







视觉信息应用技术 课程总结
一、视觉主观实验——假设提出、结论构成
- 设计实验:先假想——想证实什么问题,问题假设是否可以存在
- 有没有其他因素影响
- 因素对人具体产生什么影响
- 影响的共性
- 进行数据分析
- 分析结论是什么
- 结论带来的现实意义是什么(应用推广,实用价值),要具体
- PS:图表要描述得清晰、易懂,尽量美观。可以使用matlab等绘图。
二、视觉主观实验——常见评价方法:单、双刺激法
- 实验是与失真有关的质量评价,建议使用双刺激评价法。
- 图像、视频等不确定具体方法时,用单刺激法。
- 从时间的性价比上考虑,我们还是推荐大家使用单刺激法。
(一)单刺激法
1、MOS值
Mean opinion score——取同一个对象的所有被试的打分结果的平均值。
2、剔除异常值(两种方法)
- 根据所有人的评分结果,得到MOS(平均)值1和标准差,当某人的数值与平均值1的差值的绝对值超过2倍标准差的时候,去掉这个值,用剔除异常值后剩余数值的平均值2代替。
-
此处处理excel数据时应用到的函数有:
稍后更新- 平均值1:=AVERAGE($E 2 : 2: 2:E$31)
- 2倍标准差(标准差不是方差,是方差的开方):=STDEV.P($E 2 : 2: 2:E$31)*2
- 用0替换异常值:=IF(ABS(E2-E32)>E62, ,E2)
- 求剔除后平均值2:=SUM(Y2:Y31)/COUNT(IF(Y2:Y31=0," ",Y2:Y31))
更新
- 保证每个素材在整个评价过程中重复出现2次,当某人对同一张图像的打分结果超过2个数量级的时候,对这个素材进行一次标记,如果整个标记次数超过了这个人整个打分素材数量的15%,说明这个人不靠谱,把这个人的数据都去除。这种方式得到的数据更稳定,但是花费时间更长。
PS:实验人数少用第二种,人多用第一种
(二)改进的单刺激法(截至目前最精确的处理数据方法)
将所有素材给每个被试呈现两遍(随机顺序),并且两遍都要打分,然后通过看两遍的结果判定这个被试给出的分数是否稳定。
此处如何判断是否稳定?
答:根据打分表设计的具体情况判断。(如下)
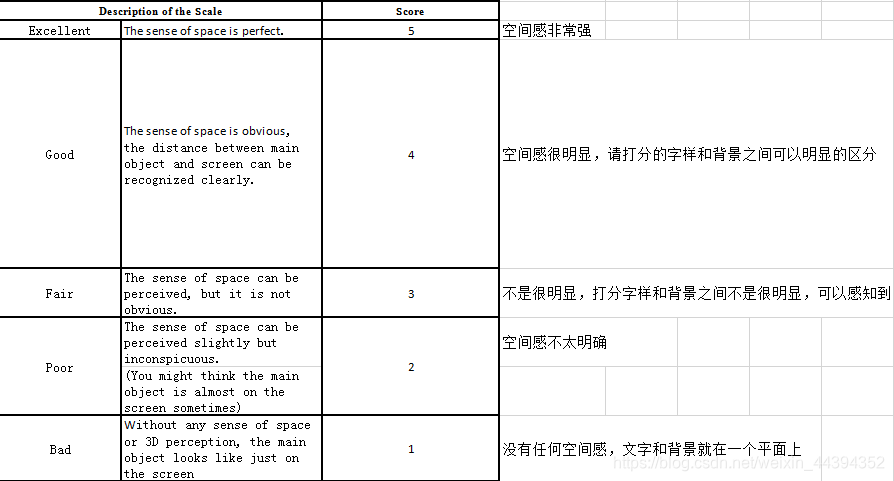
由图可知:
- 比如1分和2分,只是空间感不太明确和没有的关系,但是如果1分和3分,就是明显的有和没有的差别了。
- 也就是说,当被试看同一对象两次的时候,可能会因为每次的感知情况不同而出现给出了相邻分值的情况,例如3分和4分,2分和3分,1分和2分。
- 但是,如果你对同一张图像,第一次给出1分,第二次给出3分;或者第一次给出3分,第二次给出5分,这就说明这个被试在观察的时候,太不稳定。就要把这个被试当前的这个分值去掉,用其他人的平均值代替。
- 注意,这时只是把这个人针对当前“不稳定分值”的素材的打分去掉。
- 但是我们还要继续分析,他打分的整体情况,出现这种“不稳定”给分的数量占整个打分数量的百分比。
- 比如这个人一共评价了20组图像,其中有2组“不稳定”,被去除了,去除率是10%,那这个人的其他分值还可以保留,继续和其他人一起做平均。
- 但是,如果这个人平均了20组图像,其中出现了4组“不稳定”,被去除了,去除率超过了15%,说明这个人有点不靠谱啊,那么他的全部打分数据,都要被去除。
PS:
此方法最大的缺点是:当素材数量较多时,两遍打分会相应的消耗大量的时间。
这需要我们设计好具有一定区分度的变量,并且设计合适的量表,否则无法区分。并且观察人数不宜过少。
(三)成对比较法
除了单刺激法外,还可以用一种准确度更高,区分更明显,但是相应更复杂的,成对比较法。
- 进行成对比较时,两个刺激可以同时呈现,也可以先后呈现。如果是同时呈现需要消除空间误差,如果是先后呈现要消除时间误差。
- 消除空间误差,就是做完一遍实验之后,更换两个素材的位置顺序,然后再让被试选择。
- 消除时间误差,就是做完一遍实验后,设计和第一次相反的两个素材的呈现顺序。
- 成对比较法本来就比较复杂,有多少个样品,就要比较n(n-1)/2遍,再加上消除误差的结果,等于这个2就没除
- 虽然能“非常有效”地区分被试的判断,但是非常非常耗时间,适用于实验素材的数量不多的时候。
ITU-R 20BT.500-13 20建议书电视图像质量的主观评价方法
三、视觉主观实验——实验数据高阶处理方法
前面我们都熟悉了如何用“描述统计”的方式表示数据,并且绘制成图表进行分析。
但是我们始终无法回答一个问题,就是我们设计的这些变量,到底是不是“显著影响”被试给出的评价结果。
比如我们分析的颜色数据,我们只能从趋势图或者均值变化判断,有没有差异,立体感最高的是哪个颜色,立体感最低的是哪个颜色。但是颜色这个变量(自变量),我们如何通过数据统计分析的方法回答“它到底有没有显著影响立体感变化”这个问题?
就是我们接下来要学习的——解释显著性的两种最常见的方法,T检验和F检验。
1、T检验
t检验又分成3种情况:单总体的t检验,独立样本的t检验和配对样本的t检验。
- 单总体的t检验:
例如:以我们实验室的同学为例,我们可以先测算一下实验室里同学的男女比例,然后再跑到隔壁媒介音视频实验室去测算一下那边的男女比例。你选择的这些你认识的,可以直接测算出来的同学就是样本。而我们布置的“信通学院所有研究生的性别”就是总体。如果你已经知道了总体的结果,又知道了某次抽取的样本的结果,那么就可以根据单总体t检验,判断样本均值和总体均值相比是否显著差异。
这里的单总体 统计量计算公式t值是这样的:
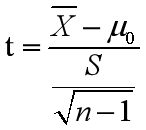
X是样本平均值,μ0是整体平均值,S是总体的标准差。
当n>30时,公式可以写成:
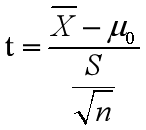
举个例子:某校二年级学生期中考试英语成绩平均分73分,标准差17分。期末考试后,随机抽取20人的英语成绩,平均分79.2分,该成绩是否有显著进步?
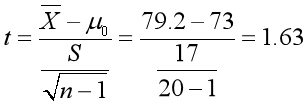
这里20-1少了根号。
计算出t值后就是假设检验的一般步骤:
- 首先:建立原假设H0:成绩没有显著进步
- 然后,我们根据样本的自由度,查表得到当前自由度下的t值:
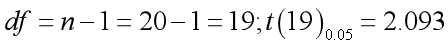
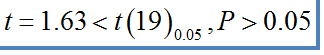
- 接下来,因为我们计算的t值小于自由度为19时的t值,证明成绩没有显著进步的概率大于0.05,因此我们接受原假设,拒绝显著性假设,20人的成绩平均值与总体平均值差异不显著。
- 关于这里面的统计学原因,我们这里只要会用就可以,不花时间去理解。
-
独立样本的t检验(常见):
用于判断两个独立的样本是否来自相同均值的总体。
应用举例:对同一次考试的结果,男生和女生的结果比较是否显著。
男生的结果和女生的结果而言,就是独立的样本。
这时的独立样本 统计量检验公式t值的计算方法为:
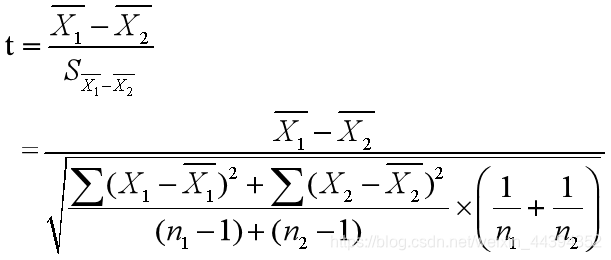
其中这个看似复杂的分母给出的是均值之差的标准误差,反应了样本平均数的离散程度。
检验时依然要根据df的值确定临界值t0.05的大小,做出统计推断。
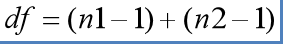
同样需要查t分布的表,然后判断t值和t0.05的大小,如果小于这个值,则接受原假设,拒绝显著性假设;如果大于这个值,证明两组样本均值差异显著。
能够实现这种检验的要求是,两个样本相互独立,且要求他们的总体分布都为正态的。 -
配对样本的t检验
用于检验两个相关的样本是否来自具有相同均值的总体。
应用举例:同一实验对象,在两个不同时间上分别接受前后两次处理。
我们开学时候学过的莫扎特实验,听音乐前和听音乐后,就属于这种情况。
配对样本的t检验计算方法:
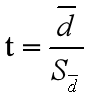
其中分子的d为: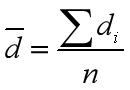
di是前后两次的处理差值:
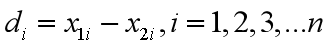
此为分母的计算方法:
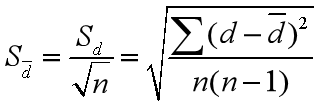
依然是均方误差,我们还是要根据自由度进行查表判断:
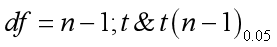
如果t值大于临界值,显著性成立,如果t值小于临界值,则两组均值不显著。
PS:
t检验是最简单的显著性检验方法,但是通过我们的分析,发现貌似仅针对的都是两组对象的比较情况。
如果我们要增加因素,那么t检验就没法直接使用了。
这时候我们就要用到另一种检验形式,F检验。
2、F检验
- F检验又叫:方差分析,是检验不同组或不同条件下分数的差异是否显著的方法。
- t检验和f检验中,我们要求大家都能掌握方差分析的一般处理方法,方差分析的基本逻辑如下:

关于组间和组内的概念,理解如下: - 组间:对于单因素来说,如果你设计了1个变量,这个变量有5个水平,那么组间就是这5个水平之间的差异。(k个水平)
比如你想研究5个年龄段的人对某种东西的喜好情况,这个喜好的结果就是因变量,而年龄是自变量,5个年龄段就是自变量的5个水平,也就是方差分析的时候要分析的“组间”。 - 组内:某个水平测试了 n次
其中F值的基本求解方法如下:

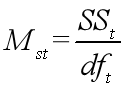
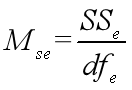

SSt和SSe是我们根据组内(处理内)和组间(处理间)的情况求得的方差。
举个例子:针对有n个样本,K个处理(简单起见,可看做1个因素,这个因素有k个水平的情况,而nk为总体的测试处理个数,即k个处理中,每个都接受了n个样本的测试,共有nk个观察值),我们的计算方法如下:
首先列举数列:
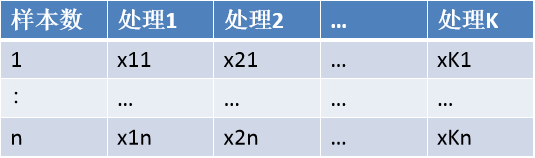
接下来,我们先求解各处理的平均值和所有样本的平均值:(PS:处理平均值 公式 求和之后少了一个平均,要除一个n)
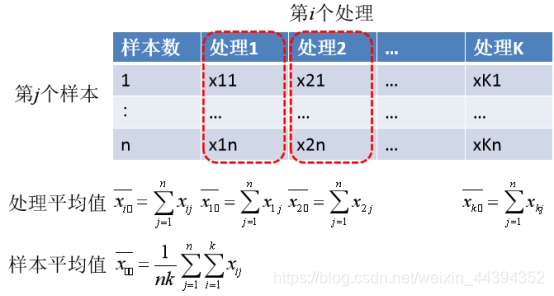
在这个基础上,我们就可以求解处理间和处理内的方差了:(每个处理都有n个被试进行操作,所以计算完单一处理的平均值以后,先乘以n,再进行所有处理间的累加)
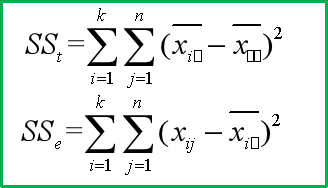
dft和dfe是处理间与处理内的自由度,只要记住公式即可。
PS:
如果大家比较纠结自由度的问题的话,有一种比较容易理解的解释方法:
1)在计算处理间平方和的时候,每个处理的平均值会受到处理的总平均值的约束,所以dft=k-1,就是说每个处理都会受到这个平均值的约束:
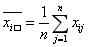
2)而对于处理内的每个值,因为一共有n×K个观察值,而每个处理又有一个均值,共有K个处理就有K个处理间均值,所以处理内的数值的自由度dfe=n×k-k=k×(n-1)
针对dfe的另一种解释是,因为总体的自由度是n×k-1,这个1是受到总体平均值的影响,而已知处理间的自由度是k-1,所以处理内的自由度就是总体自由度-处理间自由度,也就是我们之前给大家展示过的公式:
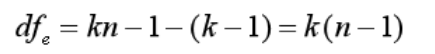
判断是否显著的重点来了:
和t值的判断方法类似,到底显著不显著,我们要比较给定置信度区间内的F值和我们计算出的F值的大小。
如果我们计算的F值大于这个查表得到的值,那就显著。
如果我们计算的F值小于这个查表的值,那就不显著。
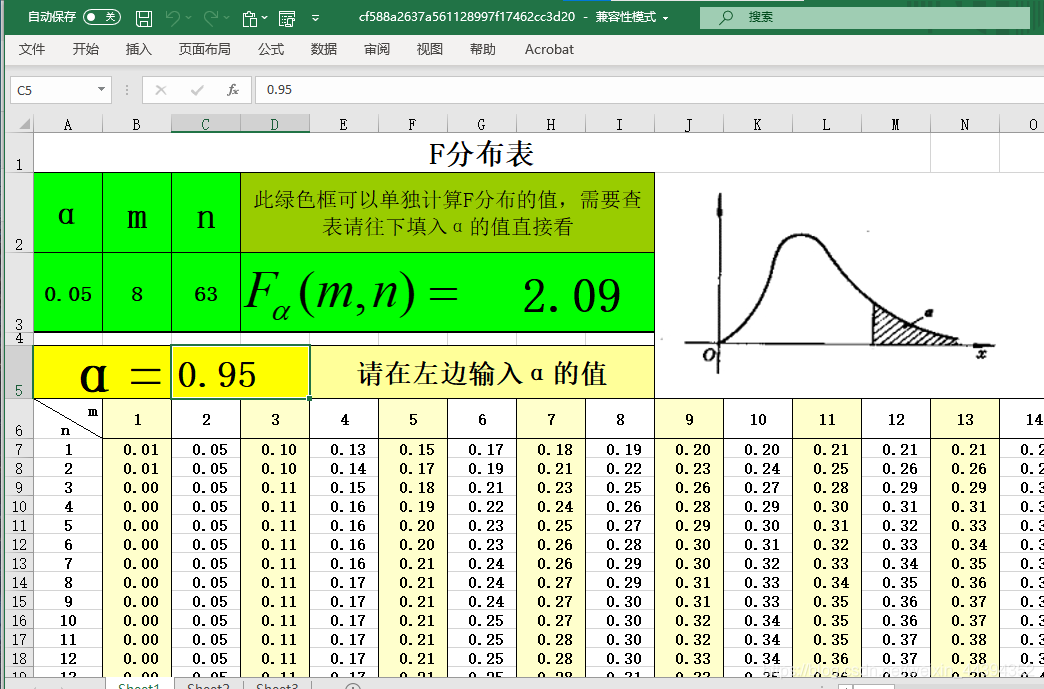
底下的部分是具体的数值,如果你不是想重温一下概率论与数理统计的话可以不理会。
下面这部分中,第一个α值,对应着我们假设检验的概率:
m=k-1 表示处理间的自由度,n=nk-k(不是同一个n) 表示处理内的自由度。
如果我们是准备验证p是否小于0.05(比较显著),那就在α的位置填0.05;
如果我们是准备验证p是否小于0.01(更加显著的取值),那就在α的位置填0.01:

这些都填好之后,后面那个大格子会直接给出F值的查表结果。
举例说明:
方差分析举例说明.
3、SPSS的操作流程及注意事项
有空更新

- 被试内设计:每个被试接受所有的实验
- 被试间设计:不同的被试接受不同的实验
四、3D图像和视频
- 由于调节(聚焦)和会聚不在同一个平面上,导致人眼在频繁切换的过程中会非常疲累——调节(聚焦)在屏幕上,但是会聚却在屏幕前面(出屏)或后面(入屏)。
- 正负视差:
正视差(+):入屏(屏幕后)
负视差 (-):出屏(屏幕前) - 立体效果比较糟糕的失真情况有三种:
- 纸板效应(摄像机间距过小):对象不立体,没有厚度
- 小人国效应(摄像机间距过大):画面中对象显得很小,比例出现问题。
- 窗口效应(出屏,产生负视差了):通过构图可以解决














 235
235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









