







pytorch官网:https://pytorch.org/tutorials/
pyorch中的tensor译作“张量”,简单理解,就是 多维数组 ,与numpy中的ndarray非常相似。
既然是深度学习的工具,tensor还具有 自动求梯度 和 GPU计算 等强大功能。
常用操作
创建tensor:
torch.tensor([[1,2],[3,4]]) 直接根据数据创建
torch.empty(2, 3) 创建一个 未初始化的tensor
torch.zeros(2, 3, dtype=torch.long) 创建一个long型全0tensor
torch.rand(2, 3) 创建一个随机初始化的tensor
x = x.new_ones(2, 3) 通过现有的tensor创建新tensor,创建的新tensor具有相同的torch.dtype和torch.device
x = torch.randn_like(x, dtype=torch.float) 指定新的数据类型
获取tensor的形状:
x.shape --> tensor属性
x.size() --> tendor方法
其他函数:
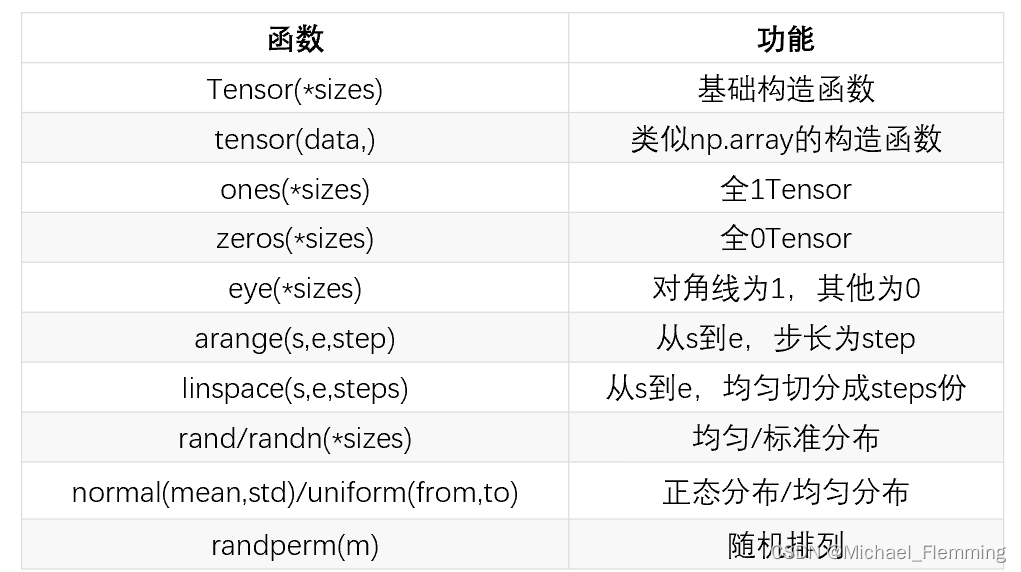
算数操作:
- x+y
- x.add(y)
有关索引:
支持方括号切片索引:y = x[:,0]
函数:

改变形状:
1.view()
y = x.view(6)
y = x.view(-1, 2)
注:该方法的返回与原tensor共享data,即view仅仅从观察角度改变了张量,内部数据并未改变。所以当更改其中一个tensor时,另一个tensor也会跟着改变。
2.reshape()
此函数并不能保证返回的是其拷贝,不推荐。
3.clone()+view()
推荐,先使用clone()方法创建一个副本,再用view()改变形状。
一些与线性代数有关的运算函数:

tensor也有广播机制。
tensor与ndarray相互转换:
- tensor转ndarray : x = torch.ones(3); y = x.numpy()
- numpy转tensor : torch.from_numpy()
注意:以上两种方式tensor和ndarray共享内存!! 即,其中一个改变,另一个也会跟着改变。 - torch.tensor()也可以将ndarray转换成tensor,但是不共享内存,是产生copy(消耗更多时间和空间)。
CPU与GPU之间移动:
x.to(“cpu”,torch.double)
自动求梯度
pytorch提供的autograd包能够根据输入和前向传播过程自动构建计算图,并执行反向传播。

创建一个tensor x,设置其属性requires_grad=True,在接下来关于x的运算中,就会创建计算图,是用grad_fn属性所记录的,这个属性其实就是一个Function对象。
创建完了计算图,就可以求梯度了,需要首先调用y.backward()进行反向传播。然后再获取x的grad属性,就是梯度了。
- 可以使用方法 .requires_grad(True/False)来修改tensor对象的requires_grad属性。
注意:grad在反向传播的过程中是累加的,意味着每一次运行反向传播,都会累加之前的梯度。所以,一般在反向传播之前需要把梯度清零。 x.grad.data.zero_()
注意:y.backward()时,y只能是标量,否则需要传入一个与y同行的tensor,使其变成标量。无法完成向量对向量的求导。只能完成标量对向量求导。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









