







论文来源:arxiv.org
本文作者:李炎,硕士研究生,目前研究方向为深度学习、计算机视觉。
摘要
不同于之前的人工设置的定长的位置编码(Position Encoding)或可学习位置编码,本文设计了一种条件位置编码 CPE(conditional positional encoding),CPE 是动态生成的,并以输入 token 的局部邻域为条件( conditioned on the local neighborhood of the input tokens),CPE 可以更好的处理比模型在训练期间见过的更长的输入序列;同时 CPE 可以在不同任务中保持网络模型的平移不变性。同时本文设计了一种 位置编码生成器 PEG (Position Encoding Generator) 用于生成 CPE ,该位置编码生成器很简单,并很容易应用在其他视觉变压器(Vision Transformer)中。
问题描述
之前的视觉转换器( Vision Transformer )中的位置编码( Position Encoding )大多采用人为设定的固定长度的 Position Encoding 或者可学习的 Position Encoding ,但是上述两种位置编码方法在网络模型训练中与其他网络参数一同训练,训练过后位置编码的长度已经固定,当输入 Vision Transformer 的序列长度变化较大的时候,表现出来的泛化能力较弱,为了更好的处理更长的输入序列并在各种视觉任务中保持网络结构的平移不变性。
本文核心工作
- 设计了一种性能更好的条件位置编码 CPE 。
- 设计了一种位置编码生成器 PEG 用于生成 CPE。
模型
本文认为视觉任务的成功位置编码应满足以下要求:
(1) 使输入序列排列可变但平移不变。
(2) 具有归纳性,能够处理比训练期间更长的序列。
(3)具有提供一定程度绝对位置的能力。如 [13] 所示,这对性能很重要。
~
本文认为通过位置编码来表征局部关系足以满足上述所有条件。
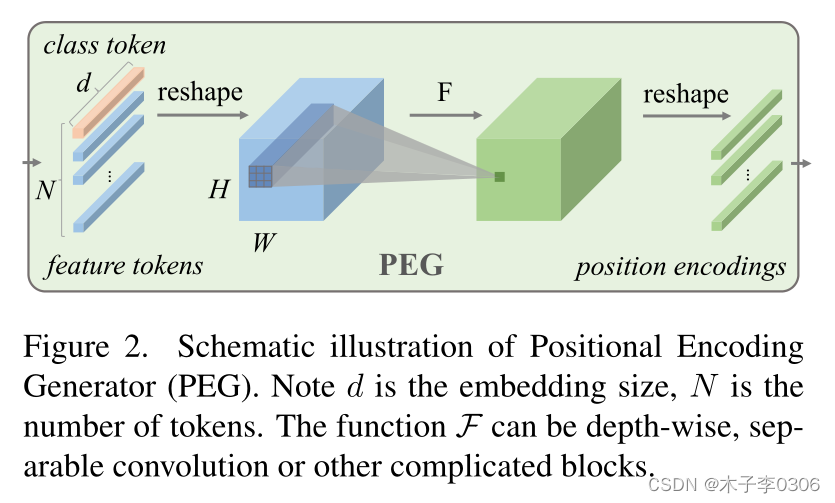
-
首先 PEG 对输入维度为 B ∗ N ∗ C B*N*C B∗N∗C 的 Tokens 序列进行reshape操作,将其还原为2D的shape: B ∗ H ∗ W ∗ C B* H* W* C B∗H∗W∗C 。
-
然后来将一个 F 函数重复应用于的局部块(local patch)上,用于产生Conditional Positional Encoding 。
B:每批的图片数 N:Token数,即将图片分成的块(Patch)数; $N=(H*W)/d$ d:每个 Patch 的尺寸为 d*d C:图片的通道数 H、W:分别为原图的高、宽
PEG 通过一个 F 函数来高效实现。需要注意的是 卷积( F 函数)一定要使用zero paddings,以获取绝对位置信息。zero paddings[1]是图中 F 函数获取绝对位置信息的关键。 F 函数由内核为 k ( k ≥ 3 ) k (k ≥ 3) k(k≥3) 和 ( k − 1 ) / 2 (k−1)/ 2 (k−1)/2 零填充的二维卷积有效地实现。其中 F 可以是各种形式,例如可分离卷积和许多其他形式。
这里的零填充[1]非常重要!!通过零填充可以获取 patch 的绝对位置。
为什么使用二维卷积就变成了条件位置编码呢?
因为,卷积核尺寸越大(例如 3*3),则包含的周边信息越多,可以理解为,将原图像的顺序排列的特征具有了空间信息,因此信息包含更多,则能很好的提高准确率,是本文的关键理解
PEG实现代码:
class PosCNN(nn.Module):
def __init__(self, in_chans, embed_dim=768, s=1):
super(PosCNN, self).__init__()
self.proj = nn.Sequential(nn.Conv2d(in_chans, embed_dim, 3, s, 1, bias=True, groups=embed_dim))
self.s = s
def forward(self, x, H, W):
B, N, C = x.shape
feat_token = x
cnn_feat = feat_token.transpose(1, 2).view(B, C, H, W) # reshape
if self.s == 1:
x = self.proj(cnn_feat) + cnn_feat # CNN聚合局部关系并配合残差连接
else:
x = self.proj(cnn_feat)
x = x.flatten(2).transpose(1, 2)
return x
def no_weight_decay(self):
return ['proj.%d.weight' % i for i in range(4)]
实验
数据集
使用具有 1K 类和 1.3M 图像的 ILSVRC-2012 ImageNet 数据集。
实验设计及结果
-
与其他SOTA方法进行对比:
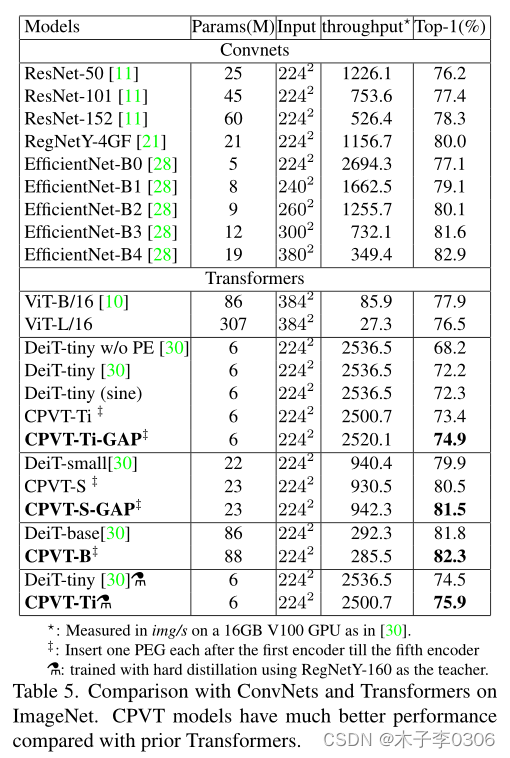
与之前的 Transformer 相比,加入了位置编码的 CPVT 模型具有更好的性能。 -
对比PEG 和二维正弦编码
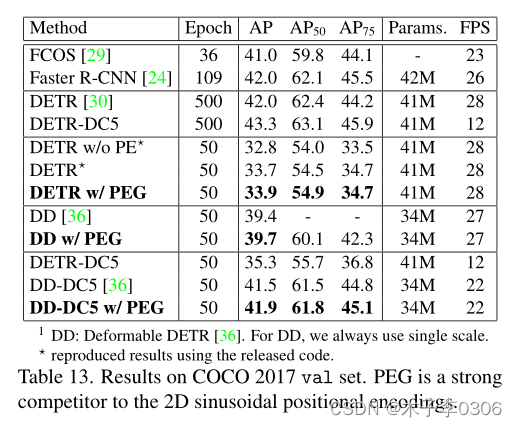
使用 PEG 的位置编码替换了原始的 2-D编码,获得了更好的性能。
物体检测的性能结果也表明 PEG 可以提供绝对位置信息,因为物体检测任务需要边界框的绝对坐标。 -
CPVT 中提出的 PEG 可以直接推广到更大的图像尺寸,而无需任何微调
在 224 ∗ 224 224*224 224∗224 图像上训练的 CPVT,应用到 384 ∗ 384 384*384 384∗384 上,效果相近,无需微调
总结
本文提出的 CPE (conditional positional encoding)位置编码可以实现比固定位置编码和可学习位置编码更强的性能。并且设计了一种位置编码生成器 PEG (Position Encoding Generator),加入了 PEG 的视觉变压器模型可以处理更长的输入序列并在视觉任务中保持所需的平移不变性。同时此 CPE 很容易实现并且成本可以忽略不计。
论文代码:GitHub
其他相关文章与知识
Self-attention:

Multi-head Self-Attention:




参考文献
[1] HOW MUCH POSITION INFORMATION DO CONVOLUTIONAL NEURAL NETWORKS ENCODE?
















 2294
2294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









