化通常太复杂,无法通过多种退化的简单组合来建模。因此,这些方法在现实样本中很容易失败。
- 常采用经典的一阶退化模型,包括:
- implicit modeling(隐式建模):
- 利用(带有生成对抗网络的)数据分布来获得退化模型。
- 缺点:
- 模型仅限于训练数据集中的退化,并且不能很好的推广到分布外的数据。
- explicit modeling(显式建模):
- 提出了本文的动机:
- 扩展强大的ESRGAN,通过使用更实用的退化过程合成训练对,来恢复一般的现实世界LR图像。
- 并通过举例说明”真正的复杂退化过程通常来自不同退化过程的复杂组合“,如:
- 相机成像系统:
- 当使用手机拍照时,照片可能会出现一些质量下降的情况。
- 如:相机模糊,传感器噪声,锐化伪影,JPEG压缩。
- 图像编辑:
- 然后进行一些编辑并传到社交媒体app上,这会引入进一步的压缩和不可预测的噪音。
- 互联网传输:
- 当图像在互联网上共享多次时,上述的过程变得更加复杂。
- 相机成像系统:
- 本文提出了一种新的high-order degeadation modeling(高阶退化模型),为了实现现实世界退化:
- 即通过几个重复的退化过程来建模,每个过程都是经典的退化模型。
- 并且本文采用的是二阶退化过程, 以在简单性和有效性之间取得良好的平衡。
- 高阶退化建模更加灵活,并试图模仿真实的退化过程。
- 还提出,进一步在合成过程中加入sinc滤波,来模拟常见的振铃和过冲伪影。
- 由于上述退化空间比ESRGAN大得多,所以做了进一步改进:
- (1) 将ESRGAN中得VGG式鉴别器改进为U-Net
- 因为鉴别器需要更强大的能力,来区分复杂训练输出的真实性
- 而鉴别器的梯度反馈需要更准确,以进行局部细节增强。
- (2) 采用光谱归一化,来稳定训练动态:
- 因为U-Net结构和复杂的退化增加了训练的不稳定性。
- 光谱归一化也能使训练Real-ESRGAN更容易,并实现局部细节增强和抑制伪影的平衡。
- (1) 将ESRGAN中得VGG式鉴别器改进为U-Net
- 总结上述过程:
- 本文提出了一种高阶退化过程来模拟实际退化,并利用sinc滤波来模拟常见的振铃和过冲伪影。
- 对ESRGAN做了一些修改:
- 使用具有光谱归一化的U-Net判别器,来提高判别器的能力并稳定训练动态。
- 使用纯合成数据训练的Real-ESRGAN:
- 能够恢复大多数真实世界图像,并取得比之前的作品更好的视觉性能,使其在现实世界中更加实用。
相关工作
- The image super-resolution
- 提出了超分的各种发展,并说明之前的发展都是采用的双三次下采样来获得LR图像。
2_3. 提出了盲超分的一些探索:
- 显式退化表达:
- 通常由退化预测和条件恢复两部分组成,这两部分既可以单独执行,也可以联合(迭代)执行。
- 这种方式依赖于预定义的退化表示(如退化类型和级别),并且通常考虑简单的合成退化。
- 不准确的退化估计将不可避免地导致伪影。
- 获取/生成尽可能真实数据的训练对,然后训练统一的网络来解决盲SR。
- 训练对通常由以下生成:
1. 用特定的相机捕获,然后进行繁琐的对齐。
- 捕获的数据仅局限于特定相机相关的退化,因此不能很好地推广到其他真实图像。
2. 直接从具有循环一致性损失的不配对数据中学习。
- 使用不成对的数据学习细粒度的退化具有挑战性,并且结果通常不令人满意。
3. 用估计的模糊核和提取的噪声块合成。
- 提出了超分的各种发展,并说明之前的发展都是采用的双三次下采样来获得LR图像。
- Degradation models
- 经典退化模型:
- 目前广泛用于盲SR方法,但是现实世界的退化通常太复杂。无法明确建模。
- 隐式建模:
- 试图学习网络内的退化生成过程。
- 本文也提出了一种高阶退化模型,来合成更实际的退化。
- 经典退化模型:
方法论
3.1 经典的退化模型
- 盲超分辨:
- 从具有未知且复杂退化的低分辨率图像中恢复高分辨率图像
- 通常采用经典的退化模型来合成第分辨率图像。
- 经典退化模型的步骤:
- 标注图像 y 首先与模糊核 k 进行卷积;
- 然后,执行比例因子为 r 的下采样操作;
- 接着,通过加入噪声n,来获得低分辨率图像x;
- 最后,采用JPEG压缩,生成广泛用于现实世界的图像。
- 经典退化模型的表达式:
x
=
D
(
x
)
=
[
(
y
⊗
k
)
↓
r
+
n
]
J
P
E
G
(
1
)
x = \mathcal D(x) = [(y \ \otimes \ k)\downarrow_{r} +n]_{JPEG} \quad\quad\quad\quad(1)
x=D(x)=[(y ⊗ k)↓r+n]JPEG(1)
- 其中, D 表示退化过程 \mathcal D表示退化过程 D表示退化过程
- Blur(模糊核)k:
- 模糊退化建模通常作为,带有线性模糊滤波器的卷积操作。
- 常见的选择有:各向同性和各向异性高斯滤波器
- 表达式为: k ( i , j ) = 1 N e x p ( − 1 2 C T ∑ − 1 C ) , C = [ i , j ] T ( 2 ) k(i,j) = \frac{1}{N}exp(-\frac{1}{2}C^T\sum\ ^{-1} \ C), \quad\quad C = [i,j]^T\quad\quad\quad(2) k(i,j)=N1exp(−21CT∑ −1 C),C=[i,j]T(2)
- 其中, ∑ \sum ∑:协方差矩阵 C:空间坐标 N:归一化常数
- ∑ \sum ∑的表达式为: ∑ = R [ σ 1 2 0 0 σ 2 2 ] R T = [ c o s θ − s i n θ s i n θ cos θ ] [ σ 1 2 0 0 σ 2 2 ] [ cos θ s i n θ − s i n θ cos θ ] (3) \sum = R\left[\begin{matrix}\sigma_1^2 & 0\\0 & \sigma_2^2 \end{matrix}\right]\tag{3}R^T =\left[\begin{matrix}cos\theta & -sin\theta\\sin\theta & \cos\theta \end{matrix}\right] \left[\begin{matrix}\sigma_1^2 & 0\\0 & \sigma_2^2 \end{matrix}\right]\left[\begin{matrix}\cos\theta & sin\theta\\-sin\theta & \cos\theta \end{matrix}\right] ∑=R[σ1200σ22]RT=[cosθsinθ−sinθcosθ][σ1200σ22][cosθ−sinθsinθcosθ](3)
- R:旋转矩阵
-
σ
1
和
σ
2
\sigma1和\sigma2
σ1和σ2:沿两个主轴的标准差(即协方差矩阵的特征值)
- 当 σ 1 = σ 2 \sigma1 = \sigma2 σ1=σ2时:k为各向同性高斯模糊核;否则,k为各向异性高斯模糊核。
- θ \theta θ:旋转度数。
- 广义高斯模糊核和平台形分布:
- 背景:虽然高斯模糊内核广泛应用于模糊退化,但它们可能无法很好地近似真实的相机模糊。
- 它们的概率密度函数表达式分别为: 1 N e x p ( − 1 2 C T ∑ − 1 C ) β , 1 N 1 1 + ( C T ∑ − 1 C ) β \frac{1}{N}exp(-\frac{1}{2}C^T\sum\ ^{-1} \ C)^\beta, \quad\quad \frac{1}{N}\frac{1}{1 + (C^T\sum\ ^{-1} \ C)^\beta} N1exp(−21CT∑ −1 C)β,N11+(CT∑ −1 C)β1
- 其中: β \beta β:是形状参数。
- 这些模糊内核可以为一些真实样本产生更清晰的输出。
- Noise(噪声)n:
- 常见的选择有:
- 加性高斯噪声(additive Gaussian noise):
- 加性高斯噪声的概率密度等于高斯分布的概率密度函数。
- 噪声强度由高斯分布的标准差(即 σ \sigma σ值)控制。
- 当RGB图像的每个通道都有独立采样的噪声时,合成的噪声就是颜色噪声。
- 通过对所有三个通道实用相同的采样噪声,来合成灰度噪声。
- 泊松噪声(Poisson noise):
- 泊松噪声服从泊松分布。
- 泊松噪声常用于对统计量子涨落(即给定曝光水平下感测到的光子数量的变化)引起的传感器噪声进行近似建模。
- 泊松噪声的强度与图像强度成正比,并且不同像素处的噪声时独立的。
- Resize(Downsampling)(下采样):
- 调整图像格式一般分为下采样和上采样
- 常见的调整算法有:
- 最近邻域插值、区域调整、双线性插值和双三次插值。
- 但是最近邻域插值会引入misalignment,因此本文只考虑后三种算法。
- JPEG compression(JPEG压缩):
- JPEG压缩是一种常用的数字图像有损压缩技术。
- 具体过程如下:
- 首先,将图像转换为YCbCr颜色空间并对色度空间进行下采样。
- 然后将图像分割为8 × 8块,每个块均使用二维离散预先变换(DCT)进行变换,然后对DCT系数进行量化。
- JPEG压缩通常会引入令人不快的块伪影。
- 压缩图像的质量由质量因数 q ∈ \in ∈ [0; 100] 决定,其中 q 越低表示压缩比越高,质量越差。
3.2 高阶退化模型
- 采用上述经典退化模型来合成训练对时的缺陷:
- 也被称之为一阶退化模型:
- 因为其仅包含固定数量的基本退化。
- 虽然训练后的模型确实可以处理一些真实样本。
- 然而,它仍然无法解决现实世界中的一些复杂的退化问题,特别是未知的噪声和复杂的伪影。
- 这是因为合成的低分辨率图像与真实的退化图像仍然存在很大差距。
- 也被称之为一阶退化模型:
- 高阶退化过程:
- n阶模型涉及n个重复的退化过程,每个退化过程均采用用经典退化模型,过程相同,但超参数不同。
- ”高阶“:同一操作的执行次数。
- 表达式: x = D n ( y ) = ( D n ∘ ⋅ ⋅ ⋅ ∘ D 2 ∘ D 1 ) ( y ) ( 4 ) x = \mathcal D^n(y)=(\mathcal D_n\circ···\circ\mathcal D_2\circ \mathcal D_1)(y)\quad\quad(4) x=Dn(y)=(Dn∘⋅⋅⋅∘D2∘D1)(y)(4)
- 修改:
- 虽然高阶退化是关键,但是经典退化的所有步骤并不全需要
- 将下采样操作替换为随机调整图像大小操作。
- 采用二阶降级过程:
- 因为它可以解决大多数实际情况,同时保持简单性
- 二阶退化过程:
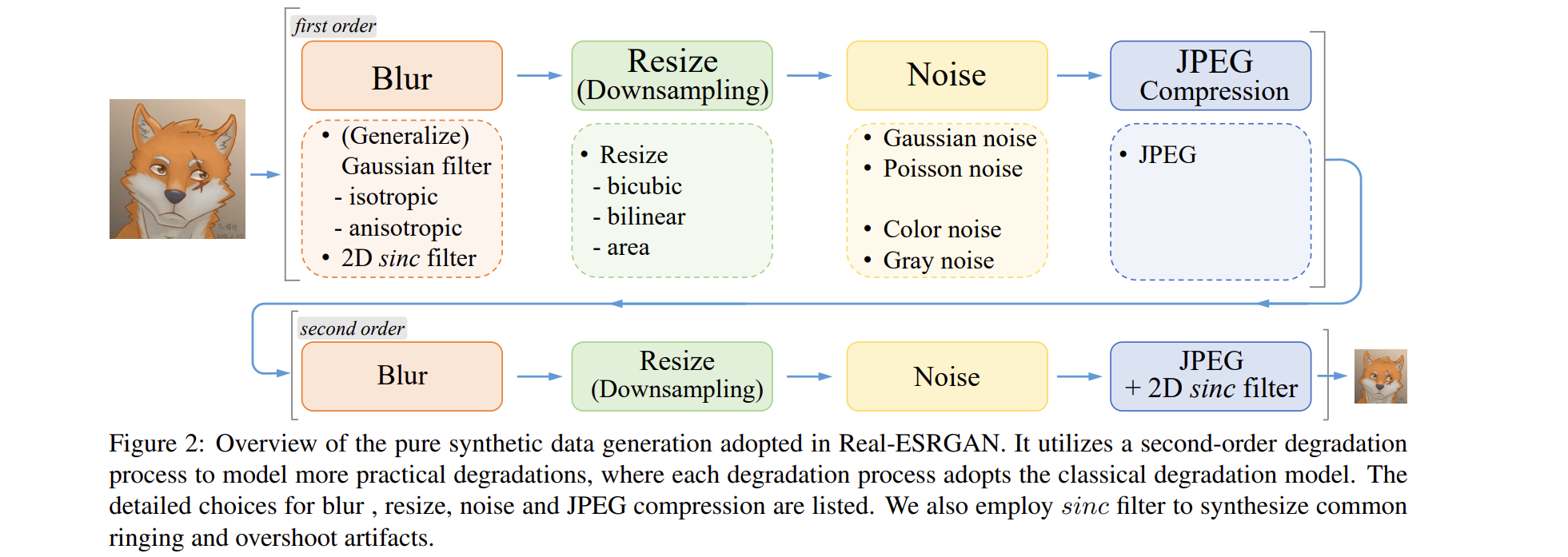
- 限制:
- 改进的高阶退化过程并不完美,无法覆盖现实世界中的整个退化空间。
- 相反,它只是通过修改数据合成过程来扩展先前盲SR方法的可解退化边界。
3.3 振铃伪影和过冲伪影
- 概念:
- 振铃伪影:
- 通常表现为图像中锐过渡附近的虚假边缘。
- 它们在视觉上看起来就像边缘附近的带子或“幽灵”。
- 过冲伪影:
- 过冲伪影通常与振铃伪影结合在一起。
- 通常表现为边缘过渡处跳跃的增加(看起来像“锯齿”)。
- 产生原因:
- 主要原因是信号受带宽限制,没有高频。
- 这些伪影非常常见并且通常由锐化算法、JPEG压缩产生。
- 振铃伪影:
- sinc滤波器:
- 一种截止高频的理想化滤波器。
- 目的是,来合成训练对的振铃和过冲伪影。
- sinc滤波器的表达式: k ( i , j ) = ω c 2 π i 2 + j 2 J 1 ( ω c i 2 + j 2 ) ( 5 ) k(i, j) = \frac{\omega_c}{2\pi\sqrt{i^2+j^2}}J_1(\omega_c\sqrt{i^2+j^2})\quad\quad\quad(5) k(i,j)=2πi2+j2ωcJ1(ωci2+j2)(5)
- 其中:(i,j):核坐标 ω c \omega_c ωc:截止频率 J 1 J_1 J1:第一类贝塞尔函数
- 在两个地方使用sinc滤波器:
-
- 模糊过程
-
- 合成SR的最后一步:
- 最后一个 sinc 滤波器和 JPEG 压缩的顺序是随机交换的,以覆盖更大的降级空间。
-
3.4 网络和训练
-
ESRGAN 生成器:
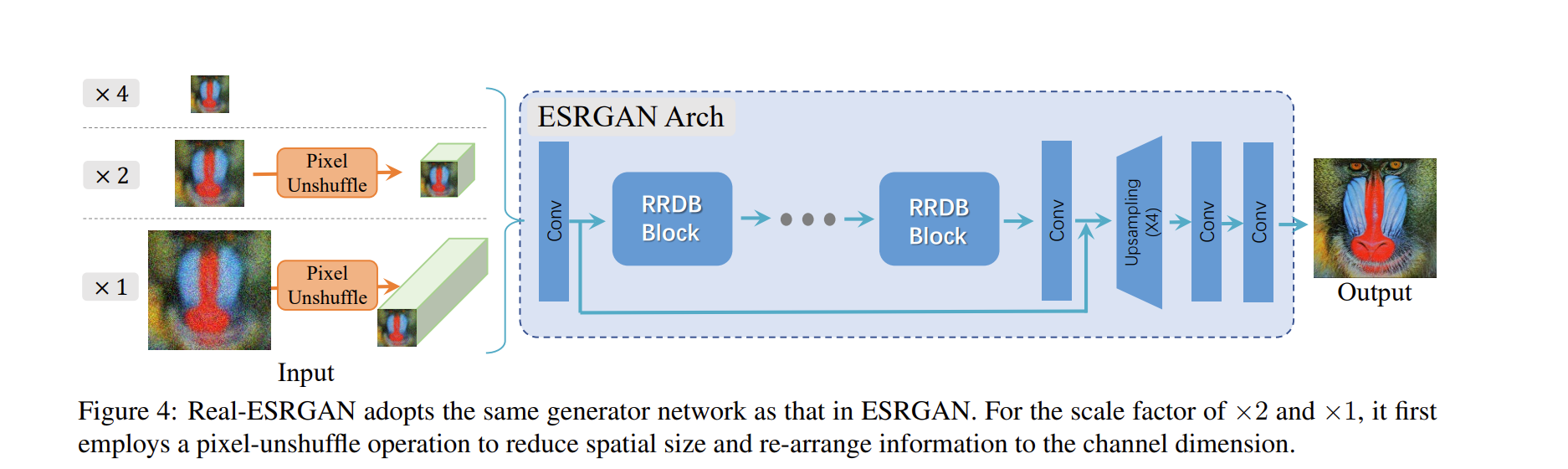
- 采用与ESRGAN相同的生成器网络
- 改进:
- 将原始的×4架构,扩展到×2、×1。
- 在输入ESRGAN网络之前,首先采用 Pixel-unshuffle(pixelshuffle 的逆操作)来减小空间尺寸并扩大通道尺寸。这样,大部分计算都在较小的分辨率空间中进行,可以减少GPU内存和计算资源的消耗。
-
U-Net discriminator with spectral normalization(SN)
-
(具有光谱归一化的U-Net鉴别器):
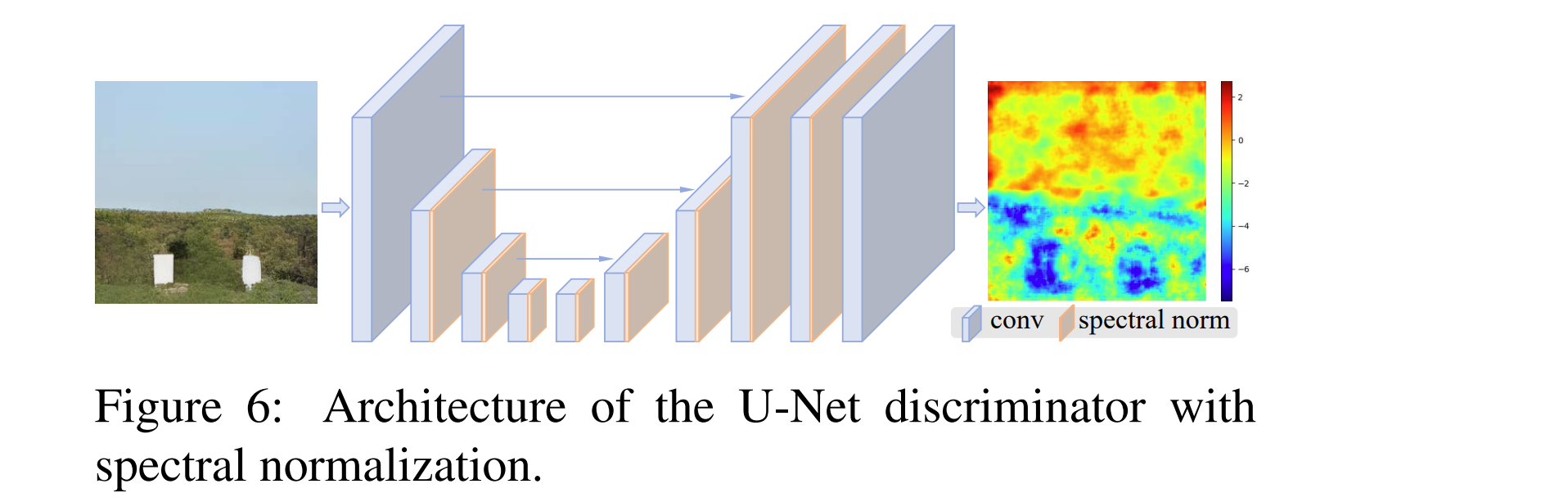
- 改进:
- 将ESRGAN中的VGG式判别网络改进为具有skip connections的U-Net。
- 改进原因:
- Real-ESRGAN有更大的退化空间,因此对于复杂的训练输出需要更大的判别器能力,它不仅需要区分全局样式,还需要为局部纹理产生准确的梯度反馈。
- U-Net输出每个像素的真实值,并且可以向生成器提供详细的像素反馈。
- 存在问题:
- U-Net结构和复杂的退化也增加了训练的不稳定性。
- 进一步改进:
- 我们采用谱归一化正则化来稳定训练动态。
- 优势:
- 光谱归一化正则化也有利于缓解GAN训练中引入的过度锐化和烦人的伪影。
- 改进:
-
使用带有SN的U-Net的优势:
- 能够轻松训练 Real-ESRGAN
- 并实现局部细节增强和伪像抑制的良好平衡。
实验
训练过程
- The training process(训练过程):
- 整个训练过程分为两个阶段:
- 首先,训练具有 L1 损失的基于PSNR的模型。得到的模型被命名为Real-ESRNet。
- 然后,使用训练好的基于PSNR的模型作为生成器的初始化,并结合 L1 损失、感知损失和 GAN 损失来训练 Real-ESRGAN。
- sharpening ground-truth images during training------Real-ESRGAN+

评价指标—NIQE

- 整个训练过程分为两个阶段:
局限性
(1)生成的SR图像(尤其是建筑物和室内场景)由于锯齿问题而出现扭曲的线条。
(2)由于主干网络是GAN网络,对于某些样本,仍然会生成伪影。
(3)无法消除现实世界中分布外的复杂退化,甚至会放大这些伪影。
结论
作者使用纯合成训练对来训练 Real-ESRGAN,用于现实世界的盲超分辨率。
1. 为了合成更实用的退化,提出了一种高阶退化过程,并采用 sinc 滤波器来模拟常见的振铃和过冲伪影。
2. 利用具有谱归一化正则化的 U-Net 判别器,来提高判别器能力并稳定训练动态。
3. 使用合成数据训练的 Real-ESRGAN 能够增强细节,同时消除大多数现实世界图像中的伪影。

















 7887
7887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









