







概述
Deep Factors是一种global-local组合的框架预测模型,这个家族包含三种方法:DF-RNN,DF-LDS和DF-GP。这三种方法global的部分是相同的,由一组深度因子的线性组合而成,这些深度因子都是采用DNN神经网络获得的,论文中采用的是RNN,用于提取复杂的非线性模式(fixed effect);local部分使用概率模型,比如白噪声过程、LDS或GP,用于捕捉单个序列的随机效应(random effect)。
前面讲了DeepAR和MQR ( ( (C ) ) )NN,根据论文里给出的实验结果,Deep Factors的总体性能(预测效果、计算效率)比前两者好(我在自己数据集上跑的效果似乎并没有这样)。总计起来,主要是以下几点:
(1)设置多个深度因子,有效的降低了预测方差
下图是论文中给出的Deep Factors(仅global部分)和RNN的训练、预测对比,可以看出来在同样大小的训练集上Deep Factors训练的更快,而且在测试集上预测效果也更好。
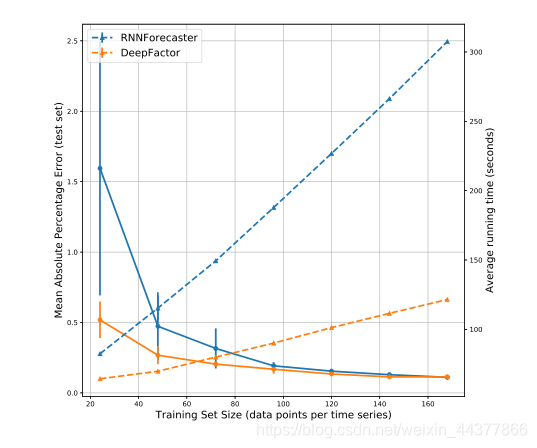
(2)相比标准的RNN预测器、DeepAR和MQR,Deep Factors需要学习的参数少一些,所以计算效率较高一些,主要涉及到嵌入矩阵w是否放入神经网络中学习。
(3)DeepAR和MQR ( ( (C)NN的seq2seq结构限制了对变化的预测场景(例如按需预测期间)或交互场景的灵活反应能力,例如解码器长度发生变化,需要及时对DeepAR和MQR ( ( (C)NN进行再训练,以反映其变化。Deep Factors 在这些方面具有更高的效率。
原理
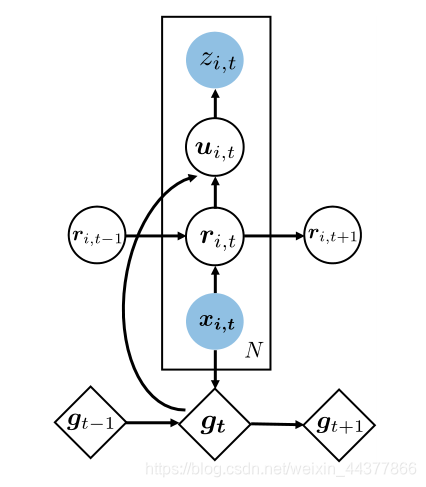
Deep Factors的网络结构
对于一组时间序列,
x
i
,
t
x_{i,t}
xi,t 表示第i条序列在t时刻的特征,
z
i
,
t
z_{i,t}
zi,t表示第
i
i
i条序列在
t
t
t时刻的观察值,给定一个预测范围
τ
τ
τ,deep factors的目标就是计算未来观测的联合预测分布,用公式表达为:
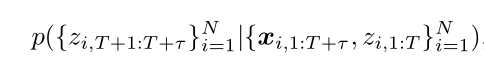
具体实现过程
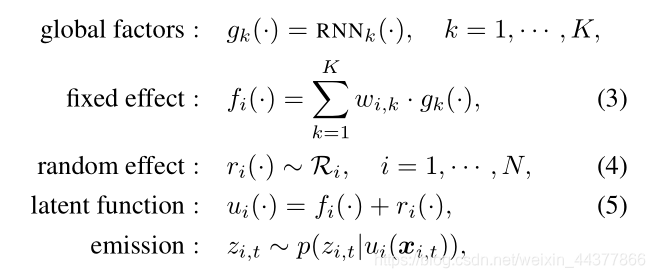
Fixed Effect
由K个深度因子线性组合而得,这K个深度因子由RNN获得,K是个超参,得到的Fixed effect相当于每个时间点的预测均值。
通过在电力数据上比较由RNN得到的fixed effect(L2)和标准的RNN预测器(L2),发现fixed effect 有更高的计算效率,并且有更小的方差(多因子的优点)。
Random Effect
包含三种类型,得到的Random Effect就相当于每个时间点的预测方差(标准差):

DF-RNN
r i , t ~ N ( 0 , σ i , t 2 ) r_{i,t} ~ N(0,σ^2_{i,t}) ri,t~N(0,σi,t2),其中 σ i , t 2 σ^2_{i,t} σi,t2由noise RNN 计算,RNN的输入是 x i , t x_{i,t} xi,t,即是序列的特征。
DF-LDS
r
i
,
t
r_{i,t}
ri,t由如下的生成模型给出:
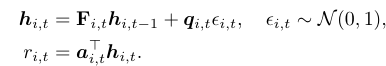
即由一个转移矩阵
F
i
,
t
F_{i,t}
Fi,t和random innovation
q
i
,
t
q_{i,t}
qi,t演化而来,这两个矩阵的结构由时间序列的隐藏状态
h
i
,
t
h_{i,t}
hi,t编码决定,这个
h
i
,
t
h_{i,t}
hi,t又取决于SSM(状态空间模型)的选择。
DF-GP(高斯过程)
r i , t ~ G P ( 0 , K i ( . , . ) ) r_{i,t} ~ GP(0,K_{i}(_{.,.})) ri,t~GP(0,Ki(.,.)),其中 K i ( . , . ) K_{i}(_{.,.}) Ki(.,.)表示kernel function。该模型每条序列都有各自的GP参数,训练时需要学习。论文中给出了一个核函数为Dirac delta function,核函数的输入是 x i , t x_{i,t} xi,t。
loss
针对符合高斯似然的案列:计算上表中的似然 p ( z i ) p(z_{i}) p(zi),通过梯度下降进行参数优化。
对于DF-GP,通过 p ( z i ) = N ( f i , K i + σ i 2 I ) p(z_{i})=N(f_{i},K_{i}+σ^2_{i}I) p(zi)=N(fi,Ki+σi2I)计算似然,其中 f i f_{i} fi是代表fixed effect部分,由RNN计算; K i + σ i 2 I K_{i}+σ^2_{i}I Ki+σi2I代表random effect部分,由高斯过程计算。
对于DF-RNN,类似于DF-GP,通过 p ( z i ) = N ( f i , σ i , t 2 ) p(z_{i})=N(f_{i},σ^2_{i,t}) p(zi)=N(fi,σi,t2)计算似然,fixed effect部分与DF-GP一样;不一样的是random effect, σ i , t 2 σ^2_{i,t} σi,t2也是由RNN计算而得。
对于DF-LDS,通过Kalman Filter计算。
代码实现
下面是DF-RNN核心部分的代码实现
global-local
def lstm_cell(layer_num,hidden_size,keep_prob):
'''
构建lstm单元 及 单元堆栈
'''
stacked_rnn = []
for i in range(layer_num):
lstm = tf.contrib.rnn.LSTMCell(hidden_size, forget_bias=1.0)
drop = tf.nn.rnn_cell.DropoutWrapper(lstm, output_keep_prob=keep_prob)
stacked_rnn.append(drop)
lstm_multi = tf.contrib.rnn.MultiRNNCell(stacked_rnn)
return lstm_multi
def rnn(input,cells,time_step,keep_prob):
'''
构建递归神经网络
:param input: [batch_size,time_step,input_dim]
:param cells: lstm_cell的return
:param time_step:[batch_size]
:param keep_prob:
:return:
output [batch_size, time_step, hidden_size] encoder的最后状态
'''
output, _ = tf.nn.dynamic_rnn(cell=cells, inputs=input, sequence_length=time_step, dtype=tf.float32)
return output
def fully_connection(inputs, num_outputs, keep_prob):
'''
使用全连接,输出结果对应一个预测值
:param inputs: rnn输出的状态 output[:,-1,:] [batch_size, hidden_size]
:param n_hidden: 1
:param keep_prob:
:return:
outputs [batch_size, time_step, 1] 预测值
'''
outputs = tf.contrib.layers.fully_connected(inputs, num_outputs, activation_fn=tf.nn.relu,biases_initializer=tf.zeros_initializer())
return outputs
def global_model(self, input, time_step, keep_prob, num_factors):
with tf.variable_scope('global', reuse=tf.AUTO_REUSE):
output = rnn(input, time_step, keep_prob) # [batch_size, time_step, hidden_size]
global_factors = fully_connection(output, num_factors, keep_prob) # [batch_size, time_step, num_factors]
return global_factors
def local_model(input, time_step, keep_prob):
with tf.variable_scope('local', reuse=tf.AUTO_REUSE):
output = rnn(input, time_step, keep_prob) # [batch_size, time_step, hidden_size]
random_effect = fully_connection(output, 1, keep_prob) # [batch_size, time_step, 1]
return random_effect
def compute_fixed_random_effect(embedded_cat_id,local_input,time_feat,time_step,num_factors,keep_prob):
embedder = fully_connection(embedded_cat_id, num_factors, keep_prob) # (batch_size, num_factors),改变维度,为了和global_factors矩阵相乘
global_factors = global_model(time_feat, time_step, keep_prob,
num_factors) # [batch_size, time_step, num_factors]
fixed_effect = tf.matmul(global_factors, tf.expand_dims(embedder, axis=2)) # # [batch_size, time_step, 1]
random_effect = tf.log(tf.exp(local_model(local_input, time_step, keep_prob)) + 1.0)
return tf.exp(fixed_effect), random_effect
loss
def negative_normal_likelihood(y, mu, sigma):
return tf.math.reduce_mean(tf.log(sigma) + 0.5 * math.log(2 * math.pi) + 0.5 * tf.square((y - mu) / sigma)) + 1e-6
def create_loss(y, mu, sigma):
with tf.name_scope("loss"):
loss_op = negative_normal_likelihood(y, mu, sigma) #可以选择加入正则
# tvars = tf.trainable_variables()
# l2_loss = tf.add_n([tf.nn.l2_loss(v) for v in tvars if v.get_shape().ndims > 1])
# loss_op = loss + self.l2_reg_lamda * l2_loss
return loss_op
def create_optimizer(learning_rate,loss_op, global_step):
threshold = 5
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
grads_and_vars = optimizer.compute_gradients(loss_op)
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var) for grad, var in grads_and_vars] # 防止梯度爆炸
train_op = optimizer.apply_gradients(capped_gvs, global_step=global_step)
return train_op


















 1605
1605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











