







前言
- 学习SVM的数学模型,需要对拉格朗日乘数法、KKT条件、对偶问题、超平面这四类问题有充分的了解,所以在写这篇文章之前,我先写了四篇关于上述问题的详细介绍,有需要的同学可以去我的博客中阅览,这里附上四篇文章的链接:
https://blog.csdn.net/qq_41076797/article/details/112676195
https://blog.csdn.net/qq_41076797/article/details/112763987
https://blog.csdn.net/qq_41076797/article/details/112781675
https://blog.csdn.net/qq_41076797/article/details/112830324 - 明白了上面四篇博客的内容之后,再看SVM的数学模型就轻松多了,因为我也是在学习,边学习边记录,所以也查阅了大量的博客及视频资料,下面的内容是我认为讲述的比较清楚的资料,然后加上我的补充说明成文,所以下面的内容有大量的引用图片及文字,我在这里附上引用的博客及视频网址,https://www.jianshu.com/p/95e56d5126fd、https://www.bilibili.com/video/BV1ZE411p73x?p=3
https://zhuanlan.zhihu.com/p/31886934 - 交代完上述内容后,下面我们进入关于SVM的数学模型的学习。
内容
问题背景
- 首先我们看一下问题背景

- 上面是一个线性可分的训练样本,我们知道,既然是线性可分的,不管是多少维度的数据,总有一个超平面可以将训练样本分开,我们这里为了方便绘图,用的二维数据,所以存在那么一条直线可以将训练样本分隔开。另外我们注意到上图中有好多条线可以做到成功分割两类数据,但SVM不光要分开,还要找到分类效果最好的那条线,何谓分类效果最好?请继续往下看。
SVM思想
- 如图

前提假设

这里的
x
i
x_{i}
xi是一个向量。
支持向量
- 前面我们已经说了,svm的思想是找到与支持向量间隔最大的那条最优分割线,我们首先要明白什么是支持向量,
- 见下图:

如果想正确区分红色和绿色的点,其实内在的原理(跑程序的时候也是这么跑的)是,我们计算所有样本点距离某个超平面的间隔,然后找到间隔中的最小值,然后我们要尽可能的调整参数即调整最优分割线使得这个最小值尽可能的变大。也就是说我们真正关心的其实是最小值这个间隔,而不是所有样本的间隔,而最小值间隔对应的样本点就是支持向量。
如上图,我们真正在乎的样本点就是上图中圈出来的四个点(大致是这四个点,也有可能因为肉眼无法辨别的细微偏差所以某个点不是),它们就是所谓的支持向量。 - 再看下图

上面那三个距离最优分割线最近的点才是我们关心的点,它们到最优分割线的距离是各自类的样本中最小的,我们的任务就是尽可能的扩大这个最小间隔。
间隔
- 然后我们要讲一下间隔。
- 函数间隔:
在超平面wx+b=0确定的情况下,|wx+b|能够相应地表示点x距离超平面的远近,而wx+b的符号与类标记y的符号是否一致能够表示分类是否正确,所以可以用y(wx+b)来表示分类的正确性及确信度,这就是函数间隔的概念。则超平面关于样本点(xi,yi)的函数间隔可表示为:
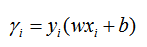
- 但是问题来了,你想啊,假如我成比例的同时缩放w和b,使得样本带入函数间隔的确放大了函数间隔那可怎么办!!!别忘了,成比例缩放w和b是不改变超平面的呀,可是你用这种取巧的方式的确放大了函数间隔!但实质上,超平面还是那个超平面!可恶!看来函数间隔是靠不住了。
- 那我们是不是应该总结一下原因呢?我们败在了等比例缩放w和b上了,我们不能让机器成功采取这种措施,说白了,怎么才能彻底杜绝成比例缩放w和b呢?下面看几何间隔的厉害!
- 几何间隔:

不要懵,待我给你看个例子先:


你自己动手算一算乘以1/3,你会惊喜的发现,几何间隔和原来一样还是1/sqrt(5)。原理是什么呢,请看下面的推导:

其实函数间隔是个假的间隔,它仅仅是能够同时表示出分类的正确性及距离,但是它有很大的缺陷。而几何间隔其实是正宗的超平面点到平面的距离公式,我超平面那节博客里就是这个公式。 - 总的来说,在SVM的迭代过程中,为了不让机器有钻空子的可能,我们要堵死它幻想通过仅仅等比例改变w和b来满足优化目标的可能性,而是强迫它去优化几何间隔,好,下面引出优化条件。
确定优化条件
- 明确了使用几何间隔来衡量样本点到超平面的距离之后,我们下一步就是要确定优化条件了。
- 记得刚才说过我们关心的重点仅仅是支持向量到最优分割线的间隔,所以我们先要找到这个间隔:

对,就是计算出所有样本的间隔,然后取最小的那个,这个样本就是支持向量。

我们要在保证其他所有间隔都大于这个最小间隔的基础上,尽可能的扩大这个最小间隔,线性可分分离超平面有无穷多个,但是几何间隔最大的分离超平面(最大间隔分离超平面)是唯一存在的。

γ ∧ γ_{∧} γ∧是函数间隔, γ ∧ = ∣ ∣ w ∣ ∣ ∗ γ γ_{∧}=||w||*γ γ∧=∣∣w∣∣∗γ
因为函数间隔的取值不影响最优化问题的解,所以取函数间隔=1(其实就是拿到一个x向量,然后计算函数间隔,如果不为1,则对w和b同时除以函数间隔进行人为放缩,而且此时是不影响超平面,也不影响几何间隔的),则问题可以改写为:
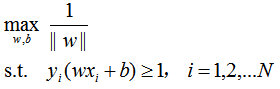
注意到:最大化1/||w||等价于最小化||w||²/2,则问题可以改写为:
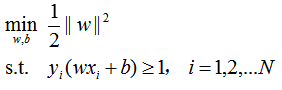
也就是说,对于所有的训练样本,首先我们找到最近的那些支持向量,并且计算出它的几何间隔 γ γ γ,然后我们最初级的要求是在所有点与超平面的几何间隔小于 γ γ γ的基础上,尽可能的扩大 γ γ γ的值,也就是尽可能拉大支持向量与超平面的距离,这个很好理解。但是我们更进一步,优化目标是 γ γ γ的话不太好操作,我们对其进行了函数间隔和几何间隔的变换,得到了上面的改写式,为了消去目标中的 γ ∧ γ_{∧} γ∧,我们又设法使函数间隔变为1,因为修改函数间隔并不影响超平面,也不影响几何间隔。
一次迭代的具体办法是这样的,首先我们拿到了支持向量的几何间隔,然后根据几何间隔和函数间隔的转化公式先将函数间隔转移到公式的左边,所以就变成了:
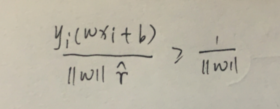
这里有个细节,我们先计算 y i ( w x x i + b ) / γ ∧ y_{i}(wx_{xi}+b)/γ_{∧} yi(wxxi+b)/γ∧,如此一来,w的值就变化了,我们使用这个变化了的值再计算 y i ( w x x i + b ) / ∣ ∣ w ∣ ∣ y_{i}(wx_{xi}+b)/||w|| yi(wxxi+b)/∣∣w∣∣式子中的分母,这样得到的这个式子的值依然表示的是某个样本到超平面的几何间隔,这样计算是不会影响几何间隔的。你把我上面在间隔小节中举的例子数值带进来你发现左式是不变的,也就是说我们对w和b等比例缩放 γ ∧ γ_{∧} γ∧倍,样本的几何间隔是不变化的,如果换成函数间隔,不除以分母的 ∣ ∣ w 变 化 后 的 ∣ ∣ ||w_{变化后的}|| ∣∣w变化后的∣∣的话,函数间隔就莫名其妙的变化了,可是你超平面没变化,这就给了机器钻空子的机会。此时你看上式的右式:
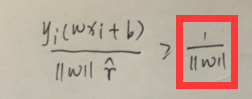
很完美,正好等于我们的优化目标,
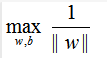
意思就是说,我们每个样本的几何距离要大于等于 1 / ∣ ∣ w ∣ ∣ 1/||w|| 1/∣∣w∣∣,同时要尽可能的扩大 1 / ∣ ∣ w ∣ ∣ 1/||w|| 1/∣∣w∣∣,此时 1 / ∣ ∣ w ∣ ∣ 1/||w|| 1/∣∣w∣∣就是几何距离,因为函数间隔已经是1了,所以上式没有一点问题,经过了这一步之后的式子我写一下:

然后同时把分母的 ∣ ∣ w 变 ∣ ∣ ||w_{变}|| ∣∣w变∣∣约去就好了,后面就迎刃而解了。这就是比较不透明的地方,我又重新梳理了一下。
最终,改写为一个凸二次规划问题。
求解凸函数优化问题
- 这部分内容就需要用到前面学过的对偶问题和KKT条件和拉格朗日乘数法了。
- 下面是求解过程:

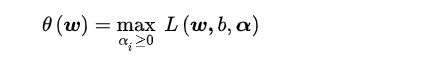





现在我们的优化问题变成了如上的形式。对于这个问题,我们有更高效的优化算法,即序列最小优化(SMO)算法。这里暂时不展开关于使用SMO算法求解以上优化问题的细节,下一篇文章再加以详细推导。
另外补充:

=1其实意思就是已经对函数间隔进行了放缩处理,两侧同除以γ,不影响超平面位置,不影响几何间隔,没什么损失。
















 2305
2305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











