







SegEarth-OV: Towards Training-Free Open-Vocabulary Segmentation for Remote Sensing Images
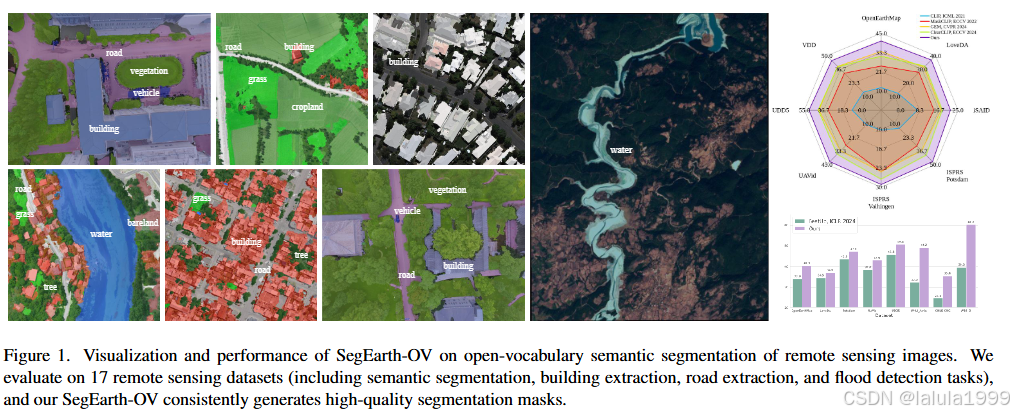
摘要
遥感图像在农业、水资源、军事和救灾等领域发挥着不可替代的作用。像素级解释是遥感图像应用的一个关键方面;然而,一个普遍的局限性仍然是需要大量手动标注。为此,我们尝试将开放词汇语义分割(OVSS)引入遥感领域。然而,由于遥感图像对低分辨率特征的敏感性,预测掩码中会出现目标形状扭曲和边界不匹配的问题。为了解决这个问题,我们提出了一种简单且通用的上采样器 SimFeatUp,以无训练的方式恢复深度特征中丢失的空间信息。此外,基于对 CLIP 中局部patch token对 [CLS] token的异常响应的观察,我们提出通过简单的减法操作来减轻patch token中的全局偏差。我们在 17 个遥感数据集上进行了广泛的实验,涵盖了语义分割、建筑物提取、道路检测和洪水检测任务。我们的方法在 4 个任务上比现有最先进方法平均提高了 5.8%、8.2%、4.0% 和 15.3%。所有代码均已开源。
引言
遥感图像改变了人类观察和理解地球的方式。它使我们能够监测土地覆盖/利用类型,有效应对自然灾害(如火灾、地震、洪水),深入了解食物和水资源等。在联合国发布的 17 个可持续发展目标(SDGs)中,遥感图像可以为“零饥饿”、“清洁水和卫生设施”、“工业、创新和基础设施”、“气候行动”、“陆地生命”等多个目标提供重要的数据支持[61]。值得注意的是,遥感数据可以被视为机器学习中的一种独特模态。它涉及更多样化的空间分辨率(从厘米到千米)、时间维度(从小时到几十年)以及物体视角(俯视和定向),因此为其他数据模态(如自然图像)设计的解决方案可能对遥感数据并不理想[53]。

近年来,原始遥感图像可以从各种来源(如 QuickBird、WorldView、Landsat、Sentinel)获取,但由于昂贵的手动成本,获取大规模标注仍然是一个挑战。此外,在地球广阔的表面,“物体”(如草地、农田、道路、森林等)占据了比“事物”(如建筑物、船只、飞机等)更多的面积[76]。因此,对于遥感图像,像素级感知(即分割)比实例级感知应用得更频繁,而像素级标注的需求加剧了获取大规模标注的难度。OpenStreetMap [19] 是一个流行的解决方案,旨在创建一个可自由使用、编辑和共享的世界地图。然而,OpenStreetMap 中标注的完整性受到地区收入水平的影响,这导致数据可用性有限[20]。视觉语言模型(VLM)的兴起为我们带来了新的灵感,其开放词汇语义分割(OVSS)的能力令人瞩目。然而,通过一些探索性实验,我们发现为自然图像设计的解决方案在遥感图像上表现不佳。一个显著的现象是预测掩码中出现目标形状扭曲和边界不匹配的问题,如图 2 所示。
根据经验,我们认为这些问题主要归因于特征分辨率过低[17, 78]:在当前基于 CLIP 的 OVSS 范式中,CLIP [51] 的特征图被下采样到原始图像的 1/16(ViT-B/16)。因此,在本文中,我们提出了一种简单且通用的特征上采样器 SimFeatUp,它通过在少量未标注图像上训练以重建内容不变的高分辨率(HR)特征,并且可以在训练后对任意遥感图像特征进行上采样。得益于 SimFeatUp 的这一特性,它可以作为无训练 OVSS 框架的通用外部单元。此外,CLIP 在图像级别进行训练,它使用 [CLS] token作为整个图像的表示,并将全局属性附加到局部token上[48, 52, 63]。然而,这种全局属性在 OVSS 中对局部特征的patch 推理产生了偏差。我们发现,通过对局部patch 特征和全局特征进行简单的减法操作,可以有效减少全局偏差。广泛的定量和定性实验证明了我们的方法在分割质量上优于先前的工作。
贡献:
- 我们提出了 SimFeatUp,一种用于无训练 OVSS 的通用特征上采样器,能够稳健地上采样低分辨率(LR)特征并保持与图像内容的语义一致性。
- 我们提出了一种极其简单直接的方法来缓解 CLIP 的全局偏差问题,即对局部和全局token进行减法操作。
- 我们最终提出的模型 SegEarth-OV 在 17 个遥感数据集上实现了最先进的性能,涵盖了语义分割、建筑物提取、道路提取和洪水检测任务。
相关工作
视觉语言模型。 最近,基础模型,尤其是视觉语言模型,为计算机视觉领域注入了新的活力。一个显著进展是对比语言-视觉预训练,即 CLIP [51],它优雅地弥合了图像和自然语言之间的差距。通过在多模态嵌入空间中训练大量数据,CLIP 获得了强大的迁移能力,实现了零样本学习的飞跃,并使 OV 学习成为可能[68]。随后,相关研究逐渐涌现,从数据[10, 58, 72, 75]、训练[14, 33, 75]或模型[31, 32]方面展开。然而,CLIP 仅关注全局 [CLS] token,尽管可以生成patch token,但它们不可避免地受到全局偏差的污染[48, 52, 63],这对密集预测不利。此外,一些遥感 VLM 出现,它们将通用 VLM 适应于遥感场景[36, 49, 66, 77]或挖掘遥感数据的特性[21, 50]。
监督语义分割。 语义分割旨在在像素级别区分图像。预测头(即解码器)作为分割模型的重要组成部分,能够将 LR 特征图上采样为 HR 预测。典型的预测头包含上采样操作(如双线性插值、JBU [27])和 HR 编码器特征(作为指导),例如 UNet [55]、UperNet [71]、Semantic FPN [25]、MaskFormer [9] 等。一些工作[37, 40, 80]专注于动态、可学习的上采样操作,使这一过程具有内容感知能力。FeatUp [15] 构建了一个模型无关的上采样方案,使用多视图一致性损失,类似于 NeRFs [45]。然而,它仅探索了带有标签的情况。 受 FeatUp 启发并在其基础上构建,本文提出的 SimFeatUp 能够在没有任何标签的情况下显著改善 OVSS。
开放词汇语义分割。 开放词汇语义分割旨在准确划分跨无限制类别集的语义区域。当前的方法主要利用 CLIP [22] 等基础视觉-语言模型,利用文本类别名称与图像特征之间的相似性来识别相应的语义区域。例如,Liang 等人[23]使用配对的掩码图像区域和文本描述对 CLIP 进行微调,从而能够高效分类这些掩码区域。CLIPseg [37] 遵循提示学习方法,直接使用文本描述作为提示来分割查询图像。基于这种适配器方法,SAN [38] 引入了一个侧适配器网络,生成掩码提议和注意力偏差,指导 CLIP 的深层进行提议级分类。同样,SegCLIP [39] 将超像素概念引入 OVSS,围绕可学习中心聚合图像块,基于预训练的 CLIP 特征形成语义区域。扩展这种块聚合方法,Chen 等人[40] 通过总结目标图像的局部区域并使用 CLIP 模型蒸馏视觉概念来执行 OVSS。专注于视觉内容与无界文本之间的语义对齐,SCAN [41] 结合了广义语义先验和上下文转移策略,以提高分割性能。相比之下,SED [42] 通过利用基于 CNN 的 CLIP 构建高效的 OVSS 网络,解决了常被忽视的局部空间信息。更直接地,CAT-Seg [43] 探索了图像和文本嵌入之间建立的多模态性质,通过成本体积计算执行分割。然而,所有这些方法都是基于自然图像构建的,未能解决遥感图像的独特特性。为了应对这一挑战并从这些独特特性中汲取灵感,我们提出了第一个专门为遥感图像设计的开放词汇语义分割框架。
预备知识
CLIP
在基于 ViT 的 CLIP 中,图像编码器由一系列 Transformer 块组成。设 X = [ x c l s , x 1 , . . . , x h × w ] ⊤ ∈ R ( h w + 1 , d ) X = [x_{cls}, x_{1},..., x_{h×w}]^{\top} \in \mathbb{R}^{(hw + 1,d)} X=[xcls,x1,...,xh×w]⊤∈R(hw+1,d)表示最后一个块的输入,其中 h h h和 w w w表示特征图的高度和宽度, d d d表示tokens维度, x c l s x_{cls} xcls是一个可学习的全局tokens,其他的是来自不同图像块的局部tokens。这个块的前向传播过程可以表述为:
q = E m b q ( X ) , k = E m b k ( X ) , v = E m b v ( X ) , y = X + S A ( q , k , v ) , z = y + F F N ( L N ( y ) ) \begin{gathered}q = Emb_{q}(X), k = Emb_{k}(X), v = Emb_{v}(X), \\y = X + SA(q,k,v), \\z = y + FFN(LN(y))\end{gathered} q=Embq(X),k=Embk(X),v=Embv(X),y=X+SA(q,k,v),z=y+FFN(LN(y))
其中 q q q、 k k k、 v v v分别表示查询(Query)、键(Key)和值(Value)。 E m b Emb Emb由一个层归一化(LN)层和一个线性层组成, F F N FFN FFN表示前馈神经网络。 S A SA SA表示一个标准的自注意力模块,即 S A ( q , k , v ) = softmax ( q ⋅ k ⊤ d ) ⋅ v SA(q,k,v)=\text{softmax}(\frac{q\cdot k^{\top}}{\sqrt{d}})\cdot v SA(q,k,v)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1839
1839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









