







文章目录
5 向量微积分(Vector Calculus)(下)
5.4 矩阵的梯度
我们会遇到这样的情况:我们需要求矩阵关于向量(或其他矩阵)的梯度,最后得到多维的张量( tensor,我们可以把张量看作一个多维数组。)。我们可以把这一张量看作是一个元素为偏导数的多维数组。例如,如果我们计算 m × n m×n m×n矩阵 A \boldsymbol{A} A相对于 p × q p×q p×q矩阵 B \boldsymbol{B} B的梯度,得到的雅可比矩阵的形状将是 ( m × n ) × ( p × q ) (m×n)×(p×q) (m×n)×(p×q),即一个四维张量 J \boldsymbol{J} J,其各个元素表示为 J i j k l = ∂ A i j / ∂ B k l J_{i j k l}=\partial A_{i j} / \partial B_{k l} Jijkl=∂Aij/∂Bkl。
由于矩阵表示线性映射,我们可以利用 m × n m×n m×n矩阵的空间 R m × n \mathbb{R}^{m \times n} Rm×n和 m n mn mn向量的空间 R m n \mathbb{R}^{m n} Rmn之间存在向量空间同构(线性可逆映射)的事实,将两个矩阵重塑(re-shape)成长度分别为 m n mn mn和 p q pq pq的向量。然后使用这些向量计算梯度,得到大小为 m n × p q mn×pq mn×pq的雅可比矩阵。
考虑计算矩阵 A ∈ R 4 × 2 \boldsymbol{A} \in \mathbb{R}^{4 \times 2} A∈R4×2相对于向量 x ∈ R 3 \boldsymbol{x} \in \mathbb{R}^{3} x∈R3的梯度计算。我们知道梯度的维度为 d A d x ∈ R 4 × 2 × 3 \frac{\mathrm{d} \boldsymbol{A}}{\mathrm{d} \boldsymbol{x}} \in \mathbb{R}^{4 \times 2 \times 3} dxdA∈R4×2×3。下面给出两种求梯度的方法。
方法1
我们计算偏导数
∂
A
∂
x
1
,
∂
A
∂
x
2
,
∂
A
∂
x
3
\frac{\partial \boldsymbol{A}}{\partial x_{1}}, \frac{\partial \boldsymbol{A}}{\partial x_{2}}, \frac{\partial \boldsymbol{A}}{\partial x_{3}}
∂x1∂A,∂x2∂A,∂x3∂A,得到每个偏导数都是
4
×
2
4\times 2
4×2的矩阵,把它们集合成
4
×
2
×
3
4\times 2\times 3
4×2×3的矩阵。
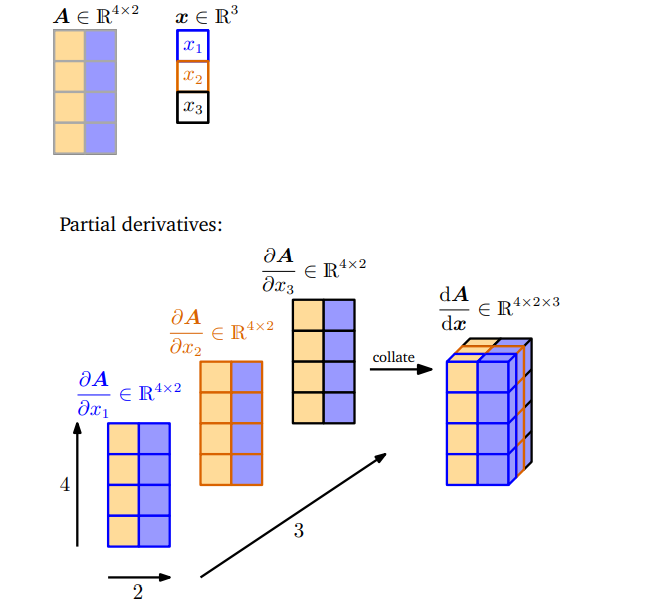
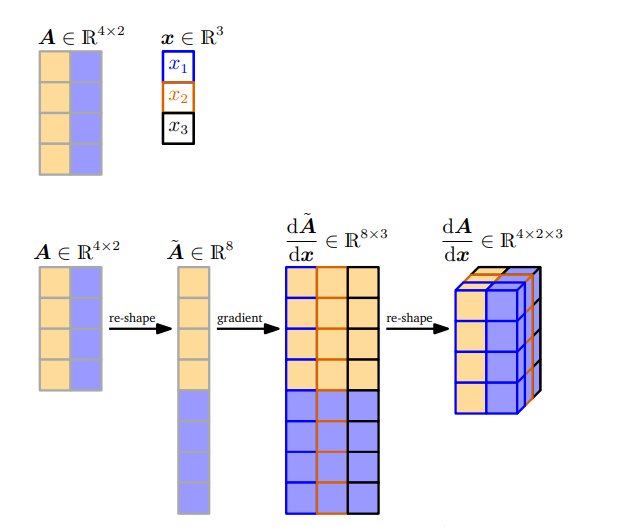
方法2
我们把
A
∈
R
4
×
2
\boldsymbol{A} \in \mathbb{R}^{4 \times 2}
A∈R4×2重塑(re-shape (flatten)) 成一个向量
A
~
∈
R
8
\tilde{\boldsymbol{A}} \in \mathbb{R}^{8}
A~∈R8。然后我们计算
d
A
~
d
x
∈
R
8
×
3
\frac{\mathrm{d} \tilde{A}}{\mathrm{~d} \boldsymbol{x}} \in \mathbb{R}^{8 \times 3}
dxdA~∈R8×3。最后再通过重塑这个梯度得到梯度张量,如图所示。
例 5.12 向量相对于矩阵的梯度
已知:
f
=
A
x
,
f
∈
R
M
,
A
∈
R
M
×
N
,
x
∈
R
N
\begin{array}{ll}\boldsymbol{f}=\boldsymbol{A x}, & \boldsymbol{f} \in \mathbb{R}^{M}, \quad \boldsymbol{A} \in \mathbb{R}^{M \times N}, \quad \boldsymbol{x} \in \mathbb{R}^{N}\end{array}
f=Ax,f∈RM,A∈RM×N,x∈RN
求梯度:
d
f
/
d
A
\mathrm{d} \boldsymbol{f} / \mathrm{d} \boldsymbol{A}
df/dA。
让我们从确定梯度的维数开始
d
f
d
A
∈
R
M
×
(
M
×
N
)
\frac{\mathrm{d} \boldsymbol{f}}{\mathrm{d} \boldsymbol{A}} \in \mathbb{R}^{M \times(M \times N)}
dAdf∈RM×(M×N)
根据定义,梯度是偏导数的集合:
d
f
d
A
=
[
∂
f
1
∂
A
⋮
∂
f
M
∂
A
]
,
∂
f
i
∂
A
∈
R
1
×
(
M
×
N
)
\frac{\mathrm{d} \boldsymbol{f}}{\mathrm{d} \boldsymbol{A}}=\left[\begin{array}{c}\frac{\partial f_{1}}{\partial \boldsymbol{A}} \\\vdots \\\frac{\partial f_{M}}{\partial \boldsymbol{A}}\end{array}\right], \quad \frac{\partial f_{i}}{\partial \boldsymbol{A}} \in \mathbb{R}^{1 \times(M \times N)}
dAdf=⎣⎢⎡∂A∂f1⋮∂A∂fM⎦⎥⎤,∂A∂fi∈R1×(M×N)
显式写出矩阵向量乘法将对我们计算偏导数有帮助:
f
i
=
∑
j
=
1
N
A
i
j
x
j
,
i
=
1
,
…
,
M
f_{i}=\sum_{j=1}^{N} A_{i j} x_{j}, \quad i=1, \ldots, M
fi=j=1∑NAijxj,i=1,…,M
其偏导数如下所示
∂
f
i
∂
A
i
q
=
x
q
\frac{\partial f_{i}}{\partial A_{i q}}=x_{q}
∂Aiq∂fi=xq
这允许我们计算
f
i
f_i
fi对
A
\boldsymbol{A}
A各行的偏导数,如下所示
∂
f
i
∂
A
i
,
:
=
x
⊤
∈
R
1
×
1
×
N
\frac{\partial f_{i}}{\partial A_{i,:}}=\boldsymbol{x}^{\top} \in \mathbb{R}^{1 \times 1 \times N}
∂Ai,:∂fi=x⊤∈R1×1×N
∂
f
i
∂
A
k
≠
i
,
:
=
0
⊤
∈
R
1
×
1
×
N
\frac{\partial f_{i}}{\partial A_{k \neq i,:}}=\mathbf{0}^{\top} \in \mathbb{R}^{1 \times 1 \times N}
∂Ak=i,:∂fi=0⊤∈R1×1×N
在这里我们必须注意维度是否正确。由于 f i f_i fi映射到 R \mathbb{R} R上,且 A \boldsymbol{A} A的每一行的大小为 1 × N 1×N 1×N,因此我们得到一个 1 × 1 × N 1×1×N 1×1×N大小的张量,作为 f i f_i fi对 A \boldsymbol{A} A的每一行的偏导数。
我们将
A
\boldsymbol{A}
A对每一行的偏导数叠加在一起,得到我们想要的梯度:
∂
f
i
∂
A
=
[
0
⊤
⋮
0
⊤
x
⊤
0
⊤
⋮
0
⊤
]
∈
R
1
×
(
M
×
N
)
\frac{\partial f_{i}}{\partial \boldsymbol{A}}=\left[\begin{array}{c}\mathbf{0}^{\top} \\\vdots \\\mathbf{0}^{\top} \\\boldsymbol{x}^{\top} \\\mathbf{0}^{\top} \\\vdots \\\mathbf{0}^{\top}\end{array}\right] \in \mathbb{R}^{1 \times(M \times N)}
∂A∂fi=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡0⊤⋮0⊤x⊤0⊤⋮0⊤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤∈R1×(M×N)
例 5.13 矩阵相对于矩阵的梯度
考虑矩阵
R
∈
R
M
×
N
\boldsymbol{R} \in \mathbb{R}^{M \times N}
R∈RM×N和
f
:
R
M
×
N
→
R
N
×
N
\boldsymbol{f}: \mathbb{R}^{M \times N} \rightarrow \mathbb{R}^{N \times N}
f:RM×N→RN×N,且有:
f
(
R
)
=
R
⊤
R
=
:
K
∈
R
N
×
N
\boldsymbol{f}(\boldsymbol{R})=\boldsymbol{R}^{\top} \boldsymbol{R}=: \boldsymbol{K} \in \mathbb{R}^{N \times N}
f(R)=R⊤R=:K∈RN×N
求梯度
d
K
/
d
R
\mathrm{d} \boldsymbol{K} / \mathrm{d} \boldsymbol{R}
dK/dR
为了解决这个难题,让我们先写下我们已经知道的:梯度是一个张量且维数(把
R
\boldsymbol{R}
R划分为列向量,然后用前文的方法一来分析会比较清晰)为:
d
K
d
R
∈
R
(
N
×
N
)
×
(
M
×
N
)
(
5.94
)
\frac{\mathrm{d} \boldsymbol{K}}{\mathrm{d} \boldsymbol{R}} \in \mathbb{R}^{(N \times N) \times(M \times N)}\qquad(5.94)
dRdK∈R(N×N)×(M×N)(5.94)
且对于
p
,
q
=
1
,
…
,
N
p, q=1, \ldots, N
p,q=1,…,N:
d
K
p
q
d
R
∈
R
1
×
M
×
N
\frac{\mathrm{d} K_{p q}}{\mathrm{~d} \boldsymbol{R}} \in \mathbb{R}^{1 \times M \times N}
dRdKpq∈R1×M×N
其中
K
p
q
K_{pq}
Kpq为
K
=
f
(
R
)
\boldsymbol{K}=\boldsymbol{f}(\boldsymbol{R})
K=f(R)的在
(
p
,
q
)
(p,q)
(p,q)上的元素。用
r
i
\boldsymbol{r}_i
ri表示
R
\boldsymbol{R}
R的第
i
i
i列,
K
\boldsymbol{K}
K的每一项都是
R
\boldsymbol{R}
R的两列的点积,即:
K
p
q
=
r
p
⊤
r
q
=
∑
m
=
1
M
R
m
p
R
m
q
K_{p q}=\boldsymbol{r}_{p}^{\top} \boldsymbol{r}_{q}=\sum_{m=1}^{M} R_{m p} R_{m q}
Kpq=rp⊤rq=m=1∑MRmpRmq
现在我们计算偏微分
∂
K
p
q
∂
R
i
j
\frac{\partial K_{p q}}{\partial R_{i j}}
∂Rij∂Kpq,我们得到:
∂
K
p
q
∂
R
i
j
=
∑
m
=
1
M
∂
∂
R
i
j
R
m
p
R
m
q
=
∂
p
q
i
j
\frac{\partial K_{p q}}{\partial R_{i j}}=\sum_{m=1}^{M} \frac{\partial}{\partial R_{i j}} R_{m p} R_{m q}=\partial_{p q i j}
∂Rij∂Kpq=m=1∑M∂Rij∂RmpRmq=∂pqij
∂
p
q
i
j
=
{
R
i
q
if
j
=
p
,
p
≠
q
R
i
p
if
j
=
q
,
p
≠
q
2
R
i
q
if
j
=
p
,
p
=
q
0
otherwise
(
5.98
)
\partial_{p q i j}=\left\{\begin{array}{ll}R_{i q} & \text { if } j=p, p \neq q \\R_{i p} & \text { if } j=q, p \neq q \\2 R_{i q} & \text { if } j=p, p=q \\0 & \text { otherwise }\end{array}\right.\qquad (5.98)
∂pqij=⎩⎪⎪⎨⎪⎪⎧RiqRip2Riq0 if j=p,p=q if j=q,p=q if j=p,p=q otherwise (5.98)
从 (5.94)可知我们期望的梯度维度为
(
N
×
N
)
×
(
M
×
N
)
(N\times N)\times (M\times N)
(N×N)×(M×N),且这个张量的各个元素有(5.98)的
∂
p
q
i
j
\partial_{p q i j}
∂pqij给出,其中
p
,
q
,
j
=
1
,
…
,
N
p, q, j=1, \ldots, N
p,q,j=1,…,N,
i
=
1
,
…
,
M
i=1, \ldots, M
i=1,…,M。
5.5 计算梯度的有用恒等式
下面,我们列出了机器学习中经常需要的一些有用的梯度 (Petersen and Pedersen, 2012)。这里,我们使用
tr
(
⋅
)
\operatorname{tr}(\cdot)
tr(⋅)作为迹(见定义4.4),
det
(
⋅
)
\operatorname{det}(\cdot)
det(⋅)作为行列式(见第4.1节),假设
f
(
X
)
\boldsymbol{f}(\boldsymbol{X})
f(X)的倒数存在,为
f
(
X
)
−
1
\boldsymbol{f}(\boldsymbol{X})^{-1}
f(X)−1。
∂
∂
X
f
(
X
)
⊤
=
(
∂
f
(
X
)
∂
X
)
⊤
(
5.99
)
\frac{\partial}{\partial \boldsymbol{X}} \boldsymbol{f}(\boldsymbol{X})^{\top}=\left(\frac{\partial \boldsymbol{f}(\boldsymbol{X})}{\partial \boldsymbol{X}}\right)^{\top}\qquad (5.99)
∂X∂f(X)⊤=(∂X∂f(X))⊤(5.99)
∂
∂
X
tr
(
f
(
X
)
)
=
tr
(
∂
f
(
X
)
∂
X
)
\frac{\partial}{\partial \boldsymbol{X}} \operatorname{tr}(\boldsymbol{f}(\boldsymbol{X}))=\operatorname{tr}\left(\frac{\partial \boldsymbol{f}(\boldsymbol{X})}{\partial \boldsymbol{X}}\right)
∂X∂tr(f(X))=tr(∂X∂f(X))
∂
∂
X
det
(
f
(
X
)
)
=
det
(
f
(
X
)
)
tr
(
f
(
X
)
−
1
∂
f
(
X
)
∂
X
)
\frac{\partial}{\partial \boldsymbol{X}} \operatorname{det}(\boldsymbol{f}(\boldsymbol{X}))=\operatorname{det}(\boldsymbol{f}(\boldsymbol{X})) \operatorname{tr}\left(\boldsymbol{f}(\boldsymbol{X})^{-1} \frac{\partial \boldsymbol{f}(\boldsymbol{X})}{\partial \boldsymbol{X}}\right)
∂X∂det(f(X))=det(f(X))tr(f(X)−1∂X∂f(X))
∂
a
⊤
X
−
1
b
∂
X
=
−
(
X
−
1
)
⊤
a
b
⊤
(
X
−
1
)
⊤
(
5.102
)
\frac{\partial \boldsymbol{a}^{\top} \boldsymbol{X}^{-1} \boldsymbol{b}}{\partial \boldsymbol{X}}=-\left(\boldsymbol{X}^{-1}\right)^{\top} \boldsymbol{a} \boldsymbol{b}^{\top}\left(\boldsymbol{X}^{-1}\right)^{\top}\qquad (5.102)
∂X∂a⊤X−1b=−(X−1)⊤ab⊤(X−1)⊤(5.102)
∂
x
⊤
a
∂
x
=
a
⊤
\frac{\partial \boldsymbol{x}^{\top} \boldsymbol{a}}{\partial \boldsymbol{x}}=\boldsymbol{a}^{\top}
∂x∂x⊤a=a⊤
∂
a
⊤
x
∂
x
=
a
⊤
\frac{\partial \boldsymbol{a}^{\top} \boldsymbol{x}}{\partial \boldsymbol{x}}=\boldsymbol{a}^{\top}
∂x∂a⊤x=a⊤
∂
a
⊤
X
b
∂
X
=
a
b
⊤
\frac{\partial \boldsymbol{a}^{\top} \boldsymbol{X} \boldsymbol{b}}{\partial \boldsymbol{X}}=\boldsymbol{a} \boldsymbol{b}^{\top}
∂X∂a⊤Xb=ab⊤
∂ x ⊤ B x ∂ x = x ⊤ ( B + B ⊤ ) \frac{\partial \boldsymbol{x}^{\top} \boldsymbol{B} \boldsymbol{x}}{\partial \boldsymbol{x}}=\boldsymbol{x}^{\top}\left(\boldsymbol{B}+\boldsymbol{B}^{\top}\right) ∂x∂x⊤Bx=x⊤(B+B⊤)
对于对称矩阵
W
\boldsymbol{W}
W
∂
∂
s
(
x
−
A
s
)
⊤
W
(
x
−
A
s
)
=
−
2
(
x
−
A
s
)
⊤
W
A
\frac{\partial}{\partial \boldsymbol{s}}(\boldsymbol{x}-\boldsymbol{A} \boldsymbol{s})^{\top} \boldsymbol{W}(\boldsymbol{x}-\boldsymbol{A} \boldsymbol{s})=-2(\boldsymbol{x}-\boldsymbol{A} \boldsymbol{s})^{\top} \boldsymbol{W} \boldsymbol{A}
∂s∂(x−As)⊤W(x−As)=−2(x−As)⊤WA
备注:
在这本书中,我们只讨论了矩阵的迹和转置。然而,我们已经看到导数的对象可以是高维的张量,在这种情况下,一般的迹和转置是没有定义的。在这种情况下,
D
×
D
×
E
×
F
D×D×E×F
D×D×E×F张量的迹是
E
×
F
E×F
E×F维矩阵。这是张量收缩的一个特例。类似地,当我们“转置”张量时,则交换它的前两个维度。具体来说,(5.99)到(5.102),当我们处理多元函数
f
(
⋅
)
\boldsymbol{f}(\cdot)
f(⋅)和计算矩阵的导数时,我们需要进行张量相关的特殊计算(并选择不进行如第5.4节所述都向量化)。
5.6 反向传播与自动微分法
在许多机器学习应用中,我们通过执行梯度下降(第7.1节)来找到好的模型参数,这基于我们可以计算目标函数相对于模型参数的梯度。对于给定的目标函数,我们可以通过微积分和应用链式法则来获得关于模型参数的梯度;见第5.2.2节。在第5.3节中,我们已经研究了线性回归模型的平方损失函数的梯度。
考虑函数
f
(
x
)
=
x
2
+
exp
(
x
2
)
+
cos
(
x
2
+
exp
(
x
2
)
)
(
5.109
)
f(x)=\sqrt{x^{2}+\exp \left(x^{2}\right)}+\cos \left(x^{2}+\exp \left(x^{2}\right)\right)\qquad(5.109)
f(x)=x2+exp(x2)+cos(x2+exp(x2))(5.109)
通过应用链式法则,我们可以计算梯度:
d
f
d
x
=
2
x
+
2
x
exp
(
x
2
)
2
x
2
+
exp
(
x
2
)
−
sin
(
x
2
+
exp
(
x
2
)
)
(
2
x
+
2
x
exp
(
x
2
)
)
\frac{\mathrm{d} f}{\mathrm{~d} x}=\frac{2 x+2 x \exp \left(x^{2}\right)}{2 \sqrt{x^{2}+\exp \left(x^{2}\right)}}-\sin \left(x^{2}+\exp \left(x^{2}\right)\right)\left(2 x+2 x \exp \left(x^{2}\right)\right)
dxdf=2x2+exp(x2)2x+2xexp(x2)−sin(x2+exp(x2))(2x+2xexp(x2))
=
2
x
(
1
2
x
2
+
exp
(
x
2
)
−
sin
(
x
2
+
exp
(
x
2
)
)
)
(
1
+
exp
(
x
2
)
)
(
5.110
)
=2 x\left(\frac{1}{2 \sqrt{x^{2}+\exp \left(x^{2}\right)}}-\sin \left(x^{2}+\exp \left(x^{2}\right)\right)\right)\left(1+\exp \left(x^{2}\right)\right) \qquad(5.110)
=2x(2x2+exp(x2)1−sin(x2+exp(x2)))(1+exp(x2))(5.110)
以这种方式写出梯度通常是不切实际的,因为它常常导致导数的表达式非常冗长。在实践中意味着梯度的实现可能比计算函数值还要更多的计算开销。对于训练深度神经网络模型,反向传播( backpropagation)算法((Kelley, 1960; Bryson, 1961; Dreyfus, 1962; Rumelhart et al., 1986)是计算误差函数相对于模型参数的梯度的有效方法。
5.6.1 深度网络中的梯度
链式法则被发挥到极致的一个领域是深度学习,其中函数值
y
\boldsymbol{y}
y为多级函数组合
y
=
(
f
K
∘
f
K
−
1
∘
⋯
∘
f
1
)
(
x
)
=
f
K
(
f
K
−
1
(
⋯
(
f
1
(
x
)
)
⋯
)
)
\boldsymbol{y}=\left(f_{K} \circ f_{K-1} \circ \cdots \circ f_{1}\right)(\boldsymbol{x})=f_{K}\left(f_{K-1}\left(\cdots\left(f_{1}(\boldsymbol{x})\right) \cdots\right)\right)
y=(fK∘fK−1∘⋯∘f1)(x)=fK(fK−1(⋯(f1(x))⋯))
其中
x
\boldsymbol{x}
x为输入(例如:图像),
y
\boldsymbol{y}
y为观测值(例如:类别标签),且每一个
f
i
,
i
=
1
,
…
,
K
f_{i}, i=1, \ldots, K
fi,i=1,…,K都拥有自己的参数。
在多层神经网络中,我们在第
i
i
i层有函数
f
i
(
x
i
−
1
)
=
σ
(
A
i
−
1
x
i
−
1
+
b
i
−
1
)
f_{i}\left(\boldsymbol{x}_{i-1}\right)=\sigma\left(\boldsymbol{A}_{i-1} \boldsymbol{x}_{i-1}+\boldsymbol{b}_{i-1}\right)
fi(xi−1)=σ(Ai−1xi−1+bi−1)。这里
x
i
−
1
\boldsymbol{x}_{i-1}
xi−1是第
i
−
1
i−1
i−1层的输出而
σ
\sigma
σ为激活函数,激活函数可以是logistic sigmoid
1
1
+
e
−
x
\frac{1}{1+e^{-x}}
1+e−x1、tanh或rectified linear unit (ReLU)等。为了训练这些模型,我们需要求损失函数
L
L
L对于所有模型参数
A
j
\boldsymbol{A}_j
Aj,
b
j
\boldsymbol{b}_j
bj的梯度,其中
j
=
1
,
…
,
K
j=1, \ldots, K
j=1,…,K。这也要求我们计算
L
L
L相对于每层输入的梯度。例如,如果我们有输入
x
\boldsymbol{x}
x和观测值
y
\boldsymbol{y}
y,则网络结构由以下定义:
f
0
:
=
x
\boldsymbol{f}_{0}:=\boldsymbol{x}
f0:=x
f
i
:
=
σ
i
(
A
i
−
1
f
i
−
1
+
b
i
−
1
)
,
i
=
1
,
…
,
K
\boldsymbol{f}_{i}:=\sigma_{i}\left(\boldsymbol{A}_{i-1} \boldsymbol{f}_{i-1}+\boldsymbol{b}_{i-1}\right), \quad i=1, \ldots, K
fi:=σi(Ai−1fi−1+bi−1),i=1,…,K
将其可视化如图5.8所示。
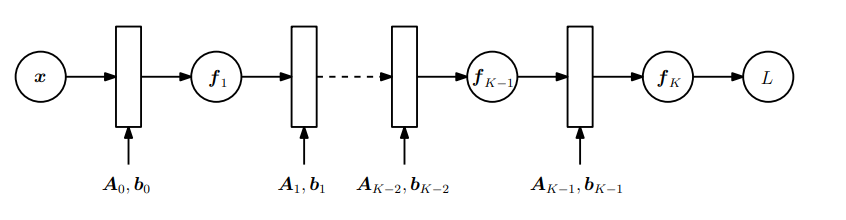
图5.8多层神经网络的前向传递,计算
x
\boldsymbol{x}
x作为输入,
A
i
,
b
i
\boldsymbol{A}_i, \boldsymbol{b}_i
Ai,bi参数的函数
L
\boldsymbol{L}
L的损失。
我们目的是找到
A
j
,
b
j
,
j
=
0
,
…
,
K
−
1
\boldsymbol{A}_{j}, \boldsymbol{b}_{j} , j=0, \ldots, K-1
Aj,bj,j=0,…,K−1,使得平方损失:
L
(
θ
)
=
∥
y
−
f
K
(
θ
,
x
)
∥
2
L(\boldsymbol{\theta})=\left\|\boldsymbol{y}-\boldsymbol{f}_{K}(\boldsymbol{\theta}, \boldsymbol{x})\right\|^{2}
L(θ)=∥y−fK(θ,x)∥2
最小。其中:
θ
=
{
A
0
,
b
0
,
…
,
A
K
−
1
,
b
K
−
1
}
\boldsymbol{\theta}=\left\{\boldsymbol{A}_{0}, \boldsymbol{b}_{0}, \ldots, \boldsymbol{A}_{K-1}, \boldsymbol{b}_{K-1}\right\}
θ={A0,b0,…,AK−1,bK−1}。
为了得到关于参数集
θ
\boldsymbol{\theta}
θ的梯度,我们需要计算
L
L
L对于每层参数
θ
j
=
{
A
j
,
b
j
}
,
j
=
0
,
…
,
K
−
1
\boldsymbol{\theta}_{j}=\left\{\boldsymbol{A}_{j}, \boldsymbol{b}_{j}\right\},j=0, \ldots, K-1
θj={Aj,bj},j=0,…,K−1的偏导数。链式法则允许我们确定偏导数为:

橙色项是每一层的输出相对其输入的偏导数,而蓝色项是每一层的输出相对于其参数的偏导数。假设我们已经计算了偏导数
∂
L
/
∂
θ
i
+
1
\partial L / \partial \boldsymbol{\theta}_{i+1}
∂L/∂θi+1,那么大部分的计算结果可以被重用来计算
∂
L
/
∂
θ
i
\partial L / \partial \boldsymbol{\theta}_{i}
∂L/∂θi。我们将需要另外计算的附加项用方框表示。图5.9展示了梯度通过网络向后传递。
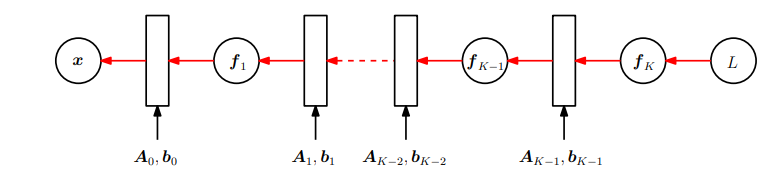
图 5.9多层神经网络反向传播计算损失函数的梯度。
5.6.2 自动微分
其实,反向传播是数值分析中称为自动微分(automatic differentiation)技术的一个特例。我们可以把自动微分看作是一套技术,它通过处理中间变量和应用链式法则,在数值上(而不是符号化地)计算函数的精确(达到机器精度)梯度。自动微分应用了一系列基本算术运算,例如加法和乘法,以及基本函数,例如:
sin
,
cos
,
exp
,
log
\sin , \cos , \exp , \log
sin,cos,exp,log。将链式法则应用到这些运算中,可以自动计算相当复杂函数的梯度。自动微分适用于一般的计算机程序,有正向和反向两种模式。Baydin等人(2018年)对机器学习中的自动微分进行了很好的概述。
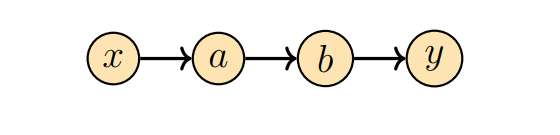
图 5.10一个简单的图,说明了通过中间变量
a
,
b
a, b
a,b的从
x
x
x到
y
y
y的数据流。
图 5.10显示了一个简单的图,表示输入
x
x
x通过一些中间变量
a
、
b
a、b
a、b到输出
y
y
y的数据流。如果我们要计算导数
d
y
/
d
x
\mathrm{d} y / \mathrm{d} x
dy/dx,我们应用链式法则可得到:
d
y
d
x
=
d
y
d
b
d
b
d
a
d
a
d
x
\frac{\mathrm{d} y}{\mathrm{~d} x}=\frac{\mathrm{d} y}{\mathrm{~d} b} \frac{\mathrm{d} b}{\mathrm{~d} a} \frac{\mathrm{d} a}{\mathrm{~d} x}
dxdy= dbdy dadb dxda
直观地说,正向和反向模式在乘法的顺序上是不同的。由于矩阵乘法的结合性,我们有以下两种选择:
d
y
d
x
=
(
d
y
d
b
d
b
d
a
)
d
a
d
x
(
5.120
)
\frac{\mathrm{d} y}{\mathrm{~d} x}=\left(\frac{\mathrm{d} y}{\mathrm{~d} b} \frac{\mathrm{d} b}{\mathrm{~d} a}\right) \frac{\mathrm{d} a}{\mathrm{~d} x}\qquad (5.120)
dxdy=( dbdy dadb) dxda(5.120)
d
y
d
x
=
d
y
d
b
(
d
b
d
a
d
a
d
x
)
(
5.121
)
\frac{\mathrm{d} y}{\mathrm{~d} x}=\frac{\mathrm{d} y}{\mathrm{~d} b}\left(\frac{\mathrm{d} b}{\mathrm{~d} a} \frac{\mathrm{d} a}{\mathrm{~d} x}\right)\qquad (5.121)
dxdy= dbdy( dadb dxda)(5.121)
方程(5.120)是反向模式( reverse mode),因为梯度通过数据流向后传播。方程(5.121)是正向模式(forward mode),其中梯度随数据从左到右流过整个图。
下面,我们将重点介绍反向模式的自动微分,即反向传播。在神经网络中,输入的维数通常比标签的维数高得多,所以反向模式比正向模式计算量要少得多。让我们从一个例子开始。
例 5.14
考虑函数:
f
(
x
)
=
x
2
+
exp
(
x
2
)
+
cos
(
x
2
+
exp
(
x
2
)
)
(
5.109
)
f(x)=\sqrt{x^{2}+\exp \left(x^{2}\right)}+\cos \left(x^{2}+\exp \left(x^{2}\right)\right)\qquad (5.109)
f(x)=x2+exp(x2)+cos(x2+exp(x2))(5.109)
如果我们在计算机上实现一个函数
f
f
f,我们可以通过以下中间变量(intermediate variables)来节省一些计算量:
a
=
x
2
b
=
exp
(
a
)
c
=
a
+
b
d
=
c
e
=
cos
(
c
)
f
=
d
+
e
\begin{array}{l}a=x^{2} \\b=\exp (a) \\c=a+b \\d=\sqrt{c} \\e=\cos (c) \\f=d+e\end{array}
a=x2b=exp(a)c=a+bd=ce=cos(c)f=d+e
这与应用链式法则时的思维过程是相同的。注意,前面的方程组需要的运算比(5.109)直接定义函数 f ( x ) f(x) f(x)少。图5.11显示了要获得函数值 f f f所需的数据流和计算。
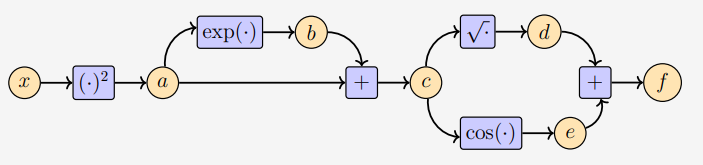
图 5.11 输入
x
x
x,函数值f和中间变量
a
,
b
,
c
,
d
,
e
a, b, c, d, e
a,b,c,d,e的计算图。
包含中间变量的方程组可以看作是一个计算图,这是一种广泛用于实现神经网络软件库的表示。通过调用定义的初等函数导数,我们可以直接计算中间变量对其相应输入的导数。我们得到以下结果:
∂
a
∂
x
=
2
x
\frac{\partial a}{\partial x}=2 x
∂x∂a=2x
∂
b
∂
a
=
exp
(
a
)
\frac{\partial b}{\partial a}=\exp (a)
∂a∂b=exp(a)
∂
c
∂
a
=
1
=
∂
c
∂
b
\frac{\partial c}{\partial a}=1=\frac{\partial c}{\partial b}
∂a∂c=1=∂b∂c
∂
d
∂
c
=
1
2
c
\frac{\partial d}{\partial c}=\frac{1}{2 \sqrt{c}}
∂c∂d=2c1
∂
e
∂
c
=
−
sin
(
c
)
\frac{\partial e}{\partial c}=-\sin (c)
∂c∂e=−sin(c)
∂
f
∂
d
=
1
=
∂
f
∂
e
\frac{\partial f}{\partial d}=1=\frac{\partial f}{\partial e}
∂d∂f=1=∂e∂f
通过查看计算图,我们可以从输出向后计算
∂
f
/
∂
x
\partial f / \partial x
∂f/∂x:
∂
f
∂
c
=
∂
f
∂
d
∂
d
∂
c
+
∂
f
∂
e
∂
e
∂
c
\frac{\partial f}{\partial c}=\frac{\partial f}{\partial d} \frac{\partial d}{\partial c}+\frac{\partial f}{\partial e} \frac{\partial e}{\partial c}
∂c∂f=∂d∂f∂c∂d+∂e∂f∂c∂e
∂
f
∂
b
=
∂
f
∂
c
∂
c
∂
b
\frac{\partial f}{\partial b}=\frac{\partial f}{\partial c} \frac{\partial c}{\partial b}
∂b∂f=∂c∂f∂b∂c
∂
f
∂
a
=
∂
f
∂
b
∂
b
∂
a
+
∂
f
∂
c
∂
c
∂
a
\frac{\partial f}{\partial a}=\frac{\partial f}{\partial b} \frac{\partial b}{\partial a}+\frac{\partial f}{\partial c} \frac{\partial c}{\partial a}
∂a∂f=∂b∂f∂a∂b+∂c∂f∂a∂c
∂
f
∂
x
=
∂
f
∂
a
∂
a
∂
x
\frac{\partial f}{\partial x}=\frac{\partial f}{\partial a} \frac{\partial a}{\partial x}
∂x∂f=∂a∂f∂x∂a
注意,我们隐式地应用链式规则来获得
∂
f
/
∂
x
\partial f / \partial x
∂f/∂x。通过替换初等函数导数的结果,我们得到
∂
f
∂
c
=
1
⋅
1
2
c
+
1
⋅
(
−
sin
(
c
)
)
\frac{\partial f}{\partial c}=1 \cdot \frac{1}{2 \sqrt{c}}+1 \cdot(-\sin (c))
∂c∂f=1⋅2c1+1⋅(−sin(c))
∂
f
∂
b
=
∂
f
∂
c
⋅
1
\frac{\partial f}{\partial b}=\frac{\partial f}{\partial c} \cdot 1
∂b∂f=∂c∂f⋅1
∂
f
∂
a
=
∂
f
∂
b
exp
(
a
)
+
∂
f
∂
c
⋅
1
\frac{\partial f}{\partial a}=\frac{\partial f}{\partial b} \exp (a)+\frac{\partial f}{\partial c} \cdot 1
∂a∂f=∂b∂fexp(a)+∂c∂f⋅1
∂
f
∂
x
=
∂
f
∂
a
⋅
2
x
\frac{\partial f}{\partial x}=\frac{\partial f}{\partial a} \cdot 2 x
∂x∂f=∂a∂f⋅2x
通过将上述每一个导数看作一个变量,我们观察到计算导数所需的计算与函数本身的计算具有相似的复杂度。这是非常反直觉的,要知道导数 ∂ f ∂ x \frac{\partial f}{\partial x} ∂x∂f的数学表达式(5.110)比(5.109)中函数 f ( x ) f(x) f(x)的数学表达式要复杂得多。
自动微分是示例5.14的形式化。令
x
1
,
…
,
x
d
x_{1}, \ldots, x_{d}
x1,…,xd是函数的输入变量,
x
d
+
1
,
…
,
x
D
−
1
x_{d+1}, \ldots, x_{D-1}
xd+1,…,xD−1为中间变量,
x
D
x_D
xD为输出变量。那么计算图可以表示为:
For
i
=
d
+
1
,
…
,
D
:
x
i
=
g
i
(
x
Pa
(
x
i
)
)
(
5.143
)
\text { For } i=d+1, \ldots, D: \quad x_{i}=g_{i}\left(x_{\operatorname{Pa}\left(x_{i}\right)}\right)\qquad (5.143)
For i=d+1,…,D:xi=gi(xPa(xi))(5.143)
其中
g
i
(
⋅
)
g_{i}(\cdot)
gi(⋅)是初等函数,
x
P
a
(
x
i
)
x_{\mathrm{Pa}\left(x_{i}\right)}
xPa(xi)是图中变量
x
i
x_i
xi的父节点。给定一个这样定义的函数,我们可以用链式法则一步一步地计算函数的导数。我们定义
f
=
x
D
f=x_{D}
f=xD,那么有:
∂
f
∂
x
D
=
1
\frac{\partial f}{\partial x_{D}}=1
∂xD∂f=1
对于其他变量
x
i
x_i
xi,我们应用链式法则:
∂
f
∂
x
i
=
∑
x
j
:
x
i
∈
Pa
(
x
j
)
∂
f
∂
x
j
∂
x
j
∂
x
i
=
∑
x
j
:
x
i
∈
Pa
(
x
j
)
∂
f
∂
x
j
∂
g
j
∂
x
i
(
5.145
)
\frac{\partial f}{\partial x_{i}}=\sum_{x_{j}: x_{i} \in \operatorname{Pa}\left(x_{j}\right)} \frac{\partial f}{\partial x_{j}} \frac{\partial x_{j}}{\partial x_{i}}=\sum_{x_{j}: x_{i} \in \operatorname{Pa}\left(x_{j}\right)} \frac{\partial f}{\partial x_{j}} \frac{\partial g_{j}}{\partial x_{i}}\qquad (5.145)
∂xi∂f=xj:xi∈Pa(xj)∑∂xj∂f∂xi∂xj=xj:xi∈Pa(xj)∑∂xj∂f∂xi∂gj(5.145)
其中 Pa ( x j ) \operatorname{Pa}\left(x_{j}\right) Pa(xj)是计算图中 x j x_j xj的父节点集。方程(5.143)是函数的正向传播,而(5.145)是梯度,它通过计算图的反向传播梯度。对于神经网络训练,我们将相对于标签的预测误差进行反向传播。
当我们有一个可以表示为计算图的函数,且它的各个元素函数是可微的时,上面的自动微分方法就能起作用。实际上,这个函数甚至可以不是一个数学函数,而是一个计算机程序。然而,并不是所有的计算机程序都能被求微分,例如在我们找不到关于它的微分初等函数的情况。对于for循环和if语句这样的编程结构,也需要注意。
5.7 高阶导数
到目前为止,我们已经讨论了梯度,即一阶导数。有时,我们对高阶导数感兴趣,例如,当我们想使用牛顿法进行优化时,需要二阶导数(Nocedal和Wright,2006)。在第5.1.1节中,我们讨论了用多项式逼近函数的泰勒级数。在多变量的情况下,我们可以做完全相同的事情。让我们从定义一些符号开始。
考虑有两个变量 x , y x,y x,y的函数 f : R 2 → R f: \mathbb{R}^{2} \rightarrow \mathbb{R} f:R2→R。对于高阶偏导数(和梯度),我们使用以下表示法:
- ∂ 2 f ∂ x 2 \frac{\partial^{2} f}{\partial x^{2}} ∂x2∂2f为 f f f关于 x x x的二阶偏导。
- ∂ n f ∂ x n \frac{\partial^{n} f}{\partial x^{n}} ∂xn∂nf为 f f f关于 x x x的 n n n阶偏导。
- ∂ 2 f ∂ y ∂ x = ∂ ∂ y ( ∂ f ∂ x ) \frac{\partial^{2} f}{\partial y \partial x}=\frac{\partial}{\partial y}\left(\frac{\partial f}{\partial x}\right) ∂y∂x∂2f=∂y∂(∂x∂f)为 f f f先对 x x x求偏微分,然后对 y y y求偏微分得到的偏导数。
- ∂ 2 f ∂ x ∂ y = ∂ ∂ x ( ∂ f ∂ y ) \frac{\partial^{2} f}{\partial x \partial y}=\frac{\partial}{\partial x}\left(\frac{\partial f}{\partial y}\right) ∂x∂y∂2f=∂x∂(∂y∂f)为 f f f先对 y y y求偏微分,然后对 x x x求偏微分得到的偏导数。
Hessian矩阵由所有二阶偏导数的组成。
如果
f
(
x
,
y
)
f(x,y)
f(x,y)是两次(连续)可微函数,那么
∂
2
f
∂
x
∂
y
=
∂
2
f
∂
y
∂
x
\frac{\partial^{2} f}{\partial x \partial y}=\frac{\partial^{2} f}{\partial y \partial x}
∂x∂y∂2f=∂y∂x∂2f
也就是说,微分的次序并不重要,相应的Hessian矩阵为
H
=
[
∂
2
f
∂
x
2
∂
2
f
∂
x
∂
y
∂
2
f
∂
x
∂
y
∂
2
f
∂
y
2
]
\boldsymbol{H}=\left[\begin{array}{cc}\frac{\partial^{2} f}{\partial x^{2}} & \frac{\partial^{2} f}{\partial x \partial y} \\\frac{\partial^{2} f}{\partial x \partial y} & \frac{\partial^{2} f}{\partial y^{2}}\end{array}\right]
H=[∂x2∂2f∂x∂y∂2f∂x∂y∂2f∂y2∂2f]
它是对称的。Hessian矩阵被表示为: ∇ x , y 2 f ( x , y ) \nabla_{x, y}^{2} f(x, y) ∇x,y2f(x,y)。一般地,对于 x ∈ R n \boldsymbol{x} \in \mathbb{R}^{n} x∈Rn和 f : R n → R f: \mathbb{R}^{n} \rightarrow \mathbb{R} f:Rn→R,Hessian矩阵是 n × n n×n n×n矩阵。Hessian矩阵度量函数在 ( x , y ) (x,y) (x,y)附近的局部曲率。
备注: 向量场的Hessian函数
如果 f : R n → R m f: \mathbb{R}^{n} \rightarrow \mathbb{R}^{m} f:Rn→Rm为向量场,则其对应的Hessian函数是一个 ( m × n × n ) (m × n × n) (m×n×n)的张量。
5.8 线性化与多元泰勒级数
函数
f
f
f的梯度
∇
f
\nabla f
∇f经常用于
x
0
\boldsymbol{x}_{0}
x0附近的局部线性近似
f
(
x
)
≈
f
(
x
0
)
+
(
∇
x
f
)
(
x
0
)
(
x
−
x
0
)
(
5.148
)
f(\boldsymbol{x}) \approx f\left(\boldsymbol{x}_{0}\right)+\left(\nabla_{\boldsymbol{x}} f\right)\left(\boldsymbol{x}_{0}\right)\left(\boldsymbol{x}-\boldsymbol{x}_{0}\right)\qquad (5.148)
f(x)≈f(x0)+(∇xf)(x0)(x−x0)(5.148)
这里
(
∇
x
f
)
(
x
0
)
\left(\nabla_{\boldsymbol{x}} f\right)\left(\boldsymbol{x}_{0}\right)
(∇xf)(x0)为
f
f
f相对于
x
\boldsymbol{x}
x的梯度并用
x
0
\boldsymbol{x}_{0}
x0代入计算。
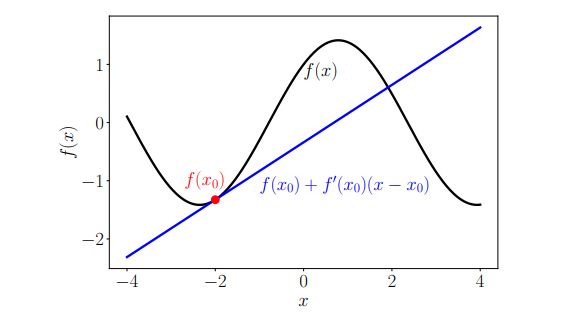
图 5.12函数的线性近似。使用一阶泰勒级数展开来将原始函数
f
f
f在
x
0
=
−
2
x_0 =−2
x0=−2处线性化。
图 5.12展示了输入 x 0 \boldsymbol{x}_{0} x0处函数 f f f的线性近似。原始函数被一条直线近似。这个近似值是局部精确的,即离 x 0 \boldsymbol{x}_{0} x0越远,近似值就越不精确。方程(5.148)是 f f f在 x 0 \boldsymbol{x}_{0} x0处的多变量泰勒级数展开的特例,这里我们只考虑前两项。我们将在下面讨论更一般的情况,这将达到更好的近似。
定义 5.7多变量泰勒级数
我们考虑函数:
f
:
R
D
→
R
x
↦
f
(
x
)
,
x
∈
R
D
\begin{aligned}f: \mathbb{R}^{D} & \rightarrow \mathbb{R} \\& \boldsymbol{x} \mapsto f(\boldsymbol{x}), \quad \boldsymbol{x} \in \mathbb{R}^{D}\end{aligned}
f:RD→Rx↦f(x),x∈RD
在
x
0
\boldsymbol{x}_0
x0处光滑。当我们定义差分向量
δ
:
=
x
−
x
0
\boldsymbol{\delta}:=\boldsymbol{x}-\boldsymbol{x}_{0}
δ:=x−x0,则
f
f
f在
x
0
\boldsymbol{x}_{0}
x0的多变量泰勒级数( multivariate Taylor series)为:
f
(
x
)
=
∑
k
=
0
∞
D
x
k
f
(
x
0
)
k
!
δ
k
(
5.151
)
f(\boldsymbol{x})=\sum_{k=0}^{\infty} \frac{D_{\boldsymbol{x}}^{k} f\left(\boldsymbol{x}_{0}\right)}{k !} \boldsymbol{\delta}^{k}\qquad (5.151)
f(x)=k=0∑∞k!Dxkf(x0)δk(5.151)
式中, D x k f ( x 0 ) D_{\boldsymbol{x}}^{k} f\left(\boldsymbol{x}_{0}\right) Dxkf(x0)是 f f f对 x \boldsymbol{x} x的第 k k k阶导数,并在 x 0 \boldsymbol{x}_0 x0处求值
定义 5.8 泰勒多项式
x
0
\boldsymbol{x}_{0}
x0处
f
f
f的
n
n
n次泰勒多项式包含(5.151)中级数的前
n
+
1
n+1
n+1个分量,定义为
T
n
(
x
)
=
∑
k
=
0
n
D
x
k
f
(
x
0
)
k
!
δ
k
(
5.152
)
T_{n}(\boldsymbol{x})=\sum_{k=0}^{n} \frac{D_{\boldsymbol{x}}^{k} f\left(\boldsymbol{x}_{0}\right)}{k !} \boldsymbol{\delta}^{k}\qquad (5.152)
Tn(x)=k=0∑nk!Dxkf(x0)δk(5.152)
在(5.151)和(5.152)中,我们使用了略微粗略的 δ k \boldsymbol{\delta}^{k} δk表示法,这对于 x ∈ R D , D > 1 \boldsymbol{x} \in \mathbb{R}^{D}, \quad D>1 x∈RD,D>1和 k > 1 k\gt 1 k>1情况下是无定义的。
要注意,
D
x
k
f
D_{\boldsymbol{x}}^{k} f
Dxkf和
δ
k
\boldsymbol{\delta}^{k}
δk都是
k
k
k阶张量,即
k
k
k维数组。
k
k
k阶张量
δ
k
∈
R
D
×
D
×
…
×
D
⏞
k
times
\boldsymbol{\delta}^{k} \in \mathbb{R}^{\overbrace{D \times D \times \ldots \times D}^{k \text { times }}}
δk∈RD×D×…×D
k times 由
δ
∈
R
D
\boldsymbol{\delta} \in \mathbb{R}^{D}
δ∈RD的
k
k
k倍外积(表示为
⊗
\otimes
⊗)得到。例如:
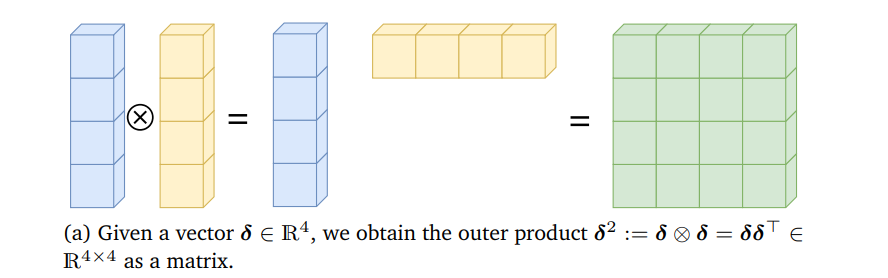
δ
2
:
=
δ
⊗
δ
=
δ
δ
⊤
,
δ
2
[
i
,
j
]
=
δ
[
i
]
δ
[
j
]
\boldsymbol{\delta}^{2}:=\boldsymbol{\delta} \otimes \boldsymbol{\delta}=\boldsymbol{\delta} \boldsymbol{\delta}^{\top}, \quad \boldsymbol{\delta}^{2}[i, j]=\delta[i] \delta[j]
δ2:=δ⊗δ=δδ⊤,δ2[i,j]=δ[i]δ[j]
δ
3
:
=
δ
⊗
δ
⊗
δ
,
δ
3
[
i
,
j
,
k
]
=
δ
[
i
]
δ
[
j
]
δ
[
k
]
\boldsymbol{\delta}^{3}:=\boldsymbol{\delta} \otimes \boldsymbol{\delta} \otimes \boldsymbol{\delta}, \quad \boldsymbol{\delta}^{3}[i, j, k]=\delta[i] \delta[j] \delta[k]
δ3:=δ⊗δ⊗δ,δ3[i,j,k]=δ[i]δ[j]δ[k]
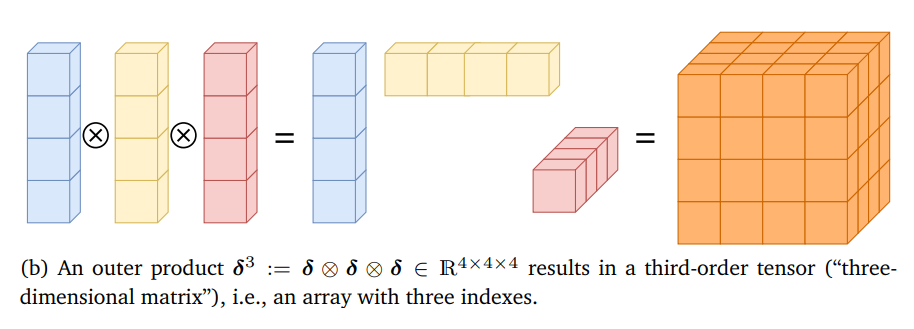
一般来说,我们可以得到泰勒级数中的项:
D
x
k
f
(
x
0
)
δ
k
=
∑
i
1
=
1
D
⋯
∑
i
k
=
1
D
D
x
k
f
(
x
0
)
[
i
1
,
…
,
i
k
]
δ
[
i
1
]
⋯
δ
[
i
k
]
D_{\boldsymbol{x}}^{k} f\left(\boldsymbol{x}_{0}\right) \boldsymbol{\delta}^{k}=\sum_{i_{1}=1}^{D} \cdots \sum_{i_{k}=1}^{D} D_{\boldsymbol{x}}^{k} f\left(\boldsymbol{x}_{0}\right)\left[i_{1}, \ldots, i_{k}\right] \delta\left[i_{1}\right] \cdots \delta\left[i_{k}\right]
Dxkf(x0)δk=i1=1∑D⋯ik=1∑DDxkf(x0)[i1,…,ik]δ[i1]⋯δ[ik]
其中 D x k f ( x 0 ) δ k D_{\boldsymbol{x}}^{k} f\left(\boldsymbol{x}_{0}\right) \boldsymbol{\delta}^{k} Dxkf(x0)δk包含 k k k阶多项式。
现在我们定义了向量场的泰勒级数,让我们显式地写出泰勒级数展开式的第一项 D x k f ( x 0 ) δ k D_{\boldsymbol{x}}^{k} f\left(\boldsymbol{x}_{0}\right) \boldsymbol{\delta}^{k} Dxkf(x0)δk,其中 k = 0 , … , 3 k=0, \ldots, 3 k=0,…,3和 δ : = x − x 0 \boldsymbol{\delta}:=\boldsymbol{x}-\boldsymbol{x}_{0} δ:=x−x0
k
=
0
:
D
x
0
f
(
x
0
)
δ
0
=
f
(
x
0
)
∈
R
k=0: D_{x}^{0} f\left(\boldsymbol{x}_{0}\right) \boldsymbol{\delta}^{0}=f\left(\boldsymbol{x}_{0}\right) \in \mathbb{R}
k=0:Dx0f(x0)δ0=f(x0)∈R
k
=
1
:
D
x
1
f
(
x
0
)
δ
1
=
∇
x
f
(
x
0
)
⏟
1
×
D
δ
⏟
D
×
1
=
∑
i
=
1
D
∇
x
f
(
x
0
)
[
i
]
δ
[
i
]
∈
R
k=1: D_{\boldsymbol{x}}^{1} f\left(\boldsymbol{x}_{0}\right) \boldsymbol{\delta}^{1}=\underbrace{\nabla_{\boldsymbol{x}} f\left(\boldsymbol{x}_{0}\right)}_{1 \times D} \underbrace{\boldsymbol{\delta}}_{D \times 1}=\sum_{i=1}^{D} \nabla_{\boldsymbol{x}} f\left(\boldsymbol{x}_{0}\right)[i] \delta[i] \in \mathbb{R}
k=1:Dx1f(x0)δ1=1×D
∇xf(x0)D×1
δ=i=1∑D∇xf(x0)[i]δ[i]∈R
k
=
2
:
D
x
2
f
(
x
0
)
δ
2
=
tr
(
H
(
x
0
)
⏟
D
×
D
δ
⏟
D
×
1
δ
⊤
⏟
1
×
D
)
=
δ
⊤
H
(
x
0
)
δ
=
∑
i
=
1
D
∑
j
=
1
D
H
[
i
,
j
]
δ
[
i
]
δ
[
j
]
∈
R
\begin{aligned}k &=2: D_{\boldsymbol{x}}^{2} f\left(\boldsymbol{x}_{0}\right) \boldsymbol{\delta}^{2}=\operatorname{tr}(\underbrace{\boldsymbol{H}\left(\boldsymbol{x}_{0}\right)}_{D \times D} \underbrace{\boldsymbol{\delta}}_{D \times 1} \underbrace{\boldsymbol{\delta}^{\top}}_{1 \times D})=\boldsymbol{\delta}^{\top} \boldsymbol{H}\left(\boldsymbol{x}_{0}\right) \boldsymbol{\delta} \\&=\sum_{i=1}^{D} \sum_{j=1}^{D} H[i, j] \delta[i] \delta[j] \in \mathbb{R}\end{aligned}
k=2:Dx2f(x0)δ2=tr(D×D
H(x0)D×1
δ1×D
δ⊤)=δ⊤H(x0)δ=i=1∑Dj=1∑DH[i,j]δ[i]δ[j]∈R
k
=
3
:
D
x
3
f
(
x
0
)
δ
3
=
∑
i
=
1
D
∑
j
=
1
D
∑
k
=
1
D
D
x
3
f
(
x
0
)
[
i
,
j
,
k
]
δ
[
i
]
δ
[
j
]
δ
[
k
]
∈
R
k=3: D_{x}^{3} f\left(\boldsymbol{x}_{0}\right) \boldsymbol{\delta}^{3}=\sum_{i=1}^{D} \sum_{j=1}^{D} \sum_{k=1}^{D} D_{x}^{3} f\left(\boldsymbol{x}_{0}\right)[i, j, k] \delta[i] \delta[j] \delta[k] \in \mathbb{R}
k=3:Dx3f(x0)δ3=i=1∑Dj=1∑Dk=1∑DDx3f(x0)[i,j,k]δ[i]δ[j]δ[k]∈R
其中
H
x
0
\boldsymbol{H}_{\boldsymbol{x}_0}
Hx0为
f
f
f在
x
0
\boldsymbol{x}_{0}
x0的Hessian矩阵
例 5.15 双变量函数的泰勒级数展开
考虑函数:
f
(
x
,
y
)
=
x
2
+
2
x
y
+
y
3
(
5.161
)
f(x, y)=x^{2}+2 x y+y^{3}\qquad (5.161)
f(x,y)=x2+2xy+y3(5.161)
我们要计算
f
f
f在
(
x
0
,
y
0
)
=
(
1
,
2
)
\left(x_{0}, y_{0}\right)=(1,2)
(x0,y0)=(1,2)时的泰勒级数展开式。在开始之前,让我们先讨论一下期望的结果:(5.161)中的函数是一个3次多项式,它本身就是多项式的线性组合。因此,我们不需要泰勒级数展开包含四阶或更高阶的项。这意味着,对于(5.161)的精确表示,只需确定(5.151)的前四项就足够了。
为了确定泰勒级数展开式,我们从常数项和一阶导数开始,它们由
f
(
1
,
2
)
=
13
f(1,2)=13
f(1,2)=13
∂
f
∂
x
=
2
x
+
2
y
⟹
∂
f
∂
x
(
1
,
2
)
=
6
\frac{\partial f}{\partial x}=2 x+2 y \Longrightarrow \frac{\partial f}{\partial x}(1,2)=6
∂x∂f=2x+2y⟹∂x∂f(1,2)=6
∂
f
∂
y
=
2
x
+
3
y
2
⟹
∂
f
∂
y
(
1
,
2
)
=
14
\frac{\partial f}{\partial y}=2 x+3 y^{2} \Longrightarrow \frac{\partial f}{\partial y}(1,2)=14
∂y∂f=2x+3y2⟹∂y∂f(1,2)=14
因此,我们得到:
D
x
,
y
1
f
(
1
,
2
)
=
∇
x
,
y
f
(
1
,
2
)
=
[
∂
f
∂
x
(
1
,
2
)
∂
f
∂
y
(
1
,
2
)
]
=
[
6
14
]
∈
R
1
×
2
D_{x, y}^{1} f(1,2)=\nabla_{x, y} f(1,2)=\left[\frac{\partial f}{\partial x}(1,2) \quad \frac{\partial f}{\partial y}(1,2)\right]=\left[\begin{array}{ll}6 & 14\end{array}\right] \in \mathbb{R}^{1 \times 2}
Dx,y1f(1,2)=∇x,yf(1,2)=[∂x∂f(1,2)∂y∂f(1,2)]=[614]∈R1×2
它使得:
D
x
,
y
1
f
(
1
,
2
)
1
!
δ
=
[
6
14
]
[
x
−
1
y
−
2
]
=
6
(
x
−
1
)
+
14
(
y
−
2
)
\frac{D_{x, y}^{1} f(1,2)}{1 !} \boldsymbol{\delta}=\left[\begin{array}{ll}6 & 14\end{array}\right]\left[\begin{array}{l}x-1 \\y-2\end{array}\right]=6(x-1)+14(y-2)
1!Dx,y1f(1,2)δ=[614][x−1y−2]=6(x−1)+14(y−2)
注意 D x , y 1 f ( 1 , 2 ) δ D_{x, y}^{1} f(1,2) \boldsymbol{\delta} Dx,y1f(1,2)δ只包含线性项,即一阶多项式
二阶偏导数由下式给出
∂
2
f
∂
x
2
=
2
⟹
∂
2
f
∂
x
2
(
1
,
2
)
=
2
\frac{\partial^{2} f}{\partial x^{2}}=2 \Longrightarrow \frac{\partial^{2} f}{\partial x^{2}}(1,2)=2
∂x2∂2f=2⟹∂x2∂2f(1,2)=2
∂
2
f
∂
y
2
=
6
y
⟹
∂
2
f
∂
y
2
(
1
,
2
)
=
12
\frac{\partial^{2} f}{\partial y^{2}}=6 y \Longrightarrow \frac{\partial^{2} f}{\partial y^{2}}(1,2)=12
∂y2∂2f=6y⟹∂y2∂2f(1,2)=12
∂
2
f
∂
y
∂
x
=
2
⟹
∂
2
f
∂
y
∂
x
(
1
,
2
)
=
2
\frac{\partial^{2} f}{\partial y \partial x}=2 \Longrightarrow \frac{\partial^{2} f}{\partial y \partial x}(1,2)=2
∂y∂x∂2f=2⟹∂y∂x∂2f(1,2)=2
∂
2
f
∂
x
∂
y
=
2
⟹
∂
2
f
∂
x
∂
y
(
1
,
2
)
=
2
\frac{\partial^{2} f}{\partial x \partial y}=2 \Longrightarrow \frac{\partial^{2} f}{\partial x \partial y}(1,2)=2
∂x∂y∂2f=2⟹∂x∂y∂2f(1,2)=2
当我们收集二阶偏导数时,我们得到了Hessian函数
H
=
[
∂
2
f
∂
x
2
∂
2
f
∂
x
∂
y
∂
2
f
∂
y
∂
x
∂
2
f
∂
y
2
]
=
[
2
2
2
6
y
]
(
5.171
)
\boldsymbol{H}=\left[\begin{array}{cc}\frac{\partial^{2} f}{\partial x^{2}} & \frac{\partial^{2} f}{\partial x \partial y} \\\frac{\partial^{2} f}{\partial y \partial x} & \frac{\partial^{2} f}{\partial y^{2}}\end{array}\right]=\left[\begin{array}{cc}2 & 2 \\2 & 6 y\end{array}\right]\qquad(5.171)
H=[∂x2∂2f∂y∂x∂2f∂x∂y∂2f∂y2∂2f]=[2226y](5.171)
使得:
H
(
1
,
2
)
=
[
2
2
2
12
]
∈
R
2
×
2
\boldsymbol{H}(1,2)=\left[\begin{array}{cc}2 & 2 \\2 & 12\end{array}\right] \in \mathbb{R}^{2 \times 2}
H(1,2)=[22212]∈R2×2
因此,泰勒级数展开式的下一项由以下给出
D
x
,
y
2
f
(
1
,
2
)
2
!
δ
2
=
1
2
δ
⊤
H
(
1
,
2
)
δ
=
1
2
[
x
−
1
y
−
2
]
[
2
2
2
12
]
[
x
−
1
y
−
2
]
=
(
x
−
1
)
2
+
2
(
x
−
1
)
(
y
−
2
)
+
6
(
y
−
2
)
2
.
\begin{aligned}\frac{D_{x, y}^{2} f(1,2)}{2 !} \boldsymbol{\delta}^{2} &=\frac{1}{2} \boldsymbol{\delta}^{\top} \boldsymbol{H}(1,2) \boldsymbol{\delta} \\&=\frac{1}{2}\left[\begin{array}{ll}x-1 & y-2\end{array}\right]\left[\begin{array}{cc}2 & 2 \\2 & 12\end{array}\right]\left[\begin{array}{l}x-1 \\y-2\end{array}\right] \\&=(x-1)^{2}+2(x-1)(y-2)+6(y-2)^{2} .\end{aligned}
2!Dx,y2f(1,2)δ2=21δ⊤H(1,2)δ=21[x−1y−2][22212][x−1y−2]=(x−1)2+2(x−1)(y−2)+6(y−2)2.
这里, D x , y 2 f ( 1 , 2 ) δ 2 D_{x, y}^{2} f(1,2) \boldsymbol{\delta}^{2} Dx,y2f(1,2)δ2只包含二次项,即二阶多项式
三阶导数如下所示:
D
x
,
y
3
f
=
[
∂
H
∂
x
∂
H
∂
y
]
∈
R
2
×
2
×
2
D_{x, y}^{3} f=\left[\begin{array}{ll}\frac{\partial H}{\partial x} & \frac{\partial H}{\partial y}\end{array}\right] \in \mathbb{R}^{2 \times 2 \times 2}
Dx,y3f=[∂x∂H∂y∂H]∈R2×2×2
D
x
,
y
3
f
[
:
,
:
,
1
]
=
∂
H
∂
x
=
[
∂
3
f
∂
x
3
∂
3
f
∂
x
2
∂
y
∂
3
f
∂
x
∂
y
∂
x
∂
3
f
∂
x
∂
y
2
]
D_{x, y}^{3} f[:,:, 1]=\frac{\partial \boldsymbol{H}}{\partial x}=\left[\begin{array}{cc}\frac{\partial^{3} f}{\partial x^{3}} & \frac{\partial^{3} f}{\partial x^{2} \partial y} \\\frac{\partial^{3} f}{\partial x \partial y \partial x} & \frac{\partial^{3} f}{\partial x \partial y^{2}}\end{array}\right]
Dx,y3f[:,:,1]=∂x∂H=[∂x3∂3f∂x∂y∂x∂3f∂x2∂y∂3f∂x∂y2∂3f]
D
x
,
y
3
f
[
:
,
:
,
2
]
=
∂
H
∂
y
=
[
∂
3
f
∂
y
∂
x
2
∂
3
f
∂
y
∂
x
∂
y
∂
3
f
∂
y
2
∂
x
∂
3
f
∂
y
3
]
D_{x, y}^{3} f[:,:, 2]=\frac{\partial \boldsymbol{H}}{\partial y}=\left[\begin{array}{cc}\frac{\partial^{3} f}{\partial y \partial x^{2}} & \frac{\partial^{3} f}{\partial y \partial x \partial y} \\\frac{\partial^{3} f}{\partial y^{2} \partial x} & \frac{\partial^{3} f}{\partial y^{3}}\end{array}\right]
Dx,y3f[:,:,2]=∂y∂H=[∂y∂x2∂3f∂y2∂x∂3f∂y∂x∂y∂3f∂y3∂3f]
由于Hessian方程(5.171)中的大多数二阶偏导数是常数,因此非零的三阶偏导数只有:
∂
3
f
∂
y
3
=
6
⟹
∂
3
f
∂
y
3
(
1
,
2
)
=
6
\frac{\partial^{3} f}{\partial y^{3}}=6 \Longrightarrow \frac{\partial^{3} f}{\partial y^{3}}(1,2)=6
∂y3∂3f=6⟹∂y3∂3f(1,2)=6
高阶导数和3阶混合导数(如
∂
f
3
∂
x
2
∂
y
\frac{\partial f^{3}}{\partial x^{2} \partial y}
∂x2∂y∂f3)都被消去,因此
D
x
,
y
3
f
[
:
,
:
,
1
]
=
[
0
0
0
0
]
,
D
x
,
y
3
f
[
:
,
:
,
2
]
=
[
0
0
0
6
]
D_{x, y}^{3} f[:,:, 1]=\left[\begin{array}{cc}0 & 0 \\0 & 0\end{array}\right], \quad D_{x, y}^{3} f[:,:, 2]=\left[\begin{array}{ll}0 & 0 \\0 & 6\end{array}\right]
Dx,y3f[:,:,1]=[0000],Dx,y3f[:,:,2]=[0006]
则有:
D
x
,
y
3
f
(
1
,
2
)
3
!
δ
3
=
(
y
−
2
)
3
\frac{D_{x, y}^{3} f(1,2)}{3 !} \boldsymbol{\delta}^{3}=(y-2)^{3}
3!Dx,y3f(1,2)δ3=(y−2)3
它收集了泰勒级数的所有三次项。总的来说,
f
f
f在
(
x
0
,
y
0
)
=
(
1
,
2
)
\left(x_{0}, y_{0}\right)=(1,2)
(x0,y0)=(1,2)处的(精确)泰勒级数展开式是
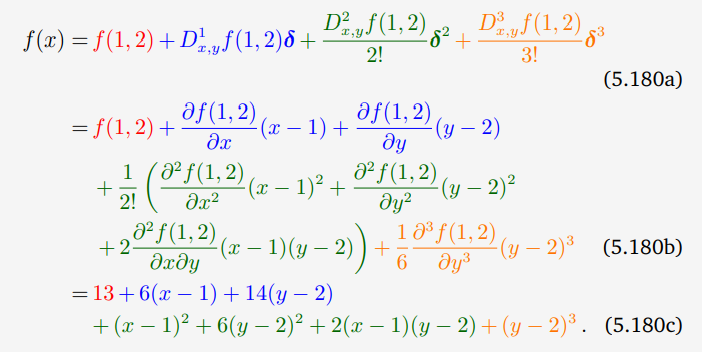
在这种情况下,我们得到了(5.161)中多项式的精确泰勒级数展开式,即(5.180c)中的多项式与(5.161)中的原多项式相同。在这个特殊的例子中,这个结果并不让人惊讶,因为原始函数仅仅是一个三阶多项式,我们在(5.180c)中通过常数项、一阶、二阶和三阶多项式的线性组合即可表示它。
翻译自:
《MATHEMATICS FOR MACHINE LEARNING》作者是 Marc Peter Deisenroth,A Aldo Faisal 和 Cheng Soon Ong
公众号后台回复【m4ml】即可获取这本书。


















 1391
1391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











