







Task5 SVM
支持向量机(Support Vector Machine,即SVM)是一种典型的二分类模型,与传统的分类器不同,SVM分类器在实现经验风险最小化的基础上,还要求置信范围尽可能小,也就是说最终目的是寻找结构风险最小化。通俗的来说,SVM二分类本质就是通过在特征空间内寻找间距最大的超平面将数据划分为两类,以实现区分。SVM于1964年提出,该算法能够有效处理非线性问题,泛化能力强,具有鲁棒性,至今依然是解决一些非线性问题的首选方法,其中HOG+SVM的特征提取识别组合成了许多识别问题的主要思想,下面介绍SVM的基本算法。
假设给定训练样本,在一个样本空间内的划分超平面有无数个。
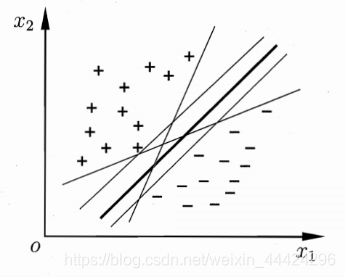
虽然划分样本的超平面很多,但是最优超平面只有一个,正如图4.7的粗线所示。由于数据噪声等因素的影响,可能导致图中的正例向下偏移,而负例向上偏移,这就导致了一些超平面的划分出现了错误,图中粗线所在的超平面能够有效的避免这个问题,因此它的泛化能力最强,抗干扰能力最好,求解出这个超平面正是SVM算法的目的。
通常我们定义样本空间的超平面如下面公式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









