







RexUIE: A Recursive Method with Explicit Schema Instructor for Universal Information Extraction
RexUIE:带有显式模式指示器的递归方法,用于通用信息提取
paper: https://arxiv.org/pdf/2304.14770
github: modelscope
文章目录~
1.背景动机
之前多IE模型的缺陷:
现有的大部分模型只是统一了NER和RE等少数任务,但是:
- 忽略了2个以上跨度的抽取,如四重和五重,因此不能成为真正的UIE模型。
- 以往的 UIE 模型没有明确利用提取模式来限制结果。忽略明确的模式可能会导致虚假的结果,妨碍模型在资源有限的情况下的泛化和性能。
本文提出的UIE模型:
- 在本文中,通过一个全面的形式框架重新定义了通用信息提取(UIE),该框架几乎涵盖了所有提取模式。
- 介绍RexUIE,它是一种针对UIE的带有显式模式指导器的递归方法:RexUIE对所有模式类型进行递归查询,并利用三种统一的标记链接操作来计算每次查询的结果。根据先前提取的跨度和分层模式构建一个显式模式指导器(ESI),为 RexUIE 提供标签语义信息,并确保提取结果符合模式约束。ESI 与文本连接形成查询。
2.Model
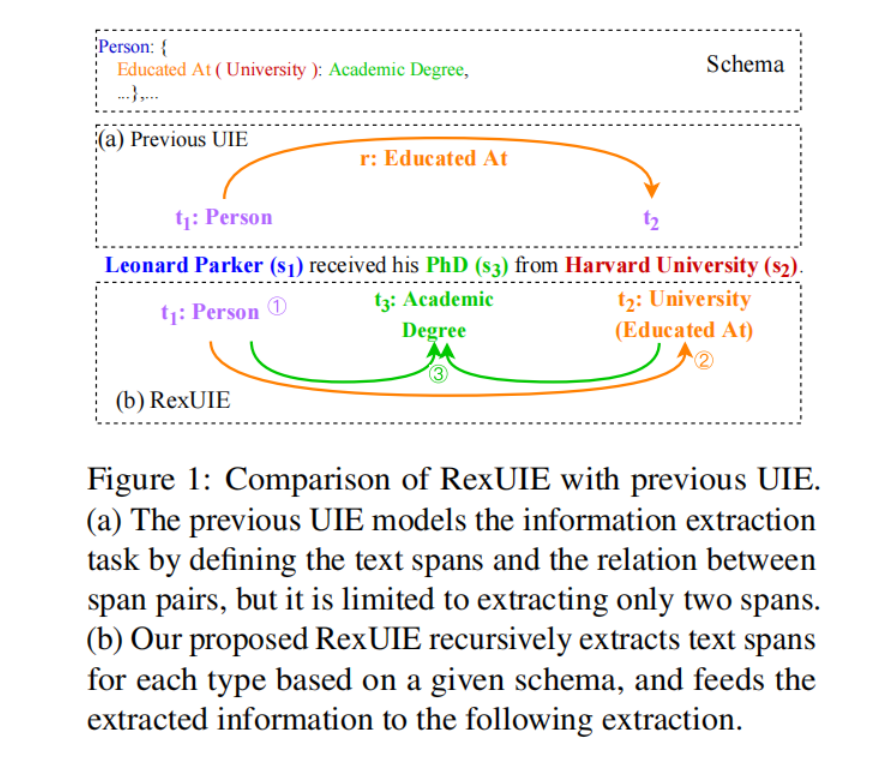
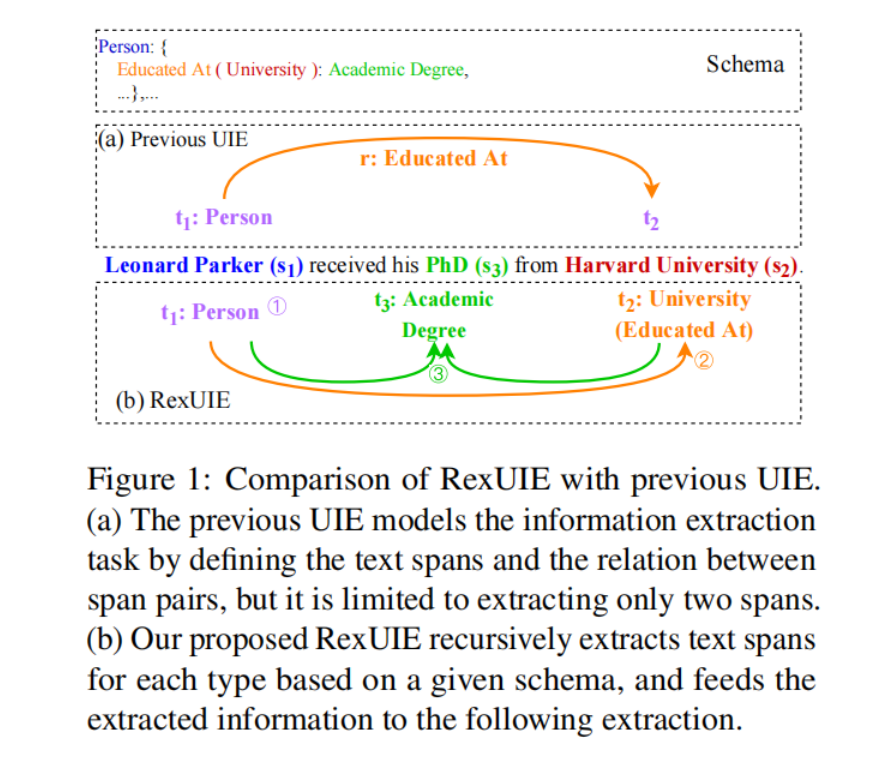
以图为例,解释RexUIE的工作原理:
以图 1(b)为例,在给定提取模式的情况下,RexUIE 首先提取出 “Leonard Parker”,将其归类为 “Person”,然后根据模式提取出 “Harvard University”,将其归类为 “University”,再加上 "Educated At "关系。第三,根据检索到的图元(“Leonard Parker”,“Person” )和(“Harvard University”,“Educated At (University)” ),RexUIE 导出了分类为 "学术学位 "的跨度 “PhD”。RexUIE 根据模式以递归方式提取跨度,允许提取两个以上的跨度,如四重和五重跨度,而不是仅限于成对的跨度及其关系。
对UIE的重新定义:
真正的 UIE 从文本中提取结构化信息的集合,每个项目由 n n n 跨度 s = [ s 1 , s 2 , . . . , s n ] s=[s_1,s_2,...,s_n] s=[s1,s2,...,sn]和 n n n 相应的类型 t = [ t 1 , t 2 , . . . , t n ] t=[t_1,t_2,...,t_n] t=[t1,t2,...,tn]组成。跨度是从文本中提取的,而类型则由给定的模式定义。每一对 ( s i , t i ) (s_i,t_i) (si,ti)都是要提取的目标。
框架具体流程:
1.送入encoder中获取embedding:
RexUIE 对所有模式类型进行递归查询。给定第i个查询
Q
i
Q_{i}
Qi,我们采用预训练好的语言模型作为编码器,将标记映射到隐藏表示
h
i
∈
R
n
×
d
h_{i}\in\mathbb{R}^{n\times d}
hi∈Rn×d,其中
n
n
n 是查询的长度,
d
d
d 是隐藏状态的维度、
h
i
=
E
n
c
o
d
e
r
(
Q
i
,
P
i
,
M
i
)
(2)
hi=\mathbf{Encoder}(Q_{i},P_{i},M_{i}) \tag{2}
hi=Encoder(Qi,Pi,Mi)(2)
其中
P
i
P_{i}
Pi 和
M
i
M_{i}
Mi 分别表示
Q
i
Q_{i}
Qi 的位置标识和注意力掩码矩阵。
2.将embedding送入两个全连接层:
然后,将隐藏状态输入两个前馈神经网络 F F N N q , F F N N k \mathbf{FFNN}_{q},\mathbf{FFNN}_{k} FFNNq,FFNNk 。
3.计算隐藏向量的rope旋转矩阵:
接下来,应用旋转嵌入计算得分矩阵
Z
i
Z_{i}
Zi。
Z
i
j
,
k
=
(
F
F
N
N
q
(
h
i
j
)
⊤
R
(
P
i
k
−
P
i
j
)
F
F
N
N
k
(
h
i
k
)
)
⊗
M
i
j
,
k
(3)
\begin{split}Z_{i}^{j,k}=(\mathbf{FFNN}_{q}(h_{i}^{j})^{\top}\mathbf{R}(P_{i}^{k}-P_{i}^{j}) \mathbf{FFNN}_{k}(h_{i}^{k}))\otimes M_{i}^{j,k}\end{split}\tag{3}
Zij,k=(FFNNq(hij)⊤R(Pik−Pij)FFNNk(hik))⊗Mij,k(3)
其中,
M
i
j
,
k
M_{i}^{j,k}
Mij,k 和
Z
i
j
,
k
Z_{i}^{j,k}
Zij,k 分别表示令牌
j
j
j 到
k
k
k 之间的mask值和得分。
P
i
j
P_{i}^{j}
Pij 和
P
i
k
P_{i}^{k}
Pik 表示标记
j
j
j 和
k
k
k 的位置 id。
⊗
\otimes
⊗ 是 Hadamard 积。
R
(
P
i
k
−
P
i
j
)
∈
R
d
×
d
\mathbf{R}(P_{i}^{k}-P_{i}^{j})\in\mathbb{R}^{d\times d}
R(Pik−Pij)∈Rd×d 表示旋转位置嵌入(RoPE)
4.解码旋转矩阵,即通过指针找到对应span的开头、结尾和类型:
最后,解码得分矩阵 Z i Z_{i} Zi 以获得输出 Y i Y_{i} Yi,并利用它创建后续查询 Q i + 1 Q_{i+1} Qi+1。所有最终输出都会合并为结果集 Y = { Y 1 , Y 2 , … } \mathcal{Y}=\{Y_{1},Y_{2},\dots\} Y={Y1,Y2,…} 。
5.loss:
使用Circle损失作为 RexUIE 的损失函数,它在计算稀疏矩阵的损失方面非常有效
L
i
=
log
(
1
+
∑
Z
^
i
j
=
0
e
Z
‾
i
j
)
+
log
(
1
+
∑
Z
^
i
k
=
1
e
−
Z
‾
i
k
)
L
=
∑
i
L
i
(4)
\begin{split}\mathcal{L}_{i}=\log(1+\sum_{\hat{Z}_{i}^{j}=0}e^{ \overline{Z}_{i}^{j}})+\log(1+\sum_{\hat{Z}_{i}^{k}=1}e^{-\overline{Z}_{i}^{k }})\\ \mathcal{L}=\sum_{i}\mathcal{L}_{i}\end{split}\tag{4}
Li=log(1+Z^ij=0∑eZij)+log(1+Z^ik=1∑e−Zik)L=i∑Li(4)
其中,
Z
‾
i
\overline{Z}_{i}
Zi 是
Z
i
Z_{i}
Zi 的扁平化版本,
Z
^
i
\hat{Z}_{i}
Z^i 表示扁平化的ground truth,只包含 1 和 0。
输入的显示模式指令构造:
第 i i i 次查询 Q i Q_{i} Qi 由一个显式模式指示器(ESI)和文本 x x x 组成。ESI是前缀 p i p_{i} pi和类型 t i = [ t i 1 , t i 2 , … ] t_{i}=[t_{i}^{1},t_{i}^{2},\dots] ti=[ti1,ti2,…]的连接。前缀 p i p_{i} pi 模拟了等式 1 中的 ( s , t ) < i (\mathbf{s},\mathbf{t})_{<i} (s,t)<i, t i t_{i} ti 指定了在给定 p i p_{i} pi 的情况下,可以从 x x x 中识别出哪些类型。
在每个前缀前插入一个特殊标记 [P],在每个类型前插入一个 [T]。此外,我们还在文本 x x x 前插入一个标记 [Text]。那么,输入的 Q i Q_{i} Qi 可以表示为
Q
i
=
[CLS][P]
p
i
[T]
t
i
1
[T]
t
i
2
…
[Text]
x
0
x
1
…
(5)
Q_{i}=\texttt{[CLS][P]}p_{i}\texttt{[T]}t_{i}^{1}\texttt{[T]}t_{i}^{2}\ldots \texttt{[Text]}x_{0}x_{1}\ldots \tag{5}
Qi=[CLS][P]pi[T]ti1[T]ti2…[Text]x0x1…(5)
对于先前提取的跨度和相应的类型,使用": “来连接跨度和类型,使用”, "来连接先前每次查询的结果,从而根据模式构建前缀。因此,通过递归查询到模式中的最后一个类型,RexUIE 可以提取包括四元组和五元组在内的各种模式。我们用模式第一层的类型构建
Q
0
Q_{0}
Q0,作为对模型的初始查询。特别说明的是,前缀
p
0
p_{0}
p0 是空序列。
三个token链接指针:
给定计算出的分数矩阵
Z
Z
Z,通过一个预定义的阈值
δ
\delta
δ 从
Z
Z
Z 中得到
Z
~
\tilde{Z}
Z~ ,如下所示
Z
~
i
,
j
=
{
1
if
Z
i
,
j
≥
δ
0
otherwise
(6)
\tilde{Z}^{i,j}=\begin{cases}1&\text{if }Z^{i,j}\geq\delta\\ 0&\text{otherwise}\end{cases}\tag{6}
Z~i,j={10if Zi,j≥δotherwise(6)
只有当
Z
~
i
,
j
=
1
\tilde{Z}^{i,j}=1
Z~i,j=1 时,从
i
i
i 的第 1 个token到
j
j
j 的第 1 个token之间才能建立令牌链接;否则,不存在链接。
1.Token Head-Tail Linking:
第一个是token头部-尾部链接:用于标识一个span对应的头部和尾部位置,并对其进行组合
2.Token Head-Type Linking:
第二个是token头部-类型链接:用于标识span的头部和Span的类型,Span的起始token与其对应类型前插入的特殊token[T]相链接
- Type-Token Tail Linking:
第三个类型token-尾部链接:用于标识Span的尾部和Span的类型,Span的最后一个token与其对应类型前插入的特殊token [T]相链接
类型分割,以防止无关的类型相互干扰:
提出了 “提示隔离”(Prompts Isolation)方法,这种方法可以减少不同类型和前缀的标记之间的干扰。通过修改标记符类型ids、位置ids和注意力掩码,这些标记符之间的直接信息流被有效阻断,从而能够清晰地区分 ESI 中的不同部分,使得每个类型令牌只能与其自身、相应的前缀和文本进行信息交互。
3.相关NLU任务
实体识别:
{实体类型: None}
关系抽取:
{主语实体类型: {关系(宾语实体类型): None}}
事件抽取:
{事件类型(事件触发词): {参数类型: None}}
情感分析:
{属性词: {情感词: None}}
正文前添加[CLASSIFY],schema列举期望抽取的候选“情感倾向标签”;同时也支持情绪分类任务,换成相应情绪标签即可,e.g. "无情绪,积极,愤怒,悲伤,恐惧,惊奇"
文本分类:
{主语实体类型: {关系(宾语实体类型): None}}
多标签文本分类:
正文前添加[MULTICLASSIFY],schema列举期望抽取的候选“文本分类标签”
层次分类:
正文前添加[CLASSIFY]或者[MULTICLASSIFY](多标签层次分类),schema按照标签层级构造 {层级1标签: {层级2标签: None}}
…
4.原文阅读
Abstract
通用信息提取(UIE)是一个备受关注的领域,因为不同的目标、异构结构和特定需求的模式都带来了挑战。然而,以前的工作只是通过统一少数任务(如命名实体识别(NER)和关系提取(RE))取得了有限的成功,任务还不足以成为真正的通用信息提取模型,尤其是在提取其他通用模式(如四元和五元)时。此外,这些模型使用的是隐式结构模式指示器,这可能会导致类型之间的链接不正确,从而阻碍模型在低资源场景中的泛化和性能。在本文中,我们用一种正式的表述方式重新定义了真实的 UIE,它几乎涵盖了所有的提取模式。据我们所知,我们是第一个为任何模式引入 UIE 的人。此外,我们还提出了RexUIE,这是一种针对 UIE 的带有显式模式指导器的递归方法。为了避免不同类型之间的干扰,我们重置了位置id和注意力掩码矩阵。RexUIE 在full-shot和few-shot设置下都表现出很强的性能,并在提取复杂图式的任务中取得了最先进的结果。
1 Introduction
作为自然语言理解的一项基本任务,信息提取(IE)已被广泛研究,如命名实体识别(NER)、关系提取(RE)、事件提取(EE)、基于方面的情感分析(ABSA)等。然而,针对特定任务的模型结构阻碍了信息获取领域的知识和结构共享。
多IE任务的发展:
最近的一些研究试图将 NER、RE 和 EE 一起建模,以利用子任务之间的依赖关系。Lin 等人和 Nguyen 等人通过图神经网络对跨任务依赖性进行了建模。另一个成功的尝试是通用信息提取(UIE)。Lu 等人设计了新颖的结构模式指示器(SSI)作为输入,结构化提取语言(SEL)作为输出,并提出了基于 T5-Large 的统一文本到结构生成框架。Lou 等人则引入了三种统一的标记链接操作,统一并行提取子结构,在 IE 任务上实现了新的 SoTA。
之前多IE模型的缺陷:
然而,它们只是统一了命名实体识别(NER)和关系抽取(RE)等少数任务,取得了有限的成功,但是:
- 忽略了2个以上跨度的抽取,如四重和五重,因此不能成为真正的UIE模型。如图 1 (a)所示,以往的 UIE 只能提取一对跨度以及它们之间的关系,而忽略了其他包含相关信息的限定跨度(如位置、时间等)。
- 以往的 UIE 模型没有明确利用提取模式来限制结果。工作关系提供了一种情况,即主体和客体分别是个人和组织实体。忽略明确的模式可能会导致虚假的结果,妨碍模型在资源有限的情况下的泛化和性能。
本文提出的UIE模型:
在本文中,我们通过一个全面的形式框架重新定义了通用信息提取(UIE),该框架几乎涵盖了所有提取模式。据我们所知,我们是第一个为任何一种模式引入 UIE 的人。此外,我们还介绍了RexUIE,它是一种针对UIE的带有显式模式指导器的递归方法。RexUIE对所有模式类型进行递归查询,并利用三种统一的标记链接操作来计算每次查询的结果。我们根据先前提取的跨度和分层模式构建一个显式模式指导器(ESI),从而为 RexUIE 提供丰富的标签语义信息,并确保提取结果符合模式约束。ESI 与文本连接形成查询。
以图为例,解释RexUIE的工作原理:
以图 1(b)为例,在给定提取模式的情况下,RexUIE 首先提取出 “Leonard Parker”,将其归类为 “Person”,然后根据模式提取出 “Harvard University”,将其归类为 “University”,再加上 "Educated At "关系。第三,根据检索到的图元(“Leonard Parker”,“Person” )和(“Harvard University”,“Educated At (University)” ),RexUIE 导出了分类为 "学术学位 "的跨度 “PhD”。RexUIE 根据模式以递归方式提取跨度,允许提取两个以上的跨度,如四重和五重跨度,而不是仅限于成对的跨度及其关系。
我们在有监督的 NER 和 RE 数据集、机器阅读理解(MRC)数据集以及通过远程监督构建的 300 万个联合实体和关系提取(JERE)实例上对 RexUIE 进行了预训练。大量实验证明,RexUIE 在各种任务中的表现都超过了最新技术水平,在少量实验中的表现也优于之前的 UIE 模型。此外,RexUIE 在提取四元组和五元组方面表现出了显著的优势。
本文的贡献可概括如下:
-
我们通过一个全面的形式框架重新定义了真正的通用信息提取(UIE),该框架涵盖了几乎所有的提取模式,而不仅仅是主体和客体。
-
我们引入了 RexUIE,它可以递归运行所有模式类型的查询,并利用三种统一的标记链接操作来计算每个查询的结果。它采用显式模式指示来增强标签语义信息,并提高低资源场景下的性能。
-
我们对 RexUIE 进行预训练,以提高少量搜索的性能。广泛的实验证明了 RexUIE 的显著效果,它不仅在大多数传统 IE 任务中超越了之前的 UIE 模型,而且在复杂模式(如四元和五元)的提取方面也表现出了卓越的能力。
2 Related Work
针对特定任务的 IE 模型已得到广泛研究,包括命名实体识别;关系提取;事件提取;以及基于方面的情感分析。
最近的一些研究尝试联合提取实体、关系和事件。OneIELin 等人首先从输入句子中以图的形式提取出全局最优的 IE 结果,并结合全局特征来捕捉跨子任务和跨实例的交互。FourIENguyen 等人引入了四个任务实例之间的交互图。另一种用于联合信息提取并取得巨大成功的方法是文本到文本语言生成模型。Lu 等人以文本到文本的方式生成了触发词和论点的线性化序列。Kan 等人旨在通过在文本前添加一些一般或特定任务的提示来联合提取信息。
Lu 等人介绍了 UIE 的统一结构生成。他们提出了一个基于 T5 架构的框架,用于生成包含指定类型和跨度的 SEL。然而,自动回归方法存在 GPU 利用率低的问题。Lou 等人通过设计三种统一的标记链接操作,提出了一种用于 UIE 的端到端框架,称为 USM。对4个 IE 任务的实证评估表明,USM 在零/少量传输设置中具有很强的泛化能力。但 USM 无法提取复杂的模式,如四元和五元。此外,它没有明确使用模式来约束结果。
3 Redefine Universal Information Extraction
Lu等人和Lou等人提出了通用信息提取(Universal Information Extraction)方法,用一个统一的模型来处理NER、RE、EE和ABSA,但他们的方法仅限于少数任务,忽略了包含两个以上跨度的模式,如四重和五重。因此,我们对 UIE 进行了重新定义,以涵盖更多通用模式的提取。
对UIE的重新定义:
我们认为,真正的 UIE 从文本中提取结构化信息的集合,每个项目由 n n n 跨度 s = [ s 1 , s 2 , . . . , s n ] s=[s_1,s_2,...,s_n] s=[s1,s2,...,sn]和 n n n 相应的类型 t = [ t 1 , t 2 , . . . , t n ] t=[t_1,t_2,...,t_n] t=[t1,t2,...,tn]组成。跨度是从文本中提取的,而类型则由给定的模式定义。每一对 ( s i , t i ) (s_i,t_i) (si,ti)都是要提取的目标。
4 RexUIE
在本节中,我们将介绍 RexUIE:一种用于通用信息提取的带有显式模式指示器的递归方法。
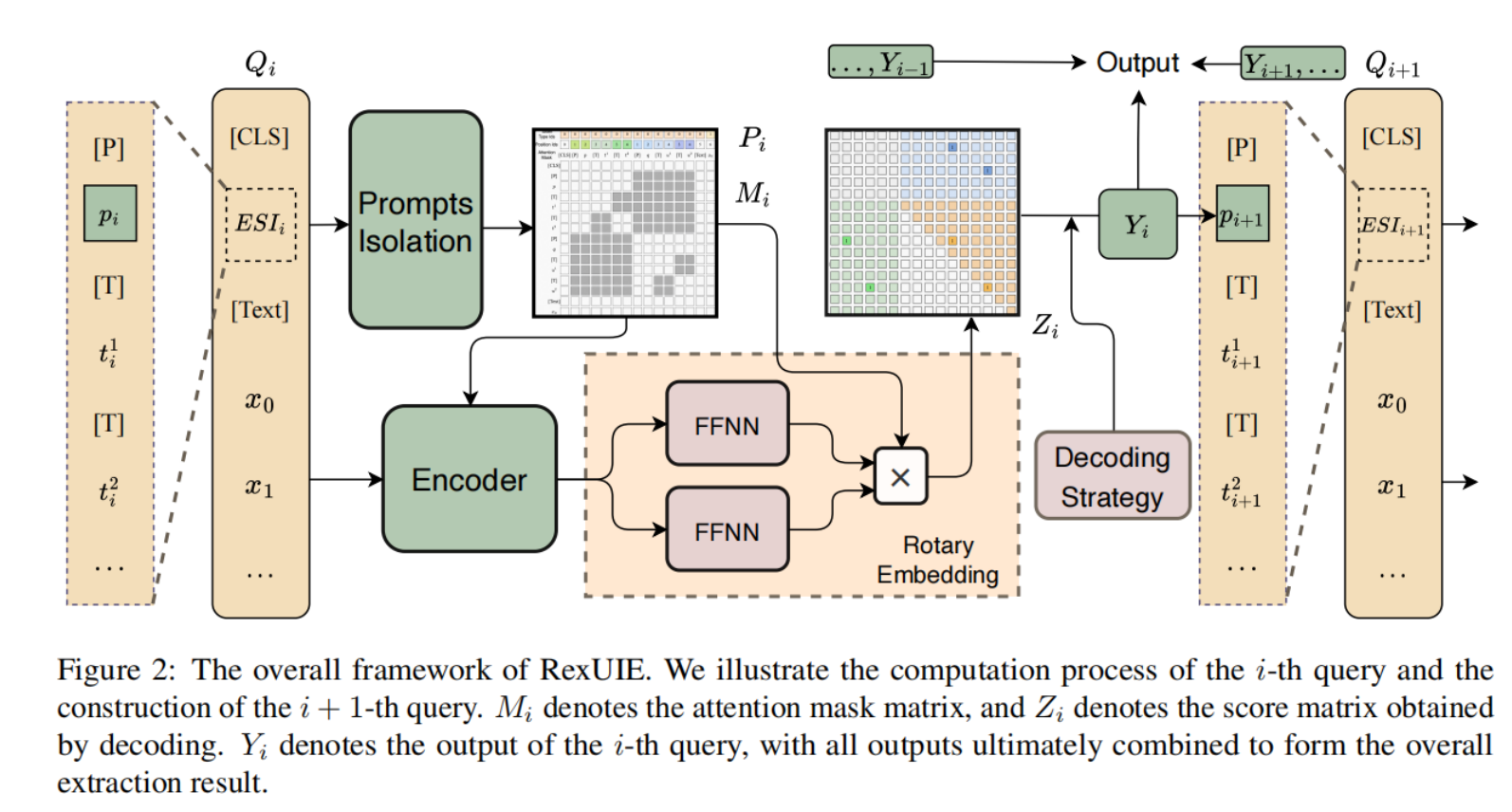
RexUIE 将学习目标方程 1 建模为一系列递归查询,采用三种统一的标记连接操作来计算每次查询的结果。等式 1 中的 ( s , t ) < i (\mathbf{s},\mathbf{t})_{<i} (s,t)<i 条件由 i i i 查询中的前缀表示, ( s , t ) i (s,t)_{i} (s,t)i 则由链接操作计算得出。
4.1.Framework of RexUIE
框架具体流程:
1.送入encoder中获取embedding:
图 2 显示了整体框架。RexUIE 对所有模式类型进行递归查询。给定第i个查询
Q
i
Q_{i}
Qi,我们采用预训练好的语言模型作为编码器,将标记映射到隐藏表示
h
i
∈
R
n
×
d
h_{i}\in\mathbb{R}^{n\times d}
hi∈Rn×d,其中
n
n
n 是查询的长度,
d
d
d 是隐藏状态的维度、
h
i
=
E
n
c
o
d
e
r
(
Q
i
,
P
i
,
M
i
)
(2)
hi=\mathbf{Encoder}(Q_{i},P_{i},M_{i}) \tag{2}
hi=Encoder(Qi,Pi,Mi)(2)
其中
P
i
P_{i}
Pi 和
M
i
M_{i}
Mi 分别表示
Q
i
Q_{i}
Qi 的位置标识和注意力掩码矩阵。
2.将embedding送入两个全连接层:
然后,将隐藏状态输入两个前馈神经网络 F F N N q , F F N N k \mathbf{FFNN}_{q},\mathbf{FFNN}_{k} FFNNq,FFNNk 。
3.计算隐藏向量的rope旋转矩阵:
接下来,我们应用旋转嵌入计算得分矩阵
Z
i
Z_{i}
Zi。
Z
i
j
,
k
=
(
F
F
N
N
q
(
h
i
j
)
⊤
R
(
P
i
k
−
P
i
j
)
F
F
N
N
k
(
h
i
k
)
)
⊗
M
i
j
,
k
(3)
\begin{split}Z_{i}^{j,k}=(\mathbf{FFNN}_{q}(h_{i}^{j})^{\top}\mathbf{R}(P_{i}^{k}-P_{i}^{j}) \mathbf{FFNN}_{k}(h_{i}^{k}))\otimes M_{i}^{j,k}\end{split}\tag{3}
Zij,k=(FFNNq(hij)⊤R(Pik−Pij)FFNNk(hik))⊗Mij,k(3)
其中,
M
i
j
,
k
M_{i}^{j,k}
Mij,k 和
Z
i
j
,
k
Z_{i}^{j,k}
Zij,k 分别表示令牌
j
j
j 到
k
k
k 之间的mask值和得分。
P
i
j
P_{i}^{j}
Pij 和
P
i
k
P_{i}^{k}
Pik 表示标记
j
j
j 和
k
k
k 的位置 id。
⊗
\otimes
⊗ 是 Hadamard 积。
R
(
P
i
k
−
P
i
j
)
∈
R
d
×
d
\mathbf{R}(P_{i}^{k}-P_{i}^{j})\in\mathbb{R}^{d\times d}
R(Pik−Pij)∈Rd×d 表示旋转位置嵌入(RoPE),这是一种相对位置编码方法,具有良好的理论特性。
4.解码旋转矩阵,即通过指针找到对应span的开头、结尾和类型:
最后,我们解码得分矩阵 Z i Z_{i} Zi 以获得输出 Y i Y_{i} Yi,并利用它创建后续查询 Q i + 1 Q_{i+1} Qi+1。所有最终输出都会合并为结果集 Y = { Y 1 , Y 2 , … } \mathcal{Y}=\{Y_{1},Y_{2},\dots\} Y={Y1,Y2,…} 。
我们使用Circle损失作为 RexUIE 的损失函数,它在计算稀疏矩阵的损失方面非常有效
L
i
=
log
(
1
+
∑
Z
^
i
j
=
0
e
Z
‾
i
j
)
+
log
(
1
+
∑
Z
^
i
k
=
1
e
−
Z
‾
i
k
)
L
=
∑
i
L
i
(4)
\begin{split}\mathcal{L}_{i}=\log(1+\sum_{\hat{Z}_{i}^{j}=0}e^{ \overline{Z}_{i}^{j}})+\log(1+\sum_{\hat{Z}_{i}^{k}=1}e^{-\overline{Z}_{i}^{k }})\\ \mathcal{L}=\sum_{i}\mathcal{L}_{i}\end{split}\tag{4}
Li=log(1+Z^ij=0∑eZij)+log(1+Z^ik=1∑e−Zik)L=i∑Li(4)
其中,
Z
‾
i
\overline{Z}_{i}
Zi 是
Z
i
Z_{i}
Zi 的扁平化版本,
Z
^
i
\hat{Z}_{i}
Z^i 表示扁平化的ground truth,只包含 1 和 0。
4.2. Explicit Schema Instructor
输入的显示模式指令构造:
第 i i i 次查询 Q i Q_{i} Qi 由一个显式模式指示器(ESI)和文本 x x x 组成。ESI是前缀 p i p_{i} pi和类型 t i = [ t i 1 , t i 2 , … ] t_{i}=[t_{i}^{1},t_{i}^{2},\dots] ti=[ti1,ti2,…]的连接。前缀 p i p_{i} pi 模拟了等式 1 中的 ( s , t ) < i (\mathbf{s},\mathbf{t})_{<i} (s,t)<i, t i t_{i} ti 指定了在给定 p i p_{i} pi 的情况下,可以从 x x x 中识别出哪些类型。
我们在每个前缀前插入一个特殊标记 [P],在每个类型前插入一个 [T]。此外,我们还在文本 x x x 前插入一个标记 [Text]。那么,输入的 Q i Q_{i} Qi 可以表示为
Q
i
=
[CLS][P]
p
i
[T]
t
i
1
[T]
t
i
2
…
[Text]
x
0
x
1
…
(5)
Q_{i}=\texttt{[CLS][P]}p_{i}\texttt{[T]}t_{i}^{1}\texttt{[T]}t_{i}^{2}\ldots \texttt{[Text]}x_{0}x_{1}\ldots \tag{5}
Qi=[CLS][P]pi[T]ti1[T]ti2…[Text]x0x1…(5)
对于先前提取的跨度和相应的类型,我们使用": “来连接跨度和类型,使用”, "来连接先前每次查询的结果,从而根据模式构建前缀。因此,通过递归查询到模式中的最后一个类型,RexUIE 可以提取包括四元组和五元组在内的各种模式。我们用模式第一层的类型构建
Q
0
Q_{0}
Q0,作为对模型的初始查询。特别说明的是,前缀
p
0
p_{0}
p0 是空序列。
4.3.Token Linking Operations
三个token链接指针:
给定计算出的分数矩阵
Z
Z
Z,我们通过一个预定义的阈值
δ
\delta
δ 从
Z
Z
Z 中得到
Z
~
\tilde{Z}
Z~ ,如下所示
Z
~
i
,
j
=
{
1
if
Z
i
,
j
≥
δ
0
otherwise
(6)
\tilde{Z}^{i,j}=\begin{cases}1&\text{if }Z^{i,j}\geq\delta\\ 0&\text{otherwise}\end{cases}\tag{6}
Z~i,j={10if Zi,j≥δotherwise(6)
令牌链接在
Z
~
\tilde{Z}
Z~ 上进行,
Z
~
\tilde{Z}
Z~ 的二进制值为 1 或 0。 只有当
Z
~
i
,
j
=
1
\tilde{Z}^{i,j}=1
Z~i,j=1 时,从
i
i
i 的第 1 个令牌到
j
j
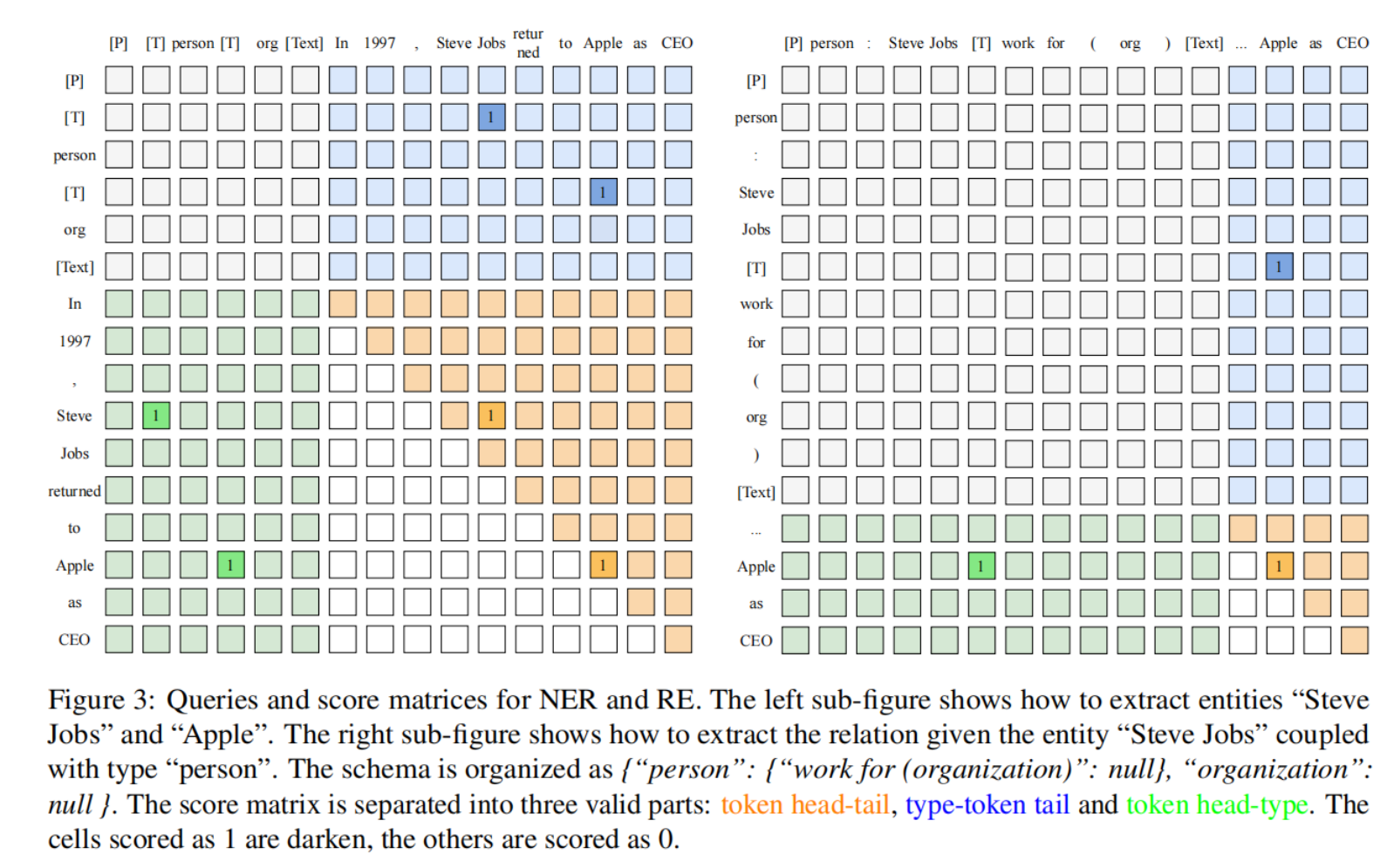
j 的第 1 个令牌之间才能建立令牌链接;否则,不存在链接。为了说明这一过程,请看图 3 中的例子。我们将阐述如何根据得分矩阵提取实体和关系。
Token Head-Tail Linking:
Token Head-Tail Linking :token头部-类型链接是指在跨度的头部与其类型之间建立的链接。
Token Head-Type Linking:
Token Head-Type Linking:token头部-类型链接是指跨度头部与其类型之间建立的链接。为了表示类型,我们使用特殊标记 [T],它位于类型标记之前。
Type-Token Tail Linking:
Type-Token Tail Linking:类型-token尾部链接指的是跨度类型与其尾部之间建立的联系。与标记头-类型链接类似,我们利用类型标记前的[T]标记来表示类型。
在推理过程中,对于一对标记 l a n g l e i , j ⟩ langle i,j\rangle langlei,j⟩ 来说,如果 Z i , j ≥ δ Z^{i,j}\geq\delta Zi,j≥δ,并且存在满足 Z i , k ≥ δ Z^{i,k}\geq\delta Zi,k≥δ 和 Z k , j ≥ δ Z^{k,j}\geq\delta Zk,j≥δ 的 [T] k k k,我们就提取出类型在 k k k 之后的跨度 Q i , j Q^{i,j} Qi,j。
4.4.Prompts Isolation
RexUIE 可以接收带有多个前缀的查询。为了节省时间成本,我们将不同的前缀组放在同一个查询中。例如,考虑文本 “肯尼迪于 1963 年 11 月 22 日被李-哈维-奥斯瓦尔德枪杀”,其中包含两个 "person "实体。我们将这两个实体跨度及其在模式中的相应类型分别连接起来,得到 ESI:[CLS][P]person: Kennedy [T] kill (person) [T] live in (location). . .[P] person: Lee Harvey Oswald [T] kill(person) [T] live in (location). . .
但是,"kill (person)"类型的隐藏表征不应受到 "live in (location)"类型的干扰。同样,前缀为 person:Kennedy 的隐藏表征也不应受到其他前缀(如 person: Lee Harvey Oswald)的干扰。
受 Yang 等人的启发,我们提出了 “提示隔离”(Prompts Isolation)方法,这种方法可以减少不同类型和前缀的标记之间的干扰。通过修改标记符类型ids、位置ids和注意力掩码,这些标记符之间的直接信息流被有效阻断,从而能够清晰地区分 ESI 中的不同部分。我们在图 4 中对提示隔离进行了说明。对于注意力屏蔽,每个前缀标记只能与前缀本身、其子类型标记和文本标记交互。每个类型标记只能与类型本身、相应的前缀标记和文本标记交互。
然后就可以更新等式 3 中的位置 id P P P 和注意力mask M M M。这样,就可以阻止潜在的混乱信息流。此外,模型也不会受到前缀和类型顺序的干扰。

4.5.Pre-training
为了提高 RexUIE 的零镜头和少镜头性能,我们在以下三个不同的数据集上对 RexUIE 进行了预训练:
Distant Supervision 数据 D d i s t a n t \mathcal{D}_{distant} Ddistant :我们从 WikiPedia1 收集了语料和标签,并利用 Distant Supervision 将文本与各自的标签对齐。
有监督的 NER 和 RE 数据 D s u p e r v \mathcal{D}_{superv} Dsuperv :与 D d i s t a n t \mathcal{D}_{distant} Ddistant 相比,有监督的数据由于不存在抽象或过度专业化的类,因此质量更高,也不会出现因知识库不完整而导致的高假阴性率。
MRC 数据 D m r c \mathcal{D}_{mrc} Dmrc: Lou 等人之前的工作经验表明,在预训练中加入机器阅读理解(MRC)数据可以增强模型在提示中利用语义信息的能力。因此,我们在预训练数据中加入了 MRC 监督实例。
5 Experiments
在本节中,我们将在有监督的设置和少量拍摄的设置下进行广泛的实验。在实施过程中,我们采用 DeBERTaV3-Large He 等人的文本编码器,该编码器通过分散注意力的方式纳入了相对位置信息。我们将最大标记长度设为 512,ESI 的最大长度设为 256。当 ESI 长度超出限制时,我们会将查询拆分成若干个子查询。
5.1.Dataset
我们主要遵循卢等的数据设置。我们还添加了两个任务来评估提取具有两个以上跨度的模式的能力: 1)四重体提取。我们使用HyperRED,这是一个用于超关系提取的数据集,可以从文本中提取更具体和更完整的事实。HyperRED的每个四倍都由一个标准关系三倍和一个附加的限定符字段组成,该字段涵盖了各种属性,如时间、数量和位置。2)比较意见五倍提取。COQE的目的是从复习句子中提取所有的比较五元组。每个实例最多有5个属性可以提取:主题、对象、方面、观点和意见的极性(例如,好、差或相等)。我们只使用英语子集照相机-co
5.2.Main Results
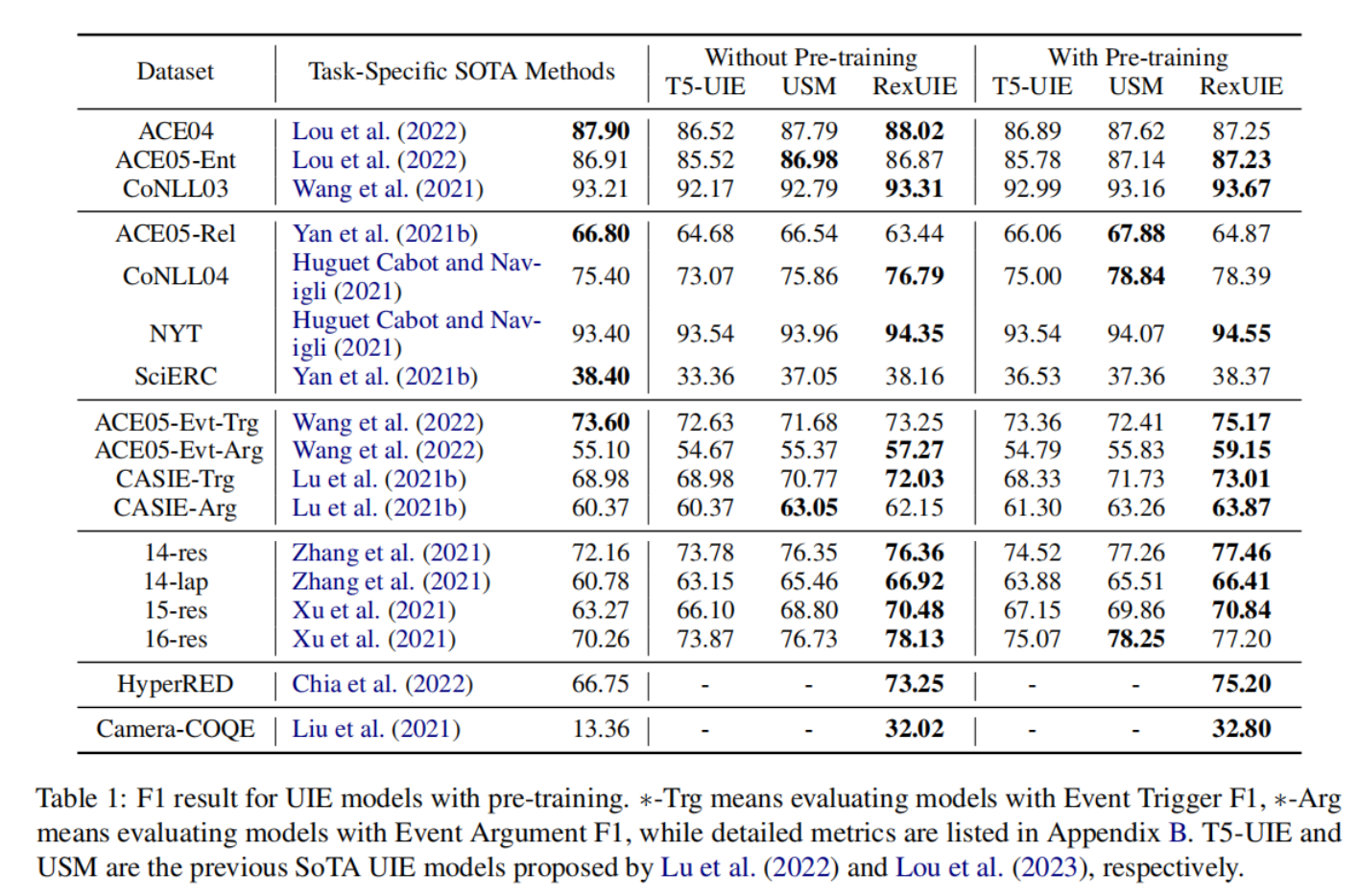
表 1 列出了 RexUIE 与 T5-UIE Lu 等人(2022 年)、USM Lou 等人(2023 年)以及之前的特定任务模型在预训练和非预训练场景下的综合比较。
我们可以观察到
- RexUIE 在半数以上的 IE 任务中,即使不进行预训练,也能超越针对特定任务的最新模型。在所有 ABSA 数据集上,RexUIE 的 F1 分数都高于 USM 和 T5-UIE。此外,RexUIE 在事件提取任务中的表现明显优于基线模型。
- 预训练使性能略有提高。通过比较后三列的结果,我们可以发现经过预训练的 RexUIE 在大多数数据集上都领先于 T5-UIE 和 USM。经过预训练后,ACE05-Evt 有了显著改善,f1 分数提高了约 2%。这意味着 RexUIE 有效地利用了提示文本中的语义信息,并在文本跨度及其相应类型之间建立了联系。值得注意的是,ACE05-Evt 中的触发词和参数模式比较复杂,模型在很大程度上依赖于标签的语义信息。
- 下面两行描述了提取四元和五元的结果,并与 SoTA 方法进行了比较。我们的模型在 HyperRED 和 Camera-COQE 上都表现出了明显的优势,这说明了提取复杂模式的有效性。
5.3.Few-Shot Information Extraction
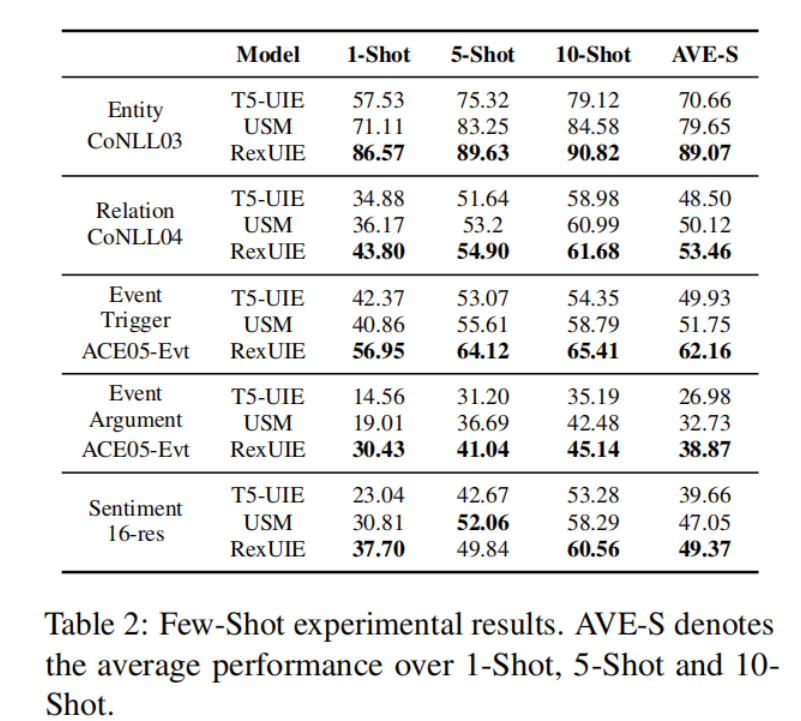
按照 Lu 等人(2022 年)和 Lou 等人(2023 年)的方法,我们对每个任务的一个数据集进行了少量实验。实验结果如表 2 所示。
总体而言,在低资源环境下,RexUIE 的性能优于 T5-UIE 和 USM。具体来说,RexUIE 在单发场景中平均比 T5-UIE 高出 56.62%,比 USM 高出 32.93%。RexUIE 在低资源环境下的成功可归因于其提取预训练过程中学习到的信息的能力,以及我们提出的查询的功效,该查询有助于明确模式
5.4.Zero-Shot Information Extraction
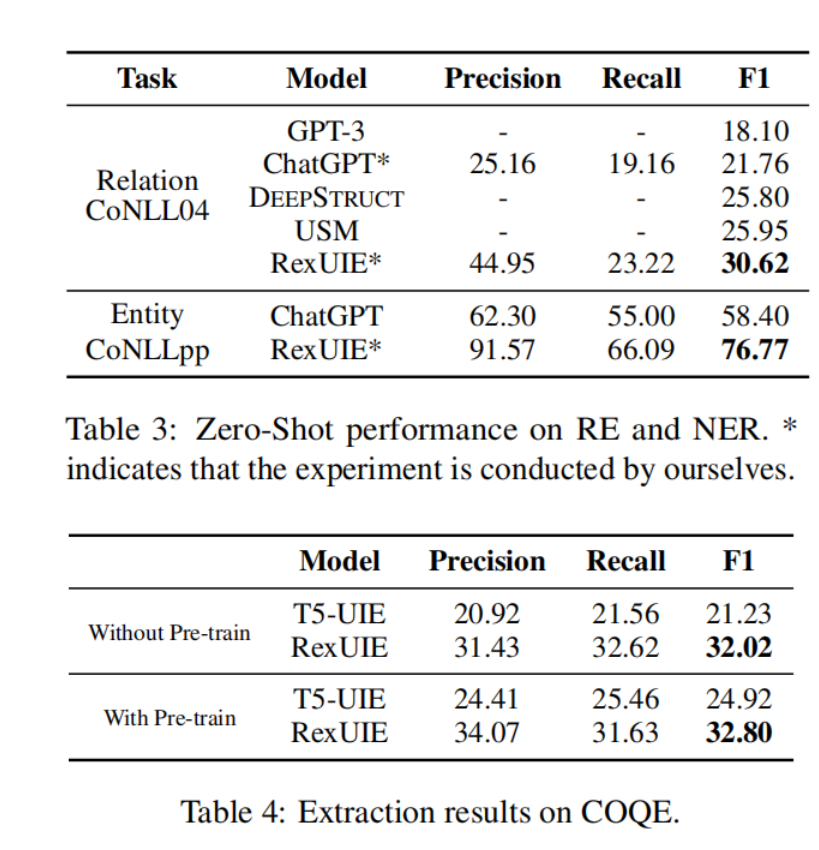
我们进行了 RE 和 NER 的零点实验,将 RexUIE 与包括 ChatGPT2 在内的其他预训练模型进行了比较。我们使用 CoNLL04 和 CoNLLppWang 等人(2019 年)分别进行 RE 和 NER 实验。我们在表 3 中报告了精确度、召回率和 F1。
在这两个数据集上,RexUIE 的零镜头提取性能最高。此外,我们还分析了 ChatGPT 的不良情况。1) ChatGPT 生成的单词在原文中并不存在。例如,ChatGPT 输出了一个跨词 “Coats Michael”,而原文是 “Michael Coats”。2) 粒度不当造成的错误,如 "意大利城市 "和 “意大利”。3) 针对模式的非法提取。ChatGPT 输出(Anastas Mikoyan,work for,Soviet)。虽然 Anastas Mikoyan 是苏联政治家,但关系 work for 要求对象是一个组织,而 Soviet 不是。
5.5.Complex Schema Extraction
为了说明提取复杂模式能力的重要性,我们为 T5-UIE 设计了一种强制提取五元组的方法,即提取三个元组组成一个五元组。详情见附录 C。
表 4 显示了 RexUIE 与 T5-UIE 的比较结果。总的来说,RexUIE 直接提取五元组的方法表现出更优越的性能。虽然 T5-UIE 在预训练后性能略有提高,但在 F1 上仍比 RexUIE 低约 8%。
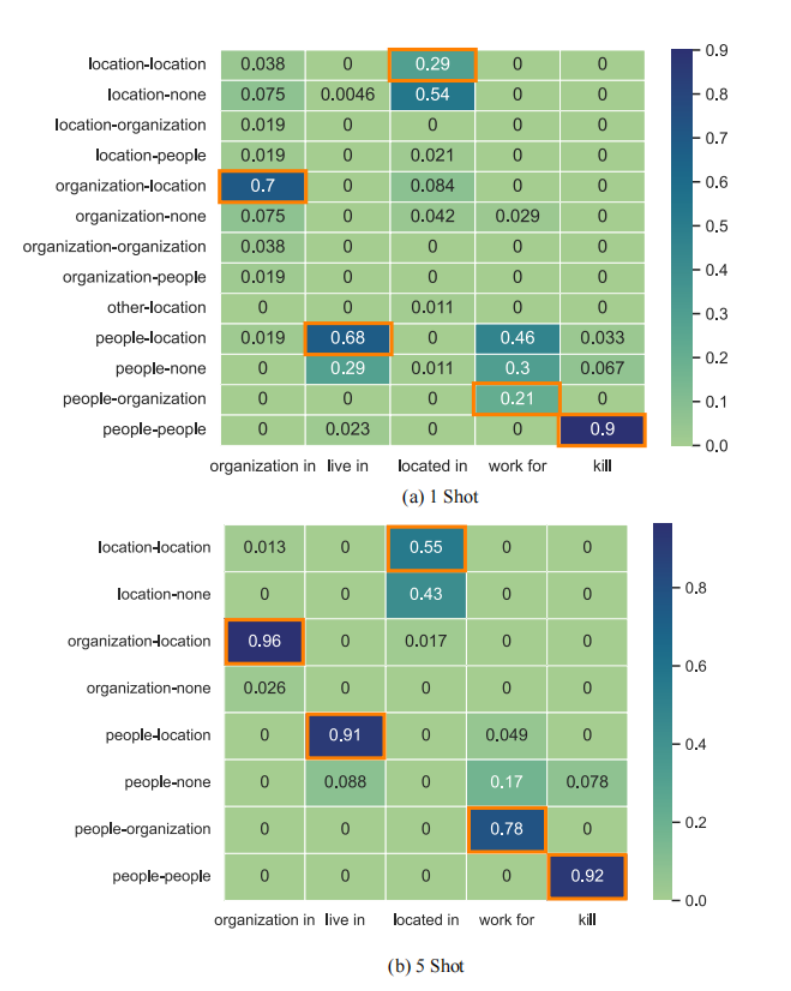
我们分析了 T5-UIE 预测的关系类型与_主体类型-客体类型_的分布情况,如图 5 所示。
我们观察到,非法提取(如_person, work for, location_)在 1-Shot 中并不罕见,相当数量的主体或客体在 NER 阶段没有被正确提取。虽然这一问题在 5 镜头场景中得到了缓解,但我们认为不精确的模式指示器仍然会对模型的性能产生负面影响。
















 4621
4621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









