






一、题目分析
题目要求:编写原生Python代码实现KNN算法,并用鸢尾花数据集进行测试。
题目分析:
1.KNN算法
KNN(K-Nearest Neighbor)算法也称K近邻算法,是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归。
KNN分类算法:
原理:它的工作原理是利用训练数据对特征向量空间进行划分,并将划分结果作为最终算法模型。存在一个样本数据集合,也称作训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的数据后,将这个没有标签的数据的每个特征与样本集中的数据对应的特征进行比较,然后提取样本中特征最相近的数据(最近邻)的分类标签。
KNN分类算法的分类预测过程十分简单并容易理解:对于一个需要预测的输入向量x,我们只需要在训练数据集中寻找k个与向量x最近的向量的集合,然后把x的类别预测为这k个样本中类别数最多的那一类。
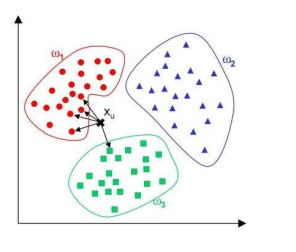
如图所示,ω1、ω2、ω3分别代表训练集中的三个类别。其中,与xu最相近的5个点(k=5)如图中箭头所指,很明显与其最相近的5个点中最多的类别为ω1,因此,KNN算法将xu的类别预测为ω1。
2.鸢尾花数据集
鸢尾花(iris)数据集,是机器学习和统计学中一个经典的数据集,它包含在scikit-learn的datasets模块中,我们可以通过调用load_iris函数来加载数据。
二、算法设计
1.knn.py
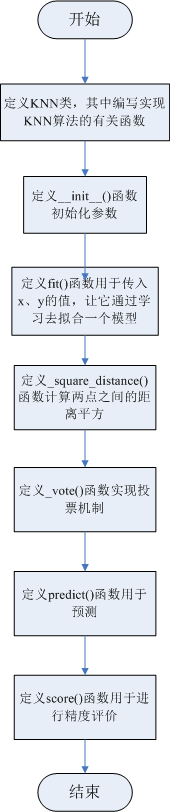
2.train.py

三、源代码
#knn.py文件用于实现knn算法的内部实现函数
import numpy as np
import operator
#KNN分类器
class KNN(object):
def __init__(self, k = 3): #变量k的默认值为3,表示找出输入向量最近的三个邻居进行类型推测
self.k = k
#fit()函数用于传入x、y的值,让它通过学习去拟合一个模型
def fit(self, x, y):
self.x = x
self.y = y
#_square_distance()函数计算两点之间的距离平方
def _square_distance(self, v1, v2):
return np.sum(np.square(v1 - v2))
#_vote()函数实现投票机制
def _vote(self, ys):
ys_unique = np.unique(ys) #由于传入的样本点的类型可能重复,所以对传入的top_k个y值取其唯一值
vote_dict = {}
for y in ys:
if y not in vote_dict.keys():
vote_dict[y] = 1
else:
vote_dict[y] += 1
sorted_vote_dict = sorted(vote_dict.items(), key = operator.itemgetter(1), reverse = True)
return sorted_vote_dict[0][0]
#predict()函数用于预测
def predict(self, x):
y_pred = []
#通过循环在训练集中找出与输入向量最近的k个点
for i in range(len(x)):
#计算输入向量与训练集中每一个训练样点之间的距离,并放入dist_arr数组中
dist_arr = [self._square_distance(x[i], self.x[j]) for j in range(len(self.x))]
sorted_index = np.argsort(dist_arr) #对dist_arr数组从小到大进行排序
top_k_index = sorted_index[:self.k] #提取top_k_index
y_pred.append(self._vote(ys = self.y[top_k_index])) #推测值ys = self.y[top_k_index]
return np.array(y_pred)
#score()函数用于进行精度评价
def score(self, y_true = None, y_pred = None):
if y_true is None or y_pred is None:
y_pred = self.predict(self.x)
y_true = self.y
score = 0.0 #精度初值设为0.0
for i in range(len(y_true)):
#如果预测值与真实值相等,精度加一
if y_true[i] == y_pred[i]:
score += 1
score /= len(y_true) #除以长度得到正确率
return score#train.py文件用于生成鸢尾花数据集,通过调用knn.py文件中实现的knn算法实现分类,完成精度评价
from knn import KNN #导入实现的KNN包
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
#通过调用load_iris()函数来加载鸢尾花数据集
iris_dataset = load_iris()
print("查看鸢尾花数据集:\n", iris_dataset.data)
print("查看鸢尾花特征值:\n", iris_dataset.target)
print("查看鸢尾花品种:\n", iris_dataset.target_names)
#按照一定比例分割测试集与训练集
x_train, x_test, y_train, y_test = train_test_split(iris_dataset.data, iris_dataset.target, test_size=0.4,random_state=0)
#考虑到每一个数据的量纲问题,我们采用归一化将数据归一到0和1之间,提高精度
x_train = (x_train - np.min(x_train, axis=0)) / (np.max(x_train, axis=0) - np.min(x_train, axis=0))
x_test = (x_test - np.min(x_test, axis=0)) / (np.max(x_test, axis=0) - np.min(x_test, axis=0))
clf = KNN(k=3)
clf.fit(x_train,y_train) #调用fit()函数传值
score_train = clf.score() #调用score()函数计算训练集的精度
print('train accuracy:{:.3}'.format(score_train))
y_test_pred = clf.predict(x_test) #调用score()函数计算测试集的精度
print('test accuracy:{:.3}'.format(clf.score(y_test,y_test_pred)))四、测试、调试及运行结果
测试代码:

测试结果:

调试结果:

运行结果:

参考:
1.什么是KNN算法?
https://blog.csdn.net/hajk2017/article/details/82862788
2.机器学习_knn算法介绍与python实现
https://www.bilibili.com/video/av52220223?from=search&seid=17347210328131604318














 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









