






一.作业题目
Python原生代码实现KNN分类算法,使用鸢尾花数据集。
KNN算法介绍:
K最近邻(k-Nearest Neighbor,KNN)分类算法,是机器学习算法之一。
该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
二.算法设计
步骤:
1.创建数据集,分为训练数据和测试数据;
(本例直接使用sklearn库中的iris数据集)
2.Python编写knn分类器;
3.创建knn分类器对象;
4.向分类器对象传入训练集x_train,y_train;
5.向分类器对象传入测试集x_test,用训练集进行预测,得出y_test。
knn分类器算法设计:
主要分为如下函数:
1.k值的传入__init__(self, k=3);
2.训练集的传入fit(self, x, y);
3.两点间距离平方的计算_square_distance(self,
v1, v2);
4.投票机制_vote_(self,
ys);
5.预测测试集的特征值predict(self,
x);
6.输出测试集特征值的名字classify(self,x_test,y_test_pred);
7.计算数据集的精度score(self,
y_true=None, y_pred=None)。
三.源代码
主要分为三部分:
-
测试代码; -
测试集,数据集的划分以及knn分类器的调用; -
knn分类器。
源代码:
-
测试代码(测试代码.py)
# 导入鸢尾花数据集
from
sklearn.datasets import load_iris
# 导入knn分类器
from knn import *
# iris:鸢尾花数据集
iris = load_iris()
print("查看鸢尾花数据集的特征:\n",iris.data)
print("查看特征值:\n",
iris.target)
print("查看特征值的名字:\n",
iris.target_names)
# iris数据集作为训练集
x_train = iris.data
y_train =
iris.target
# 测试数据
x_test =[[6.5,5.2,1.8,0.7],[3.2,2.2,3.8,0.2],[6.5,4.1,2.4,1.3]]
# knn classifier
clf = KNN(k=3)
# 把x_train,y_train传进去
clf.fit(x_train,y_train)
# 传入测试集,与训练集进行比较,得到其预测值
y_test_pred =
clf.predict(x_test)
# 得到测试鸢尾花特征值名字,即类别
clf.classify(y_test_pred)
- 测试集,数据集的划分以及knn分类器的调用;(train_test.py)
# 导入导入鸢尾花数据集
rom sklearn.datasets import load_iris
# train_test_split函数:按比例划分训练集,测试集
from sklearn.model_selection import train_test_split
# 导入knn分类器
from knn import *
# iris:鸢尾花数据集
iris = load_iris()
# random_state就是为了保证程序每次运行都分割一样的训练集和测试集
x_train, x_test, y_train, y_test =
train_test_split(iris.data, iris.target, test_size=0.4,random_state=0)
# data preprocessing归一化
x_train = (x_train - np.min(x_train,axis=0)) /
(np.max(x_train,axis=0) - np.min(x_train,axis=0))
x_test = (x_test - np.min(x_test,axis=0)) /
(np.max(x_test,axis=0) - np.min(x_test,axis=0))
# knn classifier
clf = KNN(k=3)
# 把x_train,y_train传进去
clf.fit(x_train,y_train)
# 得到训练集的精度
score_train = clf.score()
# 保留三位小数输出
print('train accuracy:{:.3}'.format(score_train))
# 传入测试集,与训练集进行比较,得到其预测值
y_test_pred = clf.predict(x_test)
# 得到测试集的精度,并保留三位小数
print('test accuracy:
{:.3}'.format(clf.score(y_test,y_test_pred)))
# 得到测试鸢尾花特征值名字,即类别
clf.classify(x_test,y_test_pred)
- knn分类器(knn.py)
# 科学计算库
import numpy as np
# 提供一系列函数操作
import operator
# knn分类器
class KNN(object):
# k:临近数,即在预测目标点时取几个临近的点来预测
def __init__(self, k=3):
self.k = k
def fit(self, x, y):
self.x = x
self.y = y
# 计算任意两点的距离的平方
def _square_distance(self, v1, v2):
return np.sum(np.square(v1-v2))
# 投票机制
def _vote_(self, ys):
# 取ys得唯一值
ys_unique = np.unique(ys)
# 字典
vote_dict = {}
for y in ys:
if y not in vote_dict.keys():
vote_dict[y] = 1
else:
vote_dict[y] += 1
sorted_vote_dict =
sorted(vote_dict.items(), key=operator.itemgetter(1), reverse=True)
# 返回最大的值
return sorted_vote_dict[0][0]
def predict(self, x):
y_pred = []
for i in range(len(x)):
# 当前x[i]和所有训练样点的平方距离,保存在dist_arr数组中
dist_arr =
[self._square_distance(x[i], self.x[j]) for j in range(len(self.x))]
# 排序索引数组
sorted_index=
sorted_index = np.argsort(dist_arr)
# 提取从开始到self.k的索引数组,保存在top_k_index数组中
top_k_index = sorted_index[:self.k]
# 向y_pred数组中添加
y_pred.append(self._vote_(ys=self.y[top_k_index]))
# 返回生成矩阵
return np.array(y_pred)
# 计算精度
def score(self, y_true=None, y_pred=None):
if y_true is None or y_pred is None:
y_pred = self.predict(self.x)
y_true = self.y
score = 0.0
for i in range(len(y_true)):
if y_true[i] == y_pred[i]:
score += 1
# 计算正确率
score /= len(y_true)
return score
#测试集特征值名字
def classify(self,y_test_pred):
classification =['setosa','versicolor' ,'virginica']
print("测试集:")
print("target target_names")
for i in y_test_pred:
if y_test_pred[i] == 0:
print(y_test_pred[i],' ',classification[0])
if y_test_pred[i] == 1:
print(y_test_pred[i],' ',classification[1])
if y_test_pred[i] == 2:
print(y_test_pred[i],' ',classification[2])
四.测试用例设计及调试过程截屏
1.测试用例
(1)鸢尾花数据集的测试

(一共150组数据)
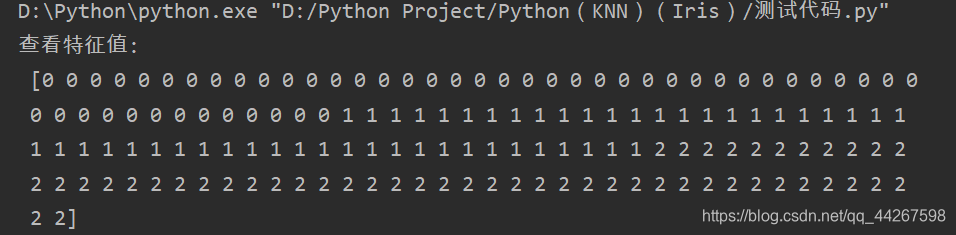

(2)测试集的创建及预测
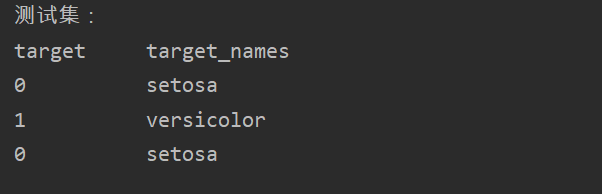
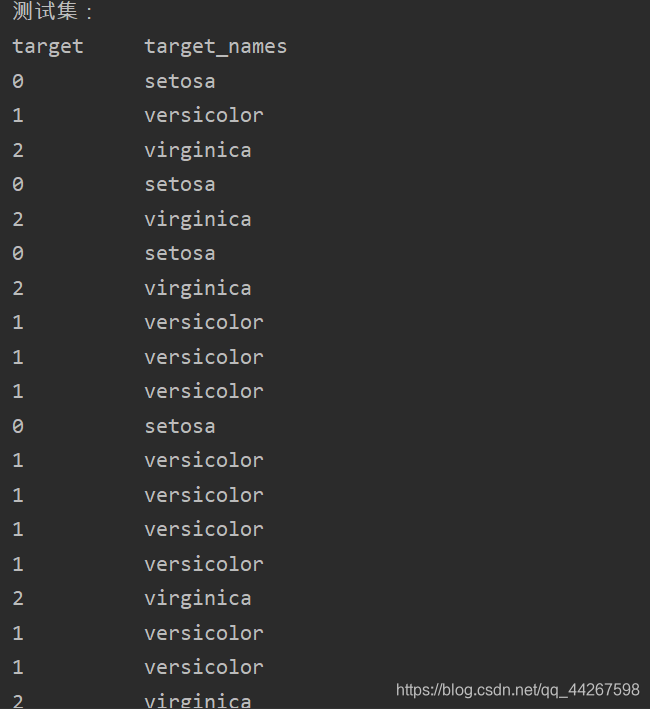
2.训练集,测试集的划分以及knn分类器的调用
(1)训练集,测试集的精度

(2)测试集特征值名字的预测(40%,共60组)
五.个人总结














 2378
2378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









