







问题描述
在centerformer(基于det3d)项目中,我增加了一个和图像的融合处理(paint features),在训练过程中经常到第13/14个epoch打印的日志中出现NAN的现象。
问题分析
根据现象,猜测可能的原因是:
1.数据集中有脏数据 -> 可以通过训练baseline或现有模型resume早期epoch,看能否通过一整个epoch来判定
2.forward过程中已经存在NAN -> 可以通过在backbone和neck处打印torch.isnan(tensor)来判定forward过程中是否有NAN
3.计算的loss中存在NAN -> 可以通过在loss处打印torch.isnan(tensor)来判定
4.计算grad并BP的过程中存在一些特殊点导数值很大趋于∞,导致梯度出现NAN -> 在loss.backward()中添加上下文管理器with autograd.detect_anomaly():监测梯度是否有异常
解决思路
1.首先加入自动梯度异常检测
with autograd.detect_anomaly():
runner.outputs["loss"].backward()
结果打印的info表明确实存在,并且在MulBackward0里面
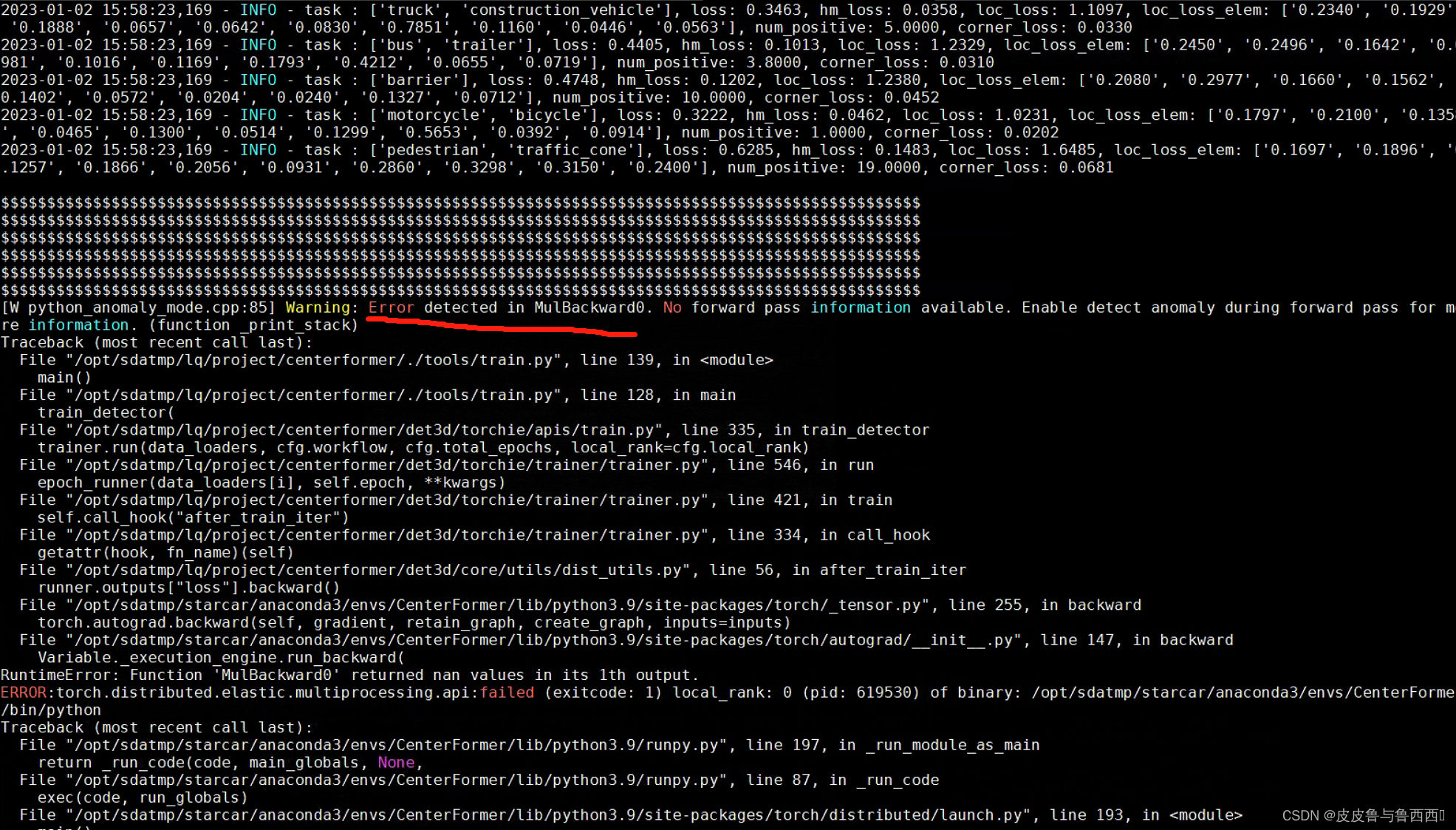
为了进一步定位NAN,把所有有异常的梯度都打印出来:
for name, param in runner.model.named_parameters():
if param.grad is not None and torch.isnan(param.grad).any():
print("nan gradient found")
print("name:", name)
结果发现从backbone开始到neck以及最后的box_head都是NAN的
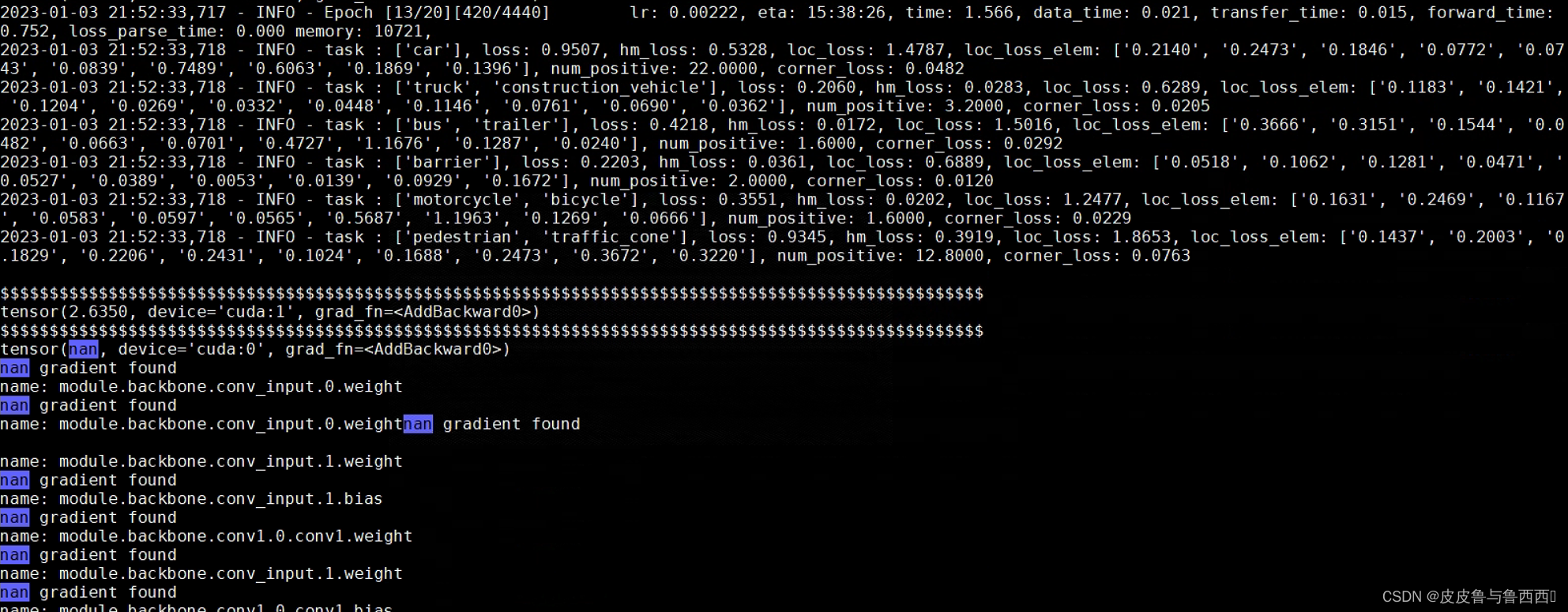
在backbone和neck处打印torch.isnan(tensor)发现NAN是在grad为NAN之后出现的,说明在forward阶段所有tensor都是正常的。于是NAN范围聚集到了loss上。因为默认打印的info是每5个iteration并且是多个gpu的均值,不方便排查,于是在代码中增加print(loss)。
结果发现NAN确实存在loss中,并且是在heatmap的loss里。
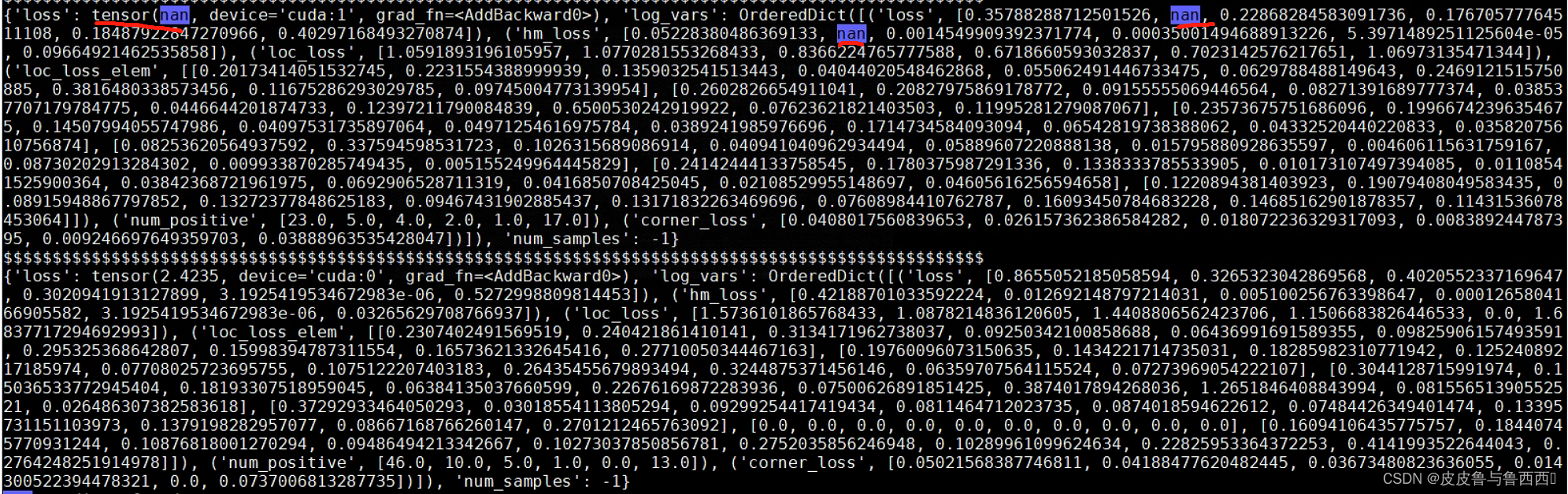
于是聚焦到heatmap loss的计算中,代码如下:
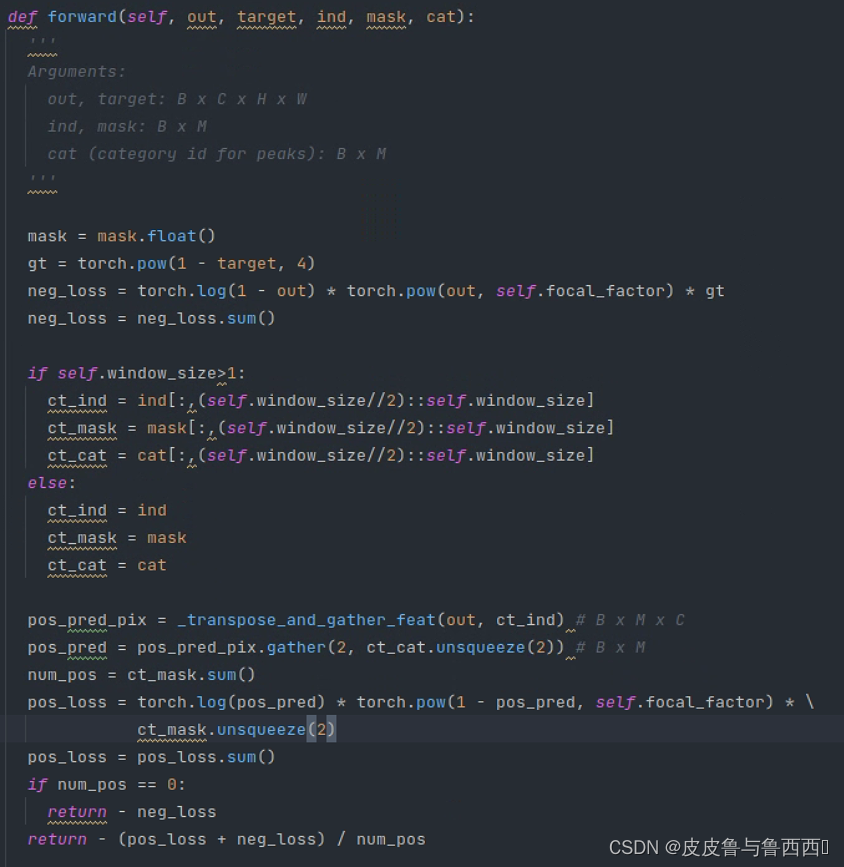
通过debug进入到里面,发现neg_loss和pos_loss中都存在torch.log(x),这是个比较危险的函数,当x->0时,就会出现NAN。debug时发现确实存在输出为0和1的现象(网络预测得比较好,这也是为什么在第14个epoch才会出现NAN而早期不会出现的原因),于是增加了对out的值域限制。
eps=1e-5 //注意eps=1e-8太小了,1-eps还是会上溢到1
out = torch.clamp(out, eps, 1.0-eps)
——————————————————————————————————————————————————————
【详细总结】Pytorch训练模型损失Loss为Nan或者无穷大(INF)原因
torch.clamp()
【问题记录】PyTorch NaN RuntimeError: Function ‘MulBackward0‘ returned nan values in its 0th output. 深度学习
Function ‘MseLossBackward0‘ returned nan values in its 0th output.
Pytorch计算Loss值为Nan的一种情况,如何检测NAN?















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









