






Conditional position Encoding for Vision transformer
论文:https://arxiv.org/abs/2102.10882
代码:https://github.com/Meituan-AutoML/CPVT
目录:
三、VIT with Conditional position encodings
3.2. Conditional Positional Encodings
3.3. Conditional Positional Encoding Vision Transformers
4.2. Generalization to Higher Resolutions
4.3. CPVT with Global Average Pooling
4.5. Qualitative Analysis of CPVT
4.6. Comparison with State-of-the-art Methods
5.2. Single PEG vs. Multiple PEGs
5.3 Comparisons with other positional encodings
简单不看版:
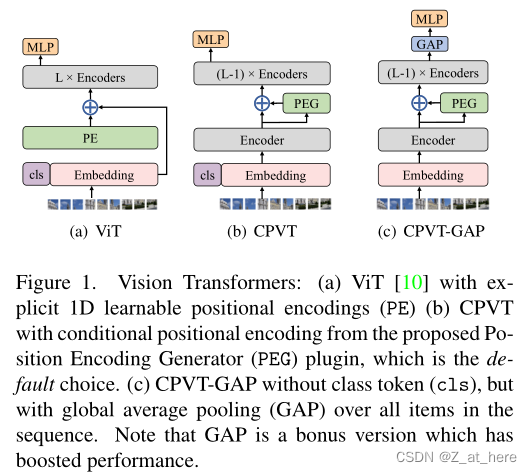
本文主要提出了一种基于条件位置码(CPE)的PEG,PEG相对比目前所存在的解决位置编码的方案可以使得TF(transformer)更灵活更泛化,并且在保证平移不变性的情况下减少了计算量,可以即插即用的加入到现有的深度学习框架中。作者将VIT做了两种改动,一种是只去掉了绝对位置编码,称之为CPVT,另一种是去掉了绝对位置编码和Cls_token,加入GAP来代替Cls_token的作用,称之为CPVT-GAP。如下图所示。

作者提出的当前TF在CV领域的应用还有一定的问题
1.目前的困难:
VIT中的绝对位置编码限制了TF的灵活性和泛化性。绝对位置编码需要和输入序列长度一一匹配。并且不能满足CV的平移不变性。已有的工作在使用绝对编码时解决方法有两个:1.现将预测图片resize到训练图片大小,然后输入。2.将提前设定好的位置编码进行插值操作,将其上采样到与目标序列长度相等。或者可以使用相对位置编码,但是相对位置编码不仅会带来额外的计算成本,而且还需要修改标准TF的实现。
2.解决办法:
本文提倡一种新的位置编码方案CPE,将位置信息融入到TF中。不同于在以前的工作中使用的位置编码是预定义的和输入无关的,而本文中提倡的的编码是动态生成的,并根据输入标记的局部邻域进行调整。因此,我们的位置编码根据输入的大小而改变,并可以保持所需的平移不变性。我们用我们的新编码方式应用在VIT上 (即CPVT,见图1(c)),可以得到比以前的VIT更好的性能。
摘要
我们提出了一种条件位置编码(CPE)方案。与以前(如VIT中)预定义的、独立于输入标记的固定或可学习的位置编码不同,CPE是动态生成的,并以输入token的局部邻域为条件。因此,CPE可以很容易地一般化到输入序列,比模型在训练中所看到的要长。此外,CPE在图像分类时能够保持期望的平移不变性,从而提高分类精度。CPE可以毫不费力地实现一个简单的位置编码生成器(PEG),它可以无缝地集成到当前的Transformer框架中。基于PEG,我们提出了CPVT。我们证明了CPVT具有与可学习的位置编码相比的视觉相似的注意图。基于CPE,我们在ImageNet分类任务上获得了较先进的结果到目前为止。
一、介绍
在cv领域,tf被认为是卷积的有力的替代品。卷积操作有感受野的限制,但是tf中的自注意力机制可以捕获长距离的信息并且可以根据图片内容动态改变感受野大小。因此,tf被认为比cnn更灵活、更强大,因此有望在视觉识别方面取得更大进展。
但是因为tf有permutation-invariant性质,之前的工作(如Attention is all you need,An image is worth 16x16 words: Transformers for image recognition at scale.)解决这问题的方法是给每一个输入序列中的token加入一个绝对位置编码。这些位置编码是可学习的,也可以用不同频率的正弦函数固定。尽管位置编码较为灵活,但还是影响力tf的灵活性和泛化能力。以可学习版本为例,编码通常是与输入序列长度相等的向量,在训练过程中与网络权值联合更新。因此,位置编码的长度和值一经训练即固定。在测试过程中,如果和之前训练时的长度不一致就会需要重新处理。有一种解决方式就是利用三次插值将位置编码上采样到和目标一致的长度,但这样会降低性能。此外,在某些CV领域我们还期望平移不变性。然而,绝对位置编码不能保证平移不变性,因为它为每个token(或每个patch)添加了唯一的位置编码。也有另外一种方法是使用相对位置编码(如Self-attention with relative position representations,2018)然而,相对位置编码不仅会带来额外的计算成本,而且还需要修改标准TF的实现。相对位置编码还是不能想绝对位置编码一样工作,因为图像识别任务仍然需要绝对位置信息(该文中提到How much position information do convolutional neural networks encode?,2020),而相对位置编码不能提供这些信息。
本文提倡一种新的位置编码方案,将位置信息融入到TF中。不同于在以前的工作中使用的位置编码[这三篇中Attention is all you need,VIT, Self-attention with relative position representations.],这些编码是预定义的和输入无关的,而本文中提倡的的编码是动态生成的,并根据输入标记的局部邻域进行调整。
因此,我们的位置编码根据输入的大小而改变,并可以保持所需的平移不变性。我们用我们的新编码方式应用在VIT上 (即CPVT,见图1(c)),可以得到比以前的VIT更好的性能[10,30]。
我们贡献如下:
1.提出一种新的位置编码策略称为CPE,CPE是由位置编码产生器(Positional Encoding Generators)动态生成的。可以容易的插入在现代深度学习框架中实现[18,1,6],不需要改变当前的TF APIs。
2.CPE依赖于输入标记的局部邻域,并可适应任意的输入大小,从而支持处理分辨率较大的图像。
3.CPE相对广泛使用的绝对位置编码,可以保证平移不变性,提高性能。
4.在CPE的基础上提出CPVT,在imageNET上取得好成绩。
除了上面提到的,我们还提供了一个可选项,在删除Embedding中Cls的同时,使用平移不变的全局平均池(GAP)进行类预测。利用GAP可以使CPVT具有完全的平移不变性,从而使CPVT的性能进一步提高约1%。相反,绝对位置编码的模型增加GAP只能获得较小的性能增益,因为它的位置编码已经打破了平移不变性。
二、相关工作
2.1 VIT
TF在NLP领域的成功被借鉴到了CV领域,但是Self-attention在用于CV中会有比较大的计算成本。因为一张图片中的像素数太多。VIT通过将图片划分为Patch避开了这个矛盾。DeiT[Training data-efficient image transformers & distillation through attention. arXiv:2012.12877, 2020.]基于ViT进一步提高了TF的数据效率,可以直接在ImageNet上进行训练。VIT还用于其他视觉任务,如分割领域End-to-end video instance segmentation with transformers. arXiv:2011.14503, 2020,(SETR)Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers,2020。
2.2 PE
Absolute Positional Encoding
绝对位置编码是应用最广泛的一种。在原TF论文[31]中,用不同频率的正弦函数生成PE,然后将它们加到输入端。另外,位置编码也可以学习,用固定维矩阵实现,并用SGD与模型的参数联合更新。
Relative Positional Encoding.
相对位置编码[Self-attention with relative position representations.2018]考虑输入序列中标记之间的距离。相对于绝对序列,相对位置编码具有平移不变性,能够较自然地处理训练过程中较长的序列。
Positional Encoding with Dynamical Systems
FLOATER(Learning to encode position for transformer with continuous dynamical model. PMLR, 2020.)这篇文章提出了一种新的方法,将位置信息建模为连续的动态模型。在训练过程中,FLOATER不受序列最大长度的限制,同时它是数据驱动和参数高效的。
与上述方法相比,我们提出了一种新的位置编码方法,该方法在保持这些方法的所有期望属性的同时,更简单。
三、VIT with Conditional position encodings
3.1 motivation
在ViT中,将图片划分成patch,这些patch上增加了相同长度的可学习的位置编码。在本文中,我们认为这里使用的位置编码有两个问题。一个是限制了模型处理不同于训练时的长度的向量。另一个是破坏了模型的平移不变性(translation invariance),因为绝对位置编码将每一个patch与固定的PE相结合,破坏了平移不变性。
第一个问题我们可以删除PE来解决,因为除了位置编码,所有其他组件(如MHSA和FFN)的VIT可以直接应用于较长的序列。但是这样会严重降低性能。这是可以理解的,因为输入序列的顺序是一个重要的线索,如果没有位置编码,模型无法使用顺序。
下表所示的就是各个不同位置编码的性能表现。

第一个问题还可以这样操作。在DeiT(Training data-efficient image transformers & distillation through attention. arXiv preprint arXiv:2012.12877, 2020.)中提到,可以将PE进行上采样操作,使得PE和输入向量长度相同。然而这种情况下需要多模型进行更多次的迭代,不然性能会有明显的下降。
相对位置编码(relative position encoding)[26,2]可以解决上述两个问题。但是相对位置编码不能提供任何绝对位置信息,如[How much position information do convolutional neural networks encode? 2020]所示,绝对位置信息对分类任务也很重要。
所以现有的解决方法还存在一定的弊端。
3.2. Conditional Positional Encodings
在本研究中,我们认为成功的视觉任务定位编码应满足以下要求
1. 处理sequence时,操作具有permutation-variant但translation-equivariance特性:对位置敏感但同时具有平移等价性
2. 具有归纳能力,能够处理比训练时更长的序列
3. 具有在一定程度上提供绝对位置的能力。这对性能非常重要,如[13]所示
在这项工作中,我们发现用位置编码表征局部关系足以满足上述所有条件。首先,他是permutation-variant的,因为输入序列的每一次变异也会影响某些局部邻域的顺序。相反,在输入图像中,对象的平移可能不会改变其局部邻域的顺序,即平移不变性。(没看懂In this work, we find that characterizing the local relationship by positional encodings is sufficient to meet all of the above. First, it is permutation-variant because the per-mutation of input sequences also affects the order in some local neighborhoods. In contrast, the translation of an object in an input image might not change the order in its local neighborhood, i.e., translation-invariant.),其次,由于只涉及一个token的局部邻域,所以该模型可以很容易地推广到较长的序列。另外,如果已知任何一个输入token的绝对位置,则可以通过输入token之间的相互关系推断出其他所有token的绝对位置。我们将展示使用零填充的情况下,边界上的token可以知道它们自己的绝对位置。
因此,我们提出了位置编码生成器(PEG)动态生成基于输入标记的局部邻域的位置编码。
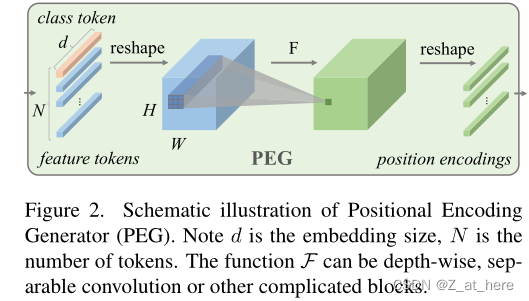
Positional Encoding Generator.
PEG如上图所示,为了满足局部领域的条件,首先,我们将DeiT的扁平化输入序列X(B*N*C)reshape为二维图像空间中的B*H*W*C。然后,一个函数(在图2中用F表示)被反复应用于X中的每一个局部补丁,这样就可以产生条件性的位置编码E(B*H*W*C)。PEG可以通过一个kernel size为K,padding为(K-1)/2的二维卷积来有效地实现。注意的是每一个token来确定位置的非常重要条件就是padding操作,并且F函数可以用不同变体,比如可分离卷积或者其他等等。
3.3. Conditional Positional Encoding Vision Transformers
基于条件位置编码,我们提出了条件位置编码视觉变换(CPVT,Conditional Positional Encoding Vision Transformers)。除了我们的位置编码是有条件的,我们完全遵循ViT和DeiT来设计我们的Vision Transformer。我们还有三种尺寸的CPVT-Ti,CPVT-S ,CPVT-B。类似于DeiT中原始的位置编码,条件位置编码也被添加到输入序列中,如下图所示。在CPVT中,PEG的位置对性能也很重要,这将在实验中进行研究。

此外,DeiT和ViT都利用一个额外的可学习类标记来进行分类,如图一中的a和b。Class token破坏了平移不变性,通过设计也可以将其学习成保证平移不变性的。一个简单的替代方法是直接用一个全局平均池(GAP)替换class token,GAP本身是平移不变的。因此,我们也提出CVPT-GAP,其中class token被替换为GAP。如图一c所示。加上保证平移不变的位置编码,CVPT-GAP性能更好并且成为了终极的平移不变。
四、Experiments
4.1 setup
Datasets. Following DeiT [30], we use ILSVRC-2012 ImageNet dataset [8] with 1K classes and 1.3M images to train all our models. We report the results on the validation set with 50K images. Unlike ViT [10], we do not use the much larger undisclosed JFT-300M dataset [27].
Model variants. As mentioned before, we also have three models with various sizes to adapt to various computing scenarios. The detailed settings are shown in Table 2. All experiments in this paper are performed on Tesla V100 machines. Training the tiny model for 300 epochs takes about 1.3 days on a single node with 8 V100 GPU cards. CPVT-S and CPVT-B take about 1.6 and 2.5 days, respectively.Our proposed PEG has little impact on the computational complexity of the models and uses even fewer parameters than the original learnable positional encodings in DeiT, as shown in Sec. 4.4.
Training details All the models (except for CPVT-B) are trained for 300 epochs with a global batch size of 2048 on Tesla V100 machines using AdamW optimizer [16]. We don’t tune the hyper-parameters and strictly comply with the settings in DeiT [30]. The learning rate is scaled with this formula lrscale =
(0.0005∗BatchSize global)/512。Although it may be sub-optimal for our method, our approach can obtain competitive results compared with [30]. The detailed hyperparameters are in the supplementary.
4.2. Generalization to Higher Resolutions
证明了低分辨率训练的网络可以用来预测高分辨率图片并取得不错的结果
如前所述,我们提出的PEG可以直接推广到更大的图像尺寸,而无需任何微调。我们使用224*224的图片训练的模型来预测384*384的图片可以证明这一点。如下图所示,输入图像大小为384 × 384,具有可学习位置编码的DeiT-tiny从72.2%下降到71.2%,当采用正弦编码时,DeiT-tiny从72.2%下降到70.8%。相反,采用该PEG的CPVT模型可以直接处理较大的工件。(论文中这段原文中提到的数据和表格不匹配,在这边就不翻译,不是很懂,大佬的文章也这样,有点难以置信)。

我们在这里进一步评估在大图像上微调模型的性能。具体来说,我们使用5e-6的学习率,将在224上训练的小模型微调到384(固定),共20个epoch,batch size为512。对于微调DeiT,我们采用了近似保留位置嵌入向量范数为[Training data-efficient image transformers & distillation through attention]的双三次插值,或者我们观察到显著下降超过6%的[Training data-efficient image transformers & distillation through attention]。
4.3. CPVT with Global Average Pooling
经过设计我们提出的PEG具有平移不变性。因此,如果我们在CPVT的最终分类层之前使用平移不变的全局平均池(GAP),并且去掉cls_token,CPVT就具有完整的平移不变性,有利于ImageNet分类任务的完成。并且值得注意的是,在这里使用GAP会减少计算复杂度,因为我们不需要计算cls_token和patch之间的注意力交互。
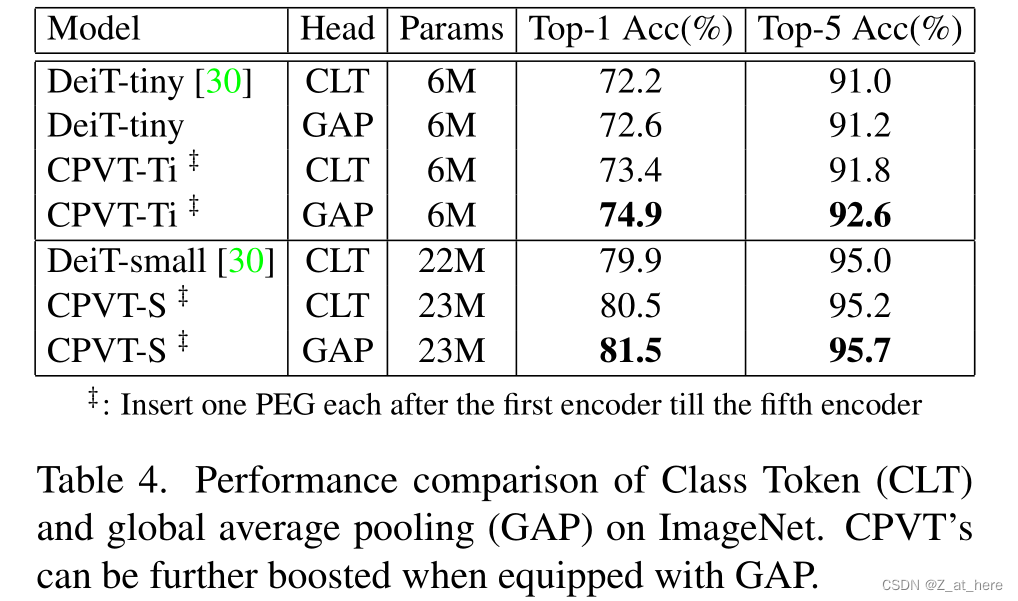
相比之下,DeiT与GAP的结合无法取得较大的进步(如表4所示,只有0.4%),因为原始的绝对位置编码已经打破了平移不变性。鉴于其优越的性能,我们希望我们的发现可以成为进一步研究视觉变压器的有力选择。
4.4. Complexity of PEG
Few Parameters FLOPs.
4.5. Qualitative Analysis of CPVT
到目前为止,我们已经证明了PEG可以比原始位置编码有更好的性能。但是,因为PEG以隐式的方式提供位置,所以看看PEG是否确实可以作为原始位置编码提供位置信息是很有趣的。在这里,我们通过可视化tf的注意力权重来研究这一点。具体来说,给定一个224×224图像(即14×14 patches),单个头部内的得分矩阵为196×196。我们将第二个编码器块的规范化的self-attention score matrix可视化。
略掉……(这一段没太读懂)
4.6. Comparison with State-of-the-art Methods
对CPVT模型在ImageNet验证集上进行了评估,结果如表五所示。相比于DeiT,在两者有着相同吞吐量的情况下CPVT性能要更好。CPVT可以在输入序列更长的时候体现出性能的提升,而DeiT则会下降。我们提出的CPVT-GAP版本是坐高版本。
详细去看论文。
五. Ablation Study
5.1. Positions of PEG in CPVT
将PEG放在不同的位置上,做对比。VIT中的TF Encoder中的L为12,分别记作-1到10,CPVT中将PEG分别添加在-1,0,3,6,10层来测试性能。结果如表六显示


作者发现在0层时的表现比-1层的要好,作者认为这是因为在0层时有更大的感受野,具体点就是0层时更注重全局范围,而-1层时更注重局部范围。作者推断基于此种情况,那在-1层的时候增大卷积核可以将性能提升。作者在表7中进行了验证,并证明了推断的正确性。
5.2. Single PEG vs. Multiple PEGs
我们进一步评估使用多位置编码是否有利于表8中的性能。注意,我们用i-j表示从第i个编码器开始到第j - 1个编码器结束的PEG的插入位置。通过在5个位置插入peg,微型模型的top-1精度进一步提高到73.4%,比DeiT-tiny模型高1.2%。同样,CPVT-S达到了一个新的水平(80.5%)。

5.3 Comparisons with other positional encodings
作者将PEG与常见的位置编码作比较:绝对位置编码(absolute positional encoding)、想对位置编码(relative positional encoding)、可学习编码(learnable encoding)作比较,结果如下表所示。

六.Conclusion
在本文中,我们引入了一种新颖的CPVT方法来提供VIT中的位置信息,它根据每个token的局部邻域动态生成位置编码。通过大量的实验研究,我们证明了我们提出的位置编码可以获得比之前的位置编码更强的性能。使用我们的位置编码的变压器模型可以自然地处理较长的输入序列,并在视觉任务中保持所需的平移不变性。此外,我们的位置编码很容易实现,成本可以忽略不计。我们期待我们提出的方法在TF驱动的视觉任务,如分割和视频处理中有更广泛的应用。















 2294
2294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









