







文章目录
相关资料
代码:https://github.com/ZiqinZhou66/ZegCLIP
论文:ZegCLIP: Towards Adapting CLIP for Zero-shot Semantic Segmentation
摘要
最近,CLIP 通过两阶段方案被应用于像素级zero-shot学习任务。其总体思路是首先生成与类别无关的区域建议,然后将裁剪过的建议区域输入 CLIP,以利用其图像级零镜头分类能力。这种方案虽然有效,但需要两个图像编码器,一个用于生成建议,另一个用于 CLIP,从而导致复杂的流水线和高昂的计算成本。
在这项工作中,我们追求一种更简单高效的单阶段解决方案,直接将 CLIP 的zero-shot预测能力从图像级扩展到像素级。我们的研究以直接扩展为基线,通过比较文本和从 CLIP 提取的补丁嵌入之间的相似性来生成语义掩码。然而,这种范例可能会严重过度拟合已见类别,无法推广到未见类别。为了解决这个问题,我们提出了三种简单而有效的设计,并发现它们可以显著保留 CLIP 固有的零点能力,并提高像素级的泛化能力。通过这些修改,我们开发出了一种高效的零镜头语义分割系统,称为 ZegCLIP。
通过在三个公共基准上进行广泛的实验,ZegCLIP 展示了卓越的性能,在 "inductive"和 "transductive "零镜头设置下都远远优于最先进的方法。此外,与两阶段方法相比,我们的单阶段 ZegCLIP 在推理过程中的速度提高了约 5 倍。
- 归纳(Inductive)设置:
在归纳设置中,零样本学习模型的目标是识别在训练阶段从未见过的类别。未见的类名和图像在训练期间都不可访问。- 传导(Transductive)设置:
传导设置在零样本学习的上下文中不如归纳设置常见,但它涉及到使用一些关于未知类别的辅助信息来提高模型的性能。它假设在测试阶段之前未知类的名称是已知的。
引言
zero-shot语义分割定义
zero-shot语义分割尤其具有挑战性和吸引力,因为它需要根据给定类别的语义描述直接生成语义分割结果。
zero-shot前人工作
CLIP 最初是为匹配文本和图像而构建的,它在图像级零镜头分类方面表现出了卓越的能力。不过,zsseg 和 Zegformer采用的是常见的策略,即需要两阶段处理,首先生成区域建议,然后将裁剪后的区域输入 CLIP 进行零镜头分类。这种策略需要两个图像编码过程,一个用于生成建议,另一个用于通过 CLIP 对每个建议进行编码。这种设计产生了额外的计算开销,并且不能在提案生成阶段利用CLIP编码器的知识。此外,MaskCLIP+利用CLIP生成新类的伪标签进行自我训练,但如果推理中未见的类名在训练阶段未知(“inductive”零射设置),则无效。
本文工作
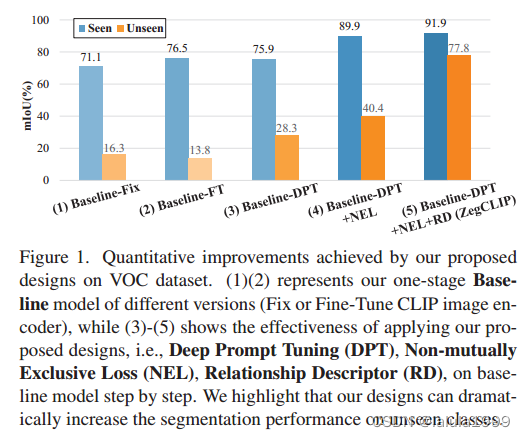
我们使用轻量级解码器将文本提示与从 CLIP 中提取的局部嵌入相匹配,这可以通过基于transformer结构的自注意机制来实现。我们在一个包含来自有限类别的像素级注释的数据集上训练Transformer解码器,并固定或微调 CLIP 图像编码器,期望文本补丁匹配能力能推广到未见过的类别。遗憾的是,这种基本版本往往会过度拟合训练集:虽然对已见类别的分割结果普遍有所改善,但模型却无法对未见类别进行合理分割。以下是改进的3种设计:
- 设计 1:使用深度提示微调(Deep Prompt Tuning, DPT)代替固定或微调 CLIP 图像编码器。我们发现,微调可能会导致对所见类别的过度拟合,而提示调整则更倾向于保留 CLIP 固有的zero-shot能力。
- 设计 2:在进行像素级分类时应用非互斥损失(Non-mutually Exclusive Loss, NEL)函数,但生成一个类别的后验概率与其他类别的对数无关。
- 设计 3:最重要的也是我们的主要创新–在匹配 CLIP 文本片段嵌入之前,引入关系描述符 (RD) 将图像级先验纳入文本嵌入,可显著防止模型过度拟合所见类别。

方法
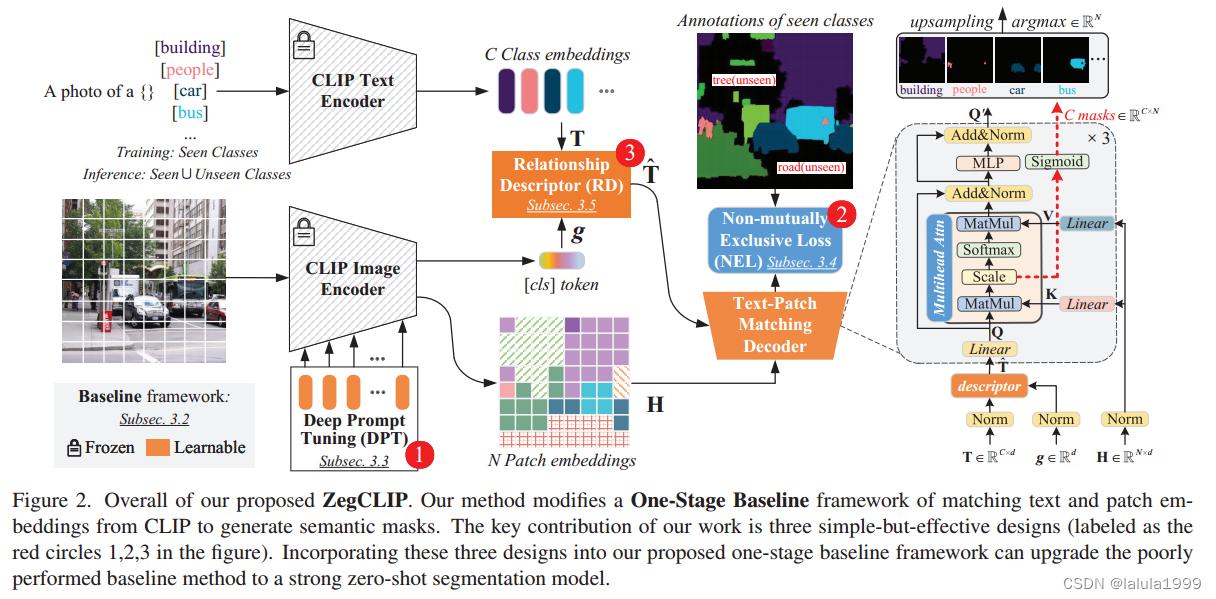
问题定义
我们提出的方法遵循广义零次语义分割(generalized zero-shot semantic segmentation, GZLSS),该方法只需要在具有可见部分像素注释的数据集上进行训练,即可分割可见类和未见类。在训练阶段,模型根据所有看到的类的语义描述生成逐像素分类结果。在测试阶段,期望该模型为已知类和新类产生分割结果。零采样分割的关键问题是,在进行推理时,仅仅对已知类别进行训练不可避免地会导致对已知类别的过度偏差。
基线:单阶段文本补丁匹配
最近的研究表明,文本嵌入可以隐式地匹配补丁级图像嵌入,受此启发,我们通过添加一个普通的轻量级Transformer作为解码器来构建一个单阶段基线。然后,我们将语义分割描述为具有代表性的类查询与图像补丁特征之间的匹配问题。
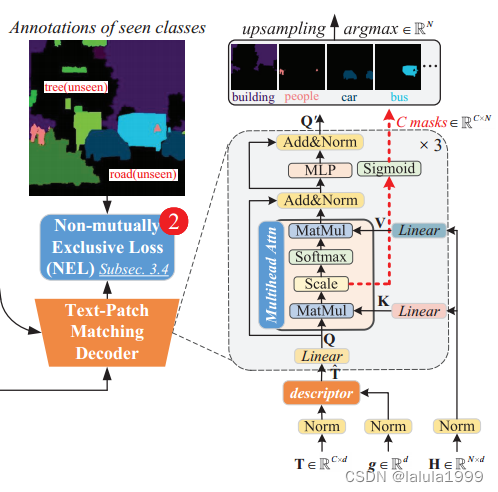
在形式上,我们将 C C C类嵌入表示为 T = [ t 1 , t 2 , . . . , t C ] ∈ R C × d T=[t^1,t^2,...,t^C]\in \mathbb{R}^{C\times d} T=[t1,t2,...,tC]∈RC×d,其中 d d d为CLIP模型的特征维数, t i t^i ti表示第i个类
图像的N个patch令牌为 H = [ h 1 , h 2 , . . . , h C ] ∈ R C × d H=[h_1,h_2,...,h_C]\in \mathbb{R}^{C\times d} H=[h1,h2,...,hC]∈RC×d, h j h_j
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5382
5382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









