







一、什么是Adaboost
AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,由Yoav Freund和Robert Schapire在1995年提出。它的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的
最大迭代次数。
具体说来,整个Adaboost 迭代算法就3步:
1、初始化训练数据的权值分布。
如果有 N N N个样本,则每一个训练样本最开始时都被赋予相同的权值: 1 N \displaystyle \frac{1}{N} N1。
2、训练弱分类器。
具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
3、将各个训练得到的弱分类器组合成强分类器。
各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
二、图解Adaboost
1、训练弱分类器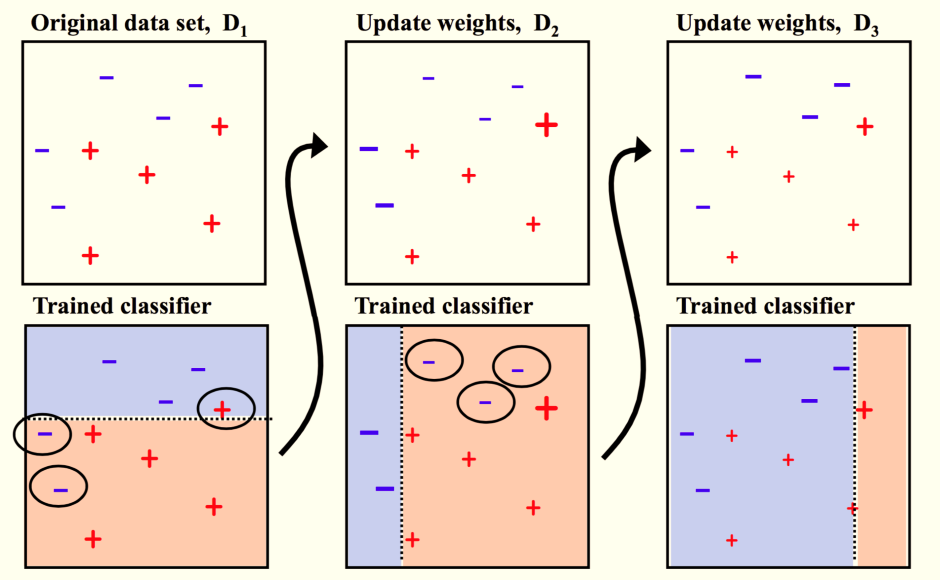
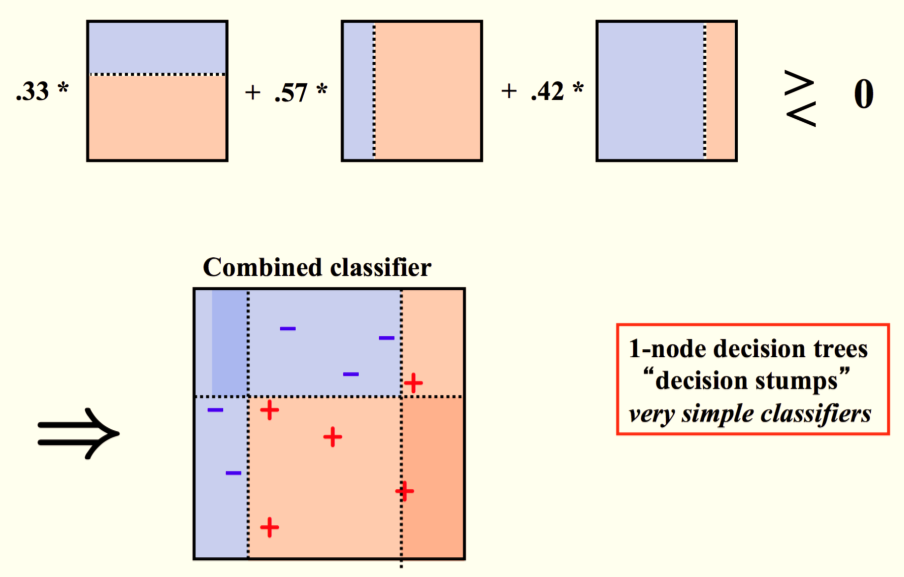
2、将弱分类器组合成强分类器
三、Adaboost算法说明
1、初始化训练数据的权值分布:
D 1 = ( w 1 1 , . . . w 1 i , . . . w 1 N ) D_1=(w_11,...w1i,...w1N) D1=(w11,...w1i,...w1N)
初始权重分布:
w
1
i
=
1
N
,
i
=
1
,
2...
N
\displaystyle w_{1i} =\frac{1}{N},i=1,2...N
w1i=N1,i=1,2...N
假设训练集数据具有均匀的权值分布,即每个训练样本在及分类器的学习中作用相同。这一假设保证第一个基分类器由原始数据学习的到。
2、调整训练数据的权值分布
对 m = 1 , 2... M m=1,2...M m=1,2...M,使用具有不同权重分布 D m D_m Dm的训练数据集学习,得到若干个基分类器。
- 使用当前的权值分布D_m的调整训练集权重,进行基分类器 G m ( x ) G_m(x) Gm(x)的学习。
- 计算基分类器
G
m
(
x
)
G_m(x)
Gm(x)在甲醛训练数据集上的分类误差率:
e m = ∑ i = 1 N P ( G m ( x i ) ≠ y i ) = ∑ G m ( x i ≠ y i ) w m i \displaystyle e_{m} =\sum ^{N}_{i=1} P( G_{m}( x_{i}) \neq y_{i}) =\sum _{G_{m}( x_{i} \neq y_{i})} w_{mi} em=i=1∑NP(Gm(xi)=yi)=Gm(xi=yi)∑wmi
w m i w_{mi} wmi表示第m轮中第 i i i个实例的权值, ∑ i = 1 N w m i \displaystyle \sum ^{N}_{i=1} w_{mi} i=1∑Nwmi=1,是每个样本的权重分配。 G m ) \displaystyle G_{m}) Gm)在加权的训练集上的分类错误率是被 G m \displaystyle G_{m} Gm误分类样本的权值之和。由此可以看出数据权重分布 D m D_{m} Dm与基分类器 G m \displaystyle G_{m} Gm的分类误差率的关系。 - 计算基本分类器
G
m
\displaystyle G_{m}
Gm的系数
α
i
\displaystyle \alpha _{i}
αi。
α
m
\displaystyle \alpha _{m}
αm表示
G
m
\displaystyle G_{m}
Gm在最终分类器中的重要性。当
e
m
⩽
1
2
\displaystyle e_{m} \leqslant \frac{1}{2}
em⩽21时,
α
m
⩾
0
\displaystyle \alpha _{m} \geqslant 0
αm⩾0,并且
α
m
\displaystyle \alpha _{m}
αm随着
e
m
e_m
em的减小二增大,所以分类误差率越小的基分雷奇在最终的分类器中最用越大。
α m = 1 2 l o g 1 − e m e m \displaystyle \alpha _{m} =\frac{1}{2} log\frac{1-e_{m}}{e_{m}} αm=21logem1−em - 更新训练集的权重分布为下一轮作准备。
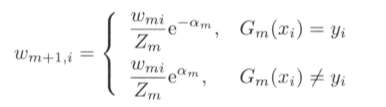
由此可知,被基分类器 G m \displaystyle G_{m} Gm误分类样本的权值得以扩大,而被正确分类样本的权值却得以缩小。由 α m = 1 2 l o g 1 − e m e m \displaystyle \alpha _{m} =\frac{1}{2} log\frac{1-e_{m}}{e_{m}} αm=21logem1−em得知,误分类样本的权值被放大了 e 2 α m = 1 − e m e m \displaystyle e^{2\alpha _{m}} =\ \frac{1-e_{m}}{e_{m}} e2αm= em1−em倍。因此,误分类样本在下一轮学习中其更大的作用。
Adaboost特点一:不改变所给的训练数据而不断改变训练数据权值的分布,使得训练数据在基分类器中起不同的作用。
3、线性组合 f ( x ) \displaystyle f( x) f(x)实现M个基分类的加权投票。
系数 α m \displaystyle \alpha _{m} αm表示了基本分类器 G m \displaystyle G_{m} Gm的重要性。这里 α m \displaystyle \alpha _{m} αm之和并不为1。 f ( x ) \displaystyle f( x) f(x)的符号决定实例 x x x的类别, f ( x ) \displaystyle f( x) f(x)的绝对值表示分类的确信度。
Adaboost特点二:利用基分类器的线性组合构建最终分类器。
参考文献:李航《统计学习方法》















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









