







论文标题:
Denoised Self-Augmented Learning for Social Recommendation
收录会议:
IJCAI 2023
论文链接:
https://arxiv.org/abs/2305.12685
代码链接(欢迎 ✨):
https://github.com/HKUDS/DSL
港大数据智能实验室(指导老师:黄超)
https://sites.google.com/view/chaoh
研究背景
社交推荐通过将社交信息注入用户偏好学习来提高推荐系统的质量,人们开发了各种神经网络技术来对具有社交意识的用户偏好进行编码从而进行推荐。 目前,最先进的社交推荐方法是使用图神经网络(GNN)进行递归消息传递来构建的,从而捕获高阶关系。
有监督的 GNN 增强模型需要大量的有监督标签来生成准确的用户表示,这在实际的社交推荐场景中很难实现。基于自监督学习(SSL)的增强会受到嘈杂的社会关系的严重阻碍。 例如,人们可能与同事、同学或家庭成员建立社会联系,但他们彼此之间可能没有很多共同兴趣。并且,嘈杂的社会影响可能与现实生活推荐场景中的用户偏好不一致。
为了解决这些局限性,我们提出了名为 DSL 的去噪自增强学习范式。该模型利用社交信息,通过抗噪声的自监督学习更好地表征用户偏好,追求跨视图对齐。 我们开发了一个双视图图神经网络来编码用户社交和交互图上的隐层表示。为减轻社会关系对推荐的偏差,我们设计了一个去噪模块来增强集成的社会意识自监督学习任务。
我们的研究成果主要包含以下几点:
- 我们研究了用于社会推荐的去噪自增强学习,有效减少了嘈杂的社会关系对社会意识协作信号表示的影响。
- 我们提出 DSL,实现社交视图和交互视图的编码嵌入之间的去噪跨视图对齐。
- 我们通过在三个真实数据集上的实验,展示了 DSL 相较于现有先进方法的显著性能提升。
模型介绍
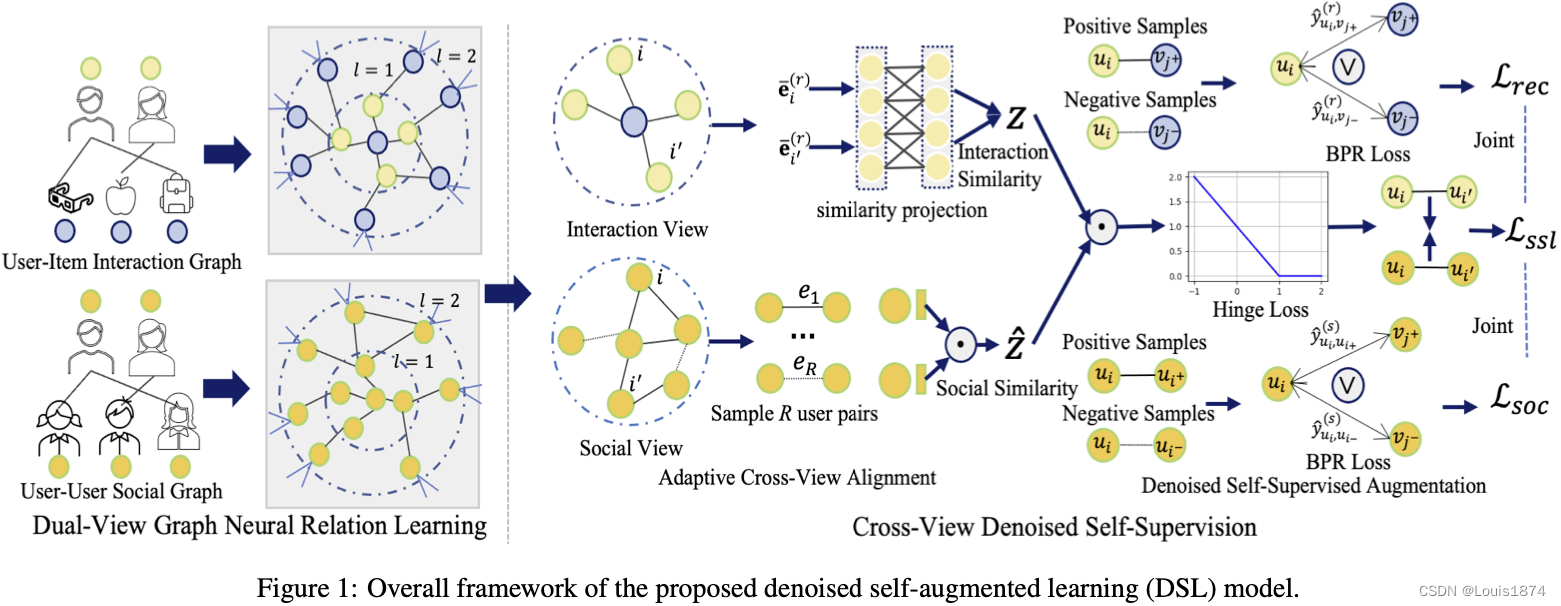
2.1 双视图图神经关系学习
通过初始化的 id 嵌入,DSL 首先采用双视图图神经网络来捕获用户-商品交互和用户-用户社交关系的高阶协作关系。 受到轻量级 GCN 增强的协同过滤范式的启发,DSL 配置了一个简化的图神经网络。
我们的 GCN 在用户-商品交互图上的迭代信息传播方案:
E r ( l ) = ( L r + I ) ⋅ E r ( l − 1 ) \textbf{E}^{(l)}_r = (\mathcal{L}_r+\textbf{I})\cdot \textbf{E}^{(l-1)}_r Er(l)=(Lr+I)⋅Er(l−1)
这里 E r ( l ) , E r ( l − 1 ) ∈ R ( I + J ) × d \textbf{E}^{(l)}_r,\textbf{E}_r^{(l-1)}\in\mathbb{R}^{(I+J)\times d} Er(l),Er(l−1)∈R(I+J)×d 分别表示 l l l 次用户-商品关系建模迭代后的用户和商品嵌入。 I ∈ R ( I + J ) × ( I + J ) \textbf{I}\in\mathbb{R}^{(I+J)\times (I+J)} I∈R(I+J)×(I+J) 表示用于自环的单位矩阵。 L r ∈ R ( I + J ) × ( I + J ) \mathcal{L}_r\in\mathbb{R}^{(I+J)\times (I+J)} Lr∈R(I+J)×(I+J) 表示用户-商品交互图的拉普拉斯矩阵。
L r = D r − 1 2 A r D r − 1 2 , A r = [ 0 R R ⊤ 0 ] \mathcal{L}_r=\textbf{D}_r^{-\frac{1}{2}}\textbf{A}_r\textbf{D}_r^{-\frac{1}{2}},~~~~ \textbf{A}_r=\left[\begin{array}{cc}\textbf{0} & \textbf{R} \\\textbf{R}^{\top} &\textbf{0}\end{array}\right] Lr=Dr−21ArDr−21, Ar=[0R⊤R0]
R ∈ R I × J \textbf{R}\in\mathbb{R}^{I\times J} R∈RI×J 表示用户-商品交互矩阵, 0 \textbf{0} 0 表示全 0 矩阵。用户-商品交互视图的双向相邻矩阵 A r \textbf{A}_r Ar 乘以其对应的对角度矩阵 D r \textbf{D}_r Dr 进行归一化。
对用户的社交关系进行编码,将轻量级 GCN 应用于用户社交图 G s \mathcal{G}_{s} Gs。 具体来说,我们的社交视图 GNN 通过设置 E s ( 0 ) = E u \textbf{E}^{(0)}_s=\textbf{E}_u Es(0)=Eu 将初始用户的 id 对应嵌入作为输入。
E s ( l ) = ( L s + I ) ⋅ E s ( l − 1 ) , L s = D s − 1 2 S D s − 1 2 \textbf{E}^{(l)}_s=(\mathcal{L}_s+\textbf{I})\cdot\textbf{E}_s^{(l-1)},~~~~\mathcal{L}_s=\textbf{D}_s^{-\frac{1}{2}}\textbf{S}~\textbf{D}_s^{-\frac{1}{2}} Es(l)=(Ls+I)⋅Es(l−1), Ls=Ds−21S Ds−21
这里 S ∈ R I × I \textbf{S}\in\mathbb{R}^{I\times I} S∈RI×I 对用户的社交关系进行编码, D s , L s ∈ R I × I \textbf{D}_s, \mathcal{L}_s\in\mathbb{R}^{I\times I} Ds,Ls∈RI×I 分别表示社交视图对应的对角度矩阵和归一化的拉普拉斯矩阵。 E s ( l ) , E s ( l − 1 ) ∈ R I × d \textbf{E}_s^{(l)},\textbf{E}_s^{(l-1)}\in\mathbb{R}^{I\times d} Es(l),Es(l−1)∈RI×d 分别是第 l l l 次和第 ( l − 1 ) (l-1) (l−1) 次图神经迭代中用户的社交嵌入。
采用均值池化聚合不同阶的嵌入:
E ˉ r = ∑ l = 0 L E r ( l ) , E ˉ s = ∑ l = 0 L E s ( l ) \bar{\textbf{E}}_r = \sum_{l=0}^L\textbf{E}_r^{(l)},~~~~\bar{\textbf{E}}_s = \sum_{l=0}^L\textbf{E}_s^{(l)} Eˉr=l=0∑LEr(l), Eˉs=l=0∑LEs(l)
这里 L L L 为图迭代的最大值。
2.2 跨视图去噪自监督
在现实生活场景中,被动建立的社交关系,例如同事或同学,由于其不同的购物兴趣,可能不会对用户交互偏好带来太大影响。 盲目依赖这种不相关的社交关系来推断用户的兴趣可能会损害社交推荐模型的性能。 为了解决这个问题,我们过滤掉不同用户之间关于他们的交互偏好的嘈杂的社会影响,以进行无偏移的自监督。
在我们的 DSL 中,我们结合了跨视图去噪任务,用辅助自监督信号来补充主要学习任务。 学习到的用户交互模式指导社交关系去噪模块根据观察到的社交关系过滤掉误导性的嵌入传播。
给定从交互 GNN 学习到的用户嵌入 ( e ˉ i ( r ) , e ˉ i ′ ( r ) ) (\bar{\textbf{e}}^{(r)}_i, \bar{\textbf{e}}^{(r)}_{i'}) (eˉi(r),eˉi′(r)),用户对 ( i , i ′ ) (i, i') (i,i′) 间交互相似度定义为 z i , i ′ = [ e ˉ i ( r ) ; e ˉ i ′ ( r ) ] z_{i,i'} = [\bar{\textbf{e}}^{(r)}_i;\bar{\textbf{e}}^{(r)}_{i'}] zi,i′=[eˉi(r);eˉi′(r)]。同样,基于社交 GNN 编码得到的用户表示 ( e ˉ i ( s ) , e ˉ i ′ ( s ) ) (\bar{\textbf{e}}^{(s)}_i, \bar{\textbf{e}}^{(s)}_{i'}) (eˉi(s),eˉi′(s)),用户社交相似度定义为 z ^ i , i ′ = [ e ˉ i ( s ) ; e ˉ i ′ ( s ) ] \hat{z}_{i,i'}=[\bar{\textbf{e}}_i^{(s)};\bar{\textbf{e}}_{i'}^{(s)}] z^i,i′=[eˉi(s);eˉi′(s)]。为消除交互视图和社交视图的语义差异,我们设计相似度投影函数,将交互语义映射到隐层空间用来跨视图对齐:
z i , i ′ = sigm ( d ⊤ ⋅ σ ( T ⋅ [ e ˉ i ( r ) ; e ˉ i ′ ( r ) ] + e ˉ i ( r ) + e ˉ i ′ ( r ) + c ) ) z_{i,i'} = \text{sigm}(\textbf{d}^\top\cdot\sigma(\textbf{T}\cdot[\bar{\textbf{e}}^{(r)}_i;\bar{\textbf{e}}^{(r)}_{i'}]+\bar{\textbf{e}}^{(r)}_i+\bar{\textbf{e}}^{(r)}_{i'}+\textbf{c})) zi,i′=sigm(d⊤⋅σ(T⋅[eˉi(r);eˉi′(r)]+eˉi(r)+eˉi′(r)+c))
这里 sigm ( ⋅ ) \text{sigm}(\cdot) sigm(⋅) 和 σ ( ⋅ ) \sigma(\cdot) σ(⋅) 分别表示 Sigmoid 和 LeakyReLU 激活函数。 d ∈ R d , T ∈ R d × 2 d , c ∈ R d \textbf{d}\in\mathbb{R}^d, \textbf{T}\in\mathbb{R}^{d\times 2d}, \textbf{c}\in\mathbb{R}^d d∈Rd,T∈Rd×2d,c∈Rd 为可学习的参数。
为了注入去噪的社会影响来提高推荐质量,我们设计了一个自监督学习任务,用于通过增强嵌入正则化进行跨视图对齐,损失函数为:
L s s l = ∑ ( u i , u i ′ ) max ( 0 , 1 − z i , i ′ z ^ i , i ′ ) L_{ssl} = \sum_{(u_i,u_{i'})} \max (0, 1-z_{i,i'}\hat{z}_{i,i'}) Lssl=(ui,ui′)∑max(0,1−zi,i′z^i,i′)
用户对 ( u i , u i ′ u_i, u_{i'} ui,ui′) 是从用户集合 U \mathcal{U} U 中单独采样的。有了上述的自监督学习目标,综合用户关系预测任务将基于自监督信号进行社会影响去噪的指导。 这样做,具有不同偏好的用户之间的嘈杂的社会联系将导致可区分的用户表示,以增强推荐。
2.3 多任务模型优化
我们的 DSL 的学习过程涉及模型优化的多任务训练。 增强的自监督学习任务与主要推荐优化损失相结合,以对去噪的社交感知用户偏好进行建模。给定用户和商品嵌入,我们预测用户-商品 ( y ^ u i , v j ( r ) ) (\hat{y}_{u_i,v_j}^{(r)}) (y^ui,vj(r)) 和用户-用户 ( y ^ u i , u i ′ ( s ) ) (\hat{y}_{u_i, u_{i'}}^{(s)}) (y^ui,ui′(s)) 关系为:
y ^ u i , v j ( r ) = e ˉ i ( r ) ⊤ e ˉ j ( r ) ; y ^ u i , u i ′ ( s ) = e ˉ i ( s ) ⊤ e ˉ i ′ ( s ) \hat{y}_{u_i,v_j}^{(r)} = \bar{\textbf{e}}_i^{(r)\top} \bar{\textbf{e}}_j^{(r)};~~~~ \hat{y}_{u_i, u_{i'}}^{(s)} = \bar{\textbf{e}}_i^{(s)\top} \bar{\textbf{e}}_{i'}^{(s)} y^ui,vj(r)=eˉi(r)⊤eˉj(r); y^ui,ui′(s)=eˉi(s)⊤eˉi′(s)
这里 y ^ u i , v j ( r ) ∈ R \hat{y}_{u_i,v_j}^{(r)} \in \mathbb{R} y^ui,vj(r)∈R 表示在交互视图中用户 u i u_i ui 与商品 v j v_j vj 交互的可能性, y ^ u i , u i ′ ( s ) \hat{y}_{u_i, u_{i'}}^{(s)} y^ui,ui′(s) 表示 u i u_i ui 和 u i ′ u_{i'} ui′ 拥有社交关联的概率。
通过最小化 BPR 损失函数进行优化:
L r e c = ∑ ( u i , v j + , v j − ) − ln sigm ( y ^ u i , v j + ( r ) − y ^ u i , v j − ( r ) ) {L}_{rec} = \sum_{(u_i,v_{j^+}, v_{j^-})} - \ln \text{sigm}(\hat{y}_{u_i,v_{j^+}}^{(r)} - \hat{y}_{u_i,v_{j^-}}^{(r)})\nonumber Lrec=(ui,vj+,vj−)∑−lnsigm(y^ui,vj+(r)−y^ui,vj−(r))
L s o c = ∑ ( u i , u i + , u i − ) − ln sigm ( y ^ u i , u i + ( s ) − y ^ u i , u i − ( s ) ) {L}_{soc} = \sum_{(u_i,u_{i^+}, u_{i^-})} - \ln \text{sigm}(\hat{y}_{u_i,u_{i^+}}^{(s)} - \hat{y}_{u_i,u_{i^-}}^{(s)}) Lsoc=(ui,ui+,ui−)∑−lnsigm(y^ui,ui+(s)−y^ui,ui−(s))
这里 v j + v_{j^+} vj+ 和 v j − v_{j^-} vj− 表示对用户 u i u_i ui 采样的正负例。 u i + u_{i^+} ui+ 和 u i − u_{i^-} ui− 分别从 u i u_i ui 的社交关联和未关联用户中采样。通过将自监督学习目标与权重参数 λ 1 \lambda_1 λ1、 λ 2 \lambda_2 λ2、 λ 3 \lambda_3 λ3 相结合,联合优化损失为:
L = L r e c + λ 1 L s o c + λ 2 L s s l + λ 3 ( ∥ E u ∥ F 2 + ∥ E v ∥ F 2 ) L = L_{rec} + \lambda_1 L_{soc} + \lambda_2 L_{ssl} + \lambda_3 (\|\textbf{E}_u\|_F^2 + \|\textbf{E}_v\|_F^2) L=Lrec+λ1Lsoc+λ2Lssl+λ3(∥Eu∥F2+∥Ev∥F2)
实验结果
我们进行了大量的实验评估 DSL 的有效性。
我们对从 Ciao、Epinions 和 Yelp 在线平台收集的三个基准数据集进行了实验,除了观察到的对不同商品的隐式反馈(例如评分、点击)之外,还可以在用户之间建立社交联系。表 1 列出了实验数据集的详细统计信息。
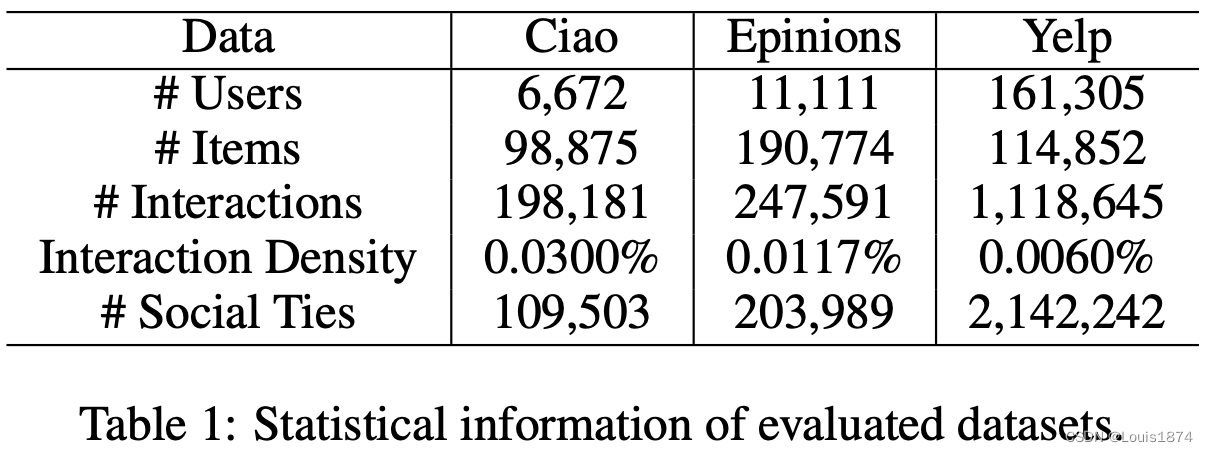
表 2 表明,我们的 DSL 框架始终优于各种数据集上的所有基线,提供了其有效性的证据。

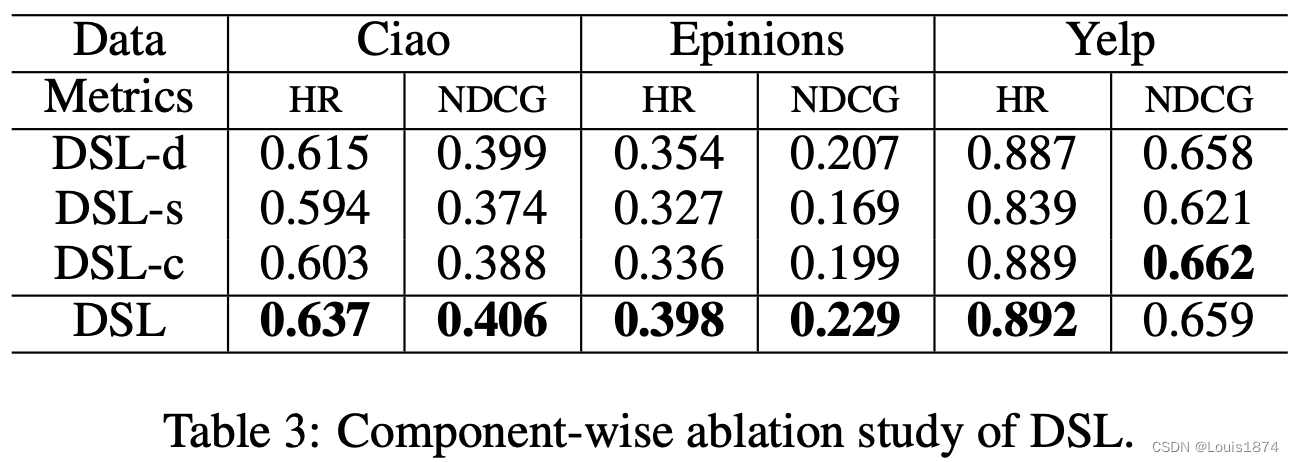
为了研究我们的去噪自监督学习范式在提高性能方面的重要作用,我们对关键模型组件进行了消融研究。结果如表 3 所示。从我们的结果来看,我们观察到我们的 DSL 在大多数评估案例中都优于其他变体。
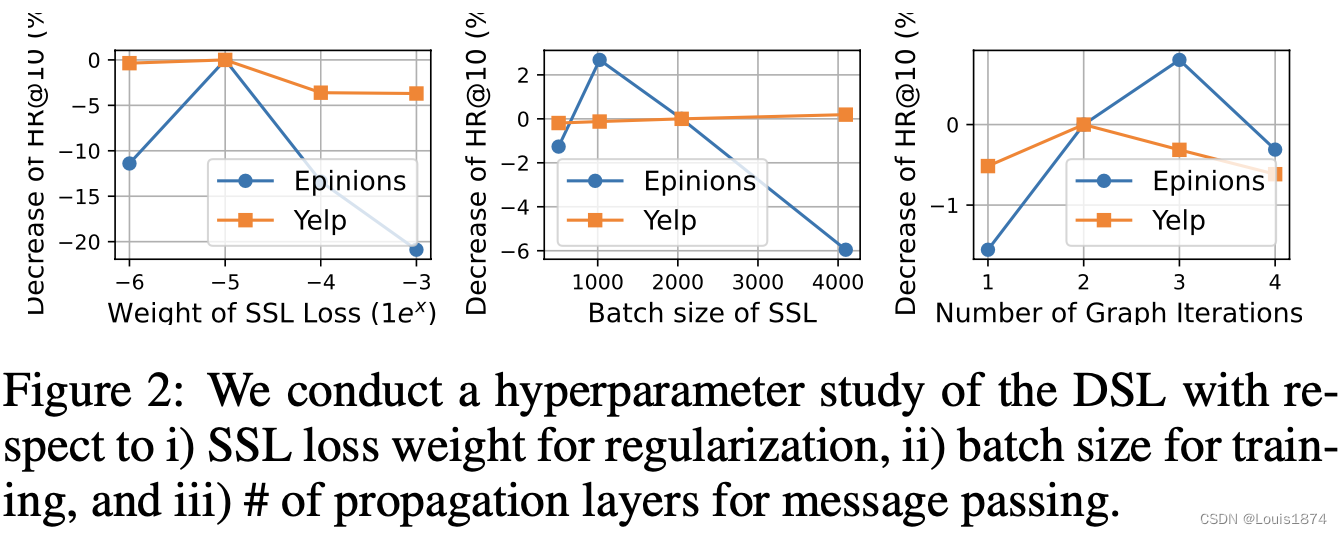
我们还探索关键超参数对 DSL 性能的影响,包括 SSL 损失权重、批量大小和图传播层的数量。 结果如图 2 所示,其中 y 轴表示与默认参数设置相比的性能变化率。
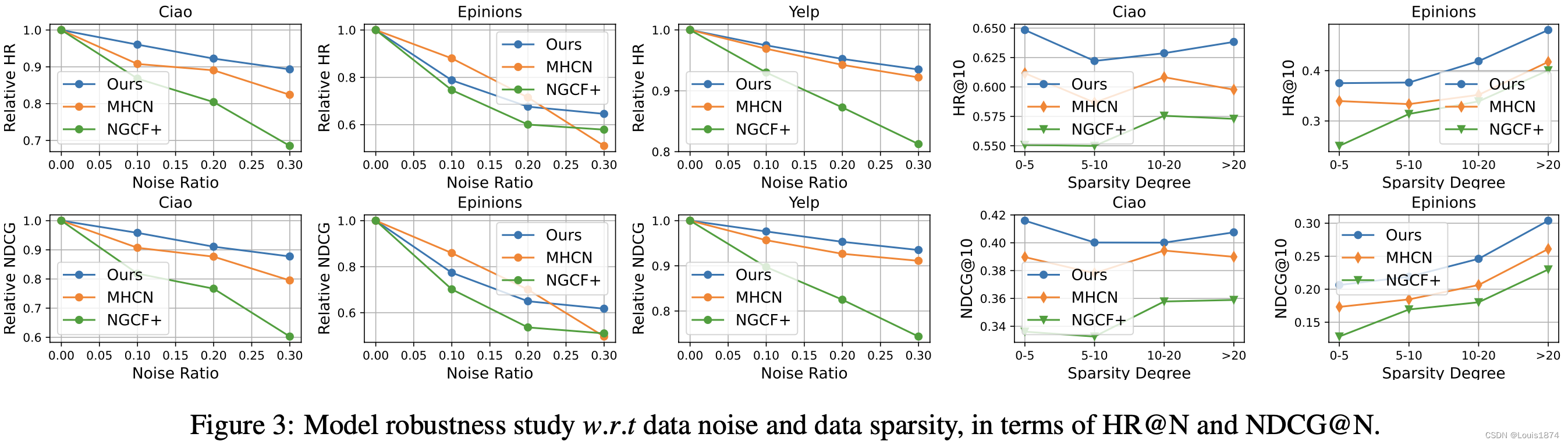
我们研究了 DSL 针对数据稀疏性和噪声的鲁棒性以进行推荐。结果如图 3 所示。
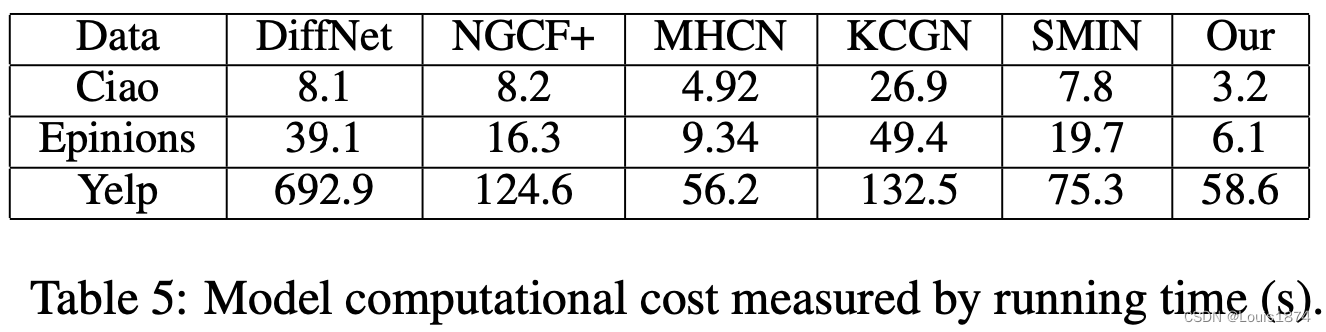
我们在 NVIDIA GeForce RTX 3090 上测量了不同方法的计算成本(运行时间),并在表 5 中列出了每个模型的训练时间。DSL 的训练成本明显低于大多数比较基准,展示了其在现实生活推荐场景中处理大规模数据集的可扩展性。
总结
在这项工作中,我们提出了一种通用的去噪自增强学习框架,该框架不仅结合了社会影响力来帮助理解用户偏好,而且还通过识别社会关系偏差和去噪跨视图自监督来减轻噪音影响。 为了消除社交和交互语义视图之间的差距,该框架引入了可学习的跨视图对齐,以实现自适应自监督增强。 实验结果表明,与现有基线相比,我们的新 DSL 显着提高了推荐准确性和鲁棒性。















 6671
6671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









