







 本文详细探讨了KNN、NB和SVM三种机器学习算法在鸢尾花分类任务中的应用。通过模型搭建、调优和比较,发现KNN在使用曼哈顿距离和适当k值时表现良好,NB的GaussianNB变体在处理数据时取得优异效果,而SVM的线性核函数结合合适参数也能达到高准确率。三种算法各有优势,适用于不同的场景。
本文详细探讨了KNN、NB和SVM三种机器学习算法在鸢尾花分类任务中的应用。通过模型搭建、调优和比较,发现KNN在使用曼哈顿距离和适当k值时表现良好,NB的GaussianNB变体在处理数据时取得优异效果,而SVM的线性核函数结合合适参数也能达到高准确率。三种算法各有优势,适用于不同的场景。
KNN、NB、SVM实现鸢尾花分类
1. 选题目的与意义
本实验旨在使用KNN、NB、SVM三种算法实现鸢尾花的分类并尽可能提高分类结果的正确率。
通过对该选题的研究,我们可以深入理解和掌握KNN算法、NB算法、SVM算法的原理、构建过程以及分类机制,提升综合素养;同时,用机器学习实现鸢尾花分类对植物学和相关领域的研究也大有益处。
2. 主要研究内容
2.1 KNN算法
-
KNN算法的基本步骤
- 计算距离:对于给定数据集中的每一个数据点,计算其与待分类数据点的距离(如欧氏距离、曼哈顿距离等)
- 基于计算出的距离,找出与待分类数据点最近的k个数据点
- 根据这k个近邻的类别,通过多数投票(majority voting)的方式来预测待分类数据点的类别。

-
KNN算法的关键参数
- k值的选择:
- 较小的k值可能导致过拟合(即模型对训练数据过于敏感)
- 较大的k值可能导致欠拟合(即模型过于简单,无法捕捉到数据的细微变化)
- 在实际应用中,通常通过交叉验证等方法来确定最优的k值
- 距离度量方法
- 欧氏距离
- 曼哈顿距离
- 切比雪夫距离
- 不同的距离度量方法可能适用于不同的数据集和问题:
- k值的选择:
-
KNN算法的优缺点
- 优点:
- 原理简单,易于理解和实现
- 无需估计参数,无需训练
- 适合对稀有事件进行分类
- 缺点:
- 当数据集很大时,计算量大,存储开销大
- 对数据的局部结构非常敏感
- 在决策分类时,k值的选取对结果的影响很大
- 可解释性较差,无法给出像决策树那样的规则
- 优点:
-
KNN算法的应用场景
- KNN算法由于其简单性和有效性,在许多领域都有广泛的应用,如文本分类、图像识别、推荐系统等
- 然而,由于其计算复杂度和对局部结构的敏感性,KNN算法可能不适用于大规模数据集或高维数据集
- 在这些情况下,可能需要使用更复杂的机器学习算法或降维技术来处理数据
2.2 NB算法
朴素贝叶斯算法(Naive Bayes Algorithm)是一种基于贝叶斯定理与特征条件独立假设的分类方法。该算法假设给定目标值时,各个特征之间相互独立。朴素贝叶斯算法通过训练数据集学习联合概率分布,并基于此模型,对给定的输入实例,利用贝叶斯定理求出后验概率最大的输出。
具体来说,朴素贝叶斯算法的核心思想是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
-
NB算法的主要步骤
- 学习训练数据集中特征属性和输出之间的关系,也就是学习先验概率和条件概率:
- 先验概率:P(Y=c),表示样本空间中各个类别的概率,可以通过各类样本出现的频率来进行估计
- 条件概率:P(X=x|Y=c),表示在类别c下,特征X取值为x的概率
- 利用贝叶斯定理,根据先验概率和条件概率计算后验概率
- 后验概率:P(Y=c|X=x),表示给定样本特征X取值x的条件下,输出Y取值c的概率
- 使用贝叶斯公式计算后验概率,即P(Y=c|X=x) = (P(X=x|Y=c) * P(Y=c)) / P(X=x)
- 选择具有最大后验概率的类别作为最终的分类结果。
- 学习训练数据集中特征属性和输出之间的关系,也就是学习先验概率和条件概率:
-
NB算法的分类
- 高斯朴素贝叶斯(Gaussian Naive Bayes):更适合于连续数值型的数据集,特别是符合正态分布的数据集。高斯朴素贝叶斯假设特征值符合高斯分布(正态分布),因此在处理连续数值型数据时表现良好
- 多项式朴素贝叶斯(Multinomial Naive Bayes):更适合于计数类型的数据集,即非负、离散数值的数据集。多项式朴素贝叶斯假设特征是由一个简单的多项式分布生成的,通常用于文本分类等任务,其中特征表示的是次数,例如某个词语在文档中出现的次数
- 伯努利朴素贝叶斯(Bernoulli Naive Bayes):适合于二项式分布的数据集,通常用于处理二元特征,即特征只有0和1两种取值。伯努利朴素贝叶斯假设特征服从伯努利分布,即每个特征都是二元的,并且这些特征之间是相互独立的。
-
NB算法的优缺点
- 优点:
- 逻辑简单且稳定,对于不同类型的数据集不会呈现出太大的差异性
- 所需估计的参数很少,对缺失数据不太敏感
- 在数据集较大的情况下,朴素贝叶斯分类通常能表现出较高的准确率
- 缺点:
- 条件独立性假设在实际应用中往往不成立,这可能会影响分类的准确性
- 需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳
- 分类决策存在一定的错误率
- 优点:
-
NB算法的应用场景
- 朴素贝叶斯算法在多个领域都有广泛的应用场景,主要包括:文本分类、多类别分类、实时分类、高维数据、弱相关特征、信息检索等等
- 总的来说,朴素贝叶斯算法因其简单、高效且易于实现的特性,在多个领域都有广泛的应用
- 然而,需要注意的是,该算法假设特征之间独立,这在某些情况下可能不符合实际,因此在使用时需要谨慎考虑数据的特性
2.3 SVM算法
- SVM算法的主要步骤
- 首先,需要一个包含特征和目标变量(即标签)的数据集;这个数据集将被用于训练SVM模型
- 初始化模型参数:在SVM中,你需要设置一些参数,如核函数(例如线性核、多项式核、径向基函数核等)、惩罚参数C(控制对错误分类的惩罚程度)等;这些参数会影响模型的训练过程和结果
- 在训练过程中,SVM会尝试找到一个最优的超平面,这个超平面能够将数据集中的样本划分为两类(对于二分类问题),并且使得这两类样本到超平面的距离最大化。这个超平面被称为决策边界,而距离决策边界最近的样本点被称为支持向量。在计算过程中,SVM可能会使用核技巧将原始输入空间中的非线性问题转化为某个高维特征空间中的线性问题。此外,SVM的训练过程可以转化为一个优化问题,即最小化一个目标函数,同时满足一些约束条件。这个目标函数通常是一个二次规划问题,可以使用一些优化算法(如序列最小优化算法)来求解
- 在模型训练完成后,你可以使用它来对新的样本进行分类。对于给定的新样本,SVM会计算该样本到决策边界的距离,并根据这个距离的符号来判断样本的类别(对于二分类问题)
- 在某些情况下,你可能希望可视化模型的决策边界以更好地理解模型的性能;这可以通过在二维或三维空间中绘制决策边界来实现
- SVM算法的关键参数
- C(惩罚系数):
- C是误差项的惩罚系数,用于控制对误分类样本的惩罚程度
- C值越大,对误分类的惩罚越重,模型的复杂度也会相应增加
- C值越小,对误分类的惩罚越轻,模型的复杂度也会相应降低
- 选择合适的C值对于模型的性能至关重要
- 核函数的选择:
- 线性核(Linear Kernel):不需要额外的参数
- 多项式核(Polynomial Kernel):有两个主要参数,即多项式的阶数(degree)和常数项(coef0);阶数决定了多项式的最高次数,而常数项则是多项式中的常数项
- RBF核(Radial Basis Function Kernel)(也称为高斯核函数):一个关键参数gamma,决定了数据映射到新的特征空间后的分布。gamma值越大,支持向量越少,决策边界越复杂;gamma值越小,支持向量越多,决策边界越平滑)、Sigmoid核(两个主要参数gamma和coef0,其中gamma与RBF核函数中的意义相同,而coef0则是sigmoid函数中的偏置项)
- C(惩罚系数):
- SVM算法的优缺点
- 优点:
- 高维处理能力
- 避免局部最优解
- 泛化能力强
- 适用于多种数据类型
- 记忆资源占用少
- 缺点:
- 对参数和核函数选择敏感
- 计算复杂度高
- 对缺失数据敏感
- 不适合大规模训练样本
- 多分类问题处理复杂
- 优点:
- SVM算法的应用场景
- SVM(支持向量机)算法的应用场景非常广泛,由于其出色的分类性能和泛化能力,它在许多领域都有成功的应用
- 以下是一些SVM算法常见的应用场景:文本分类(情感分析、垃圾邮件检测、主题分类)、图像识别(人脸识别、手写数字识别、物体检测)、生物信息学(基因表达数据分析、蛋白质结构预测、疾病预测和诊断)、金融预测(股票价格预测、信用评分、市场趋势分析)、网络安全(入侵检测、恶意软件检测)等等
- 总之,SVM算法凭借其出色的分类性能和泛化能力,在多个领域都有广泛的应用
- 然而,在选择是否使用SVM时,需要根据具体问题的特点和数据特性进行综合考虑。
3. 算法设计
3.1 数据分析
-
鸢尾花数据集基本介绍

- 著名的Iris数据库,由R.A. Fisher首次使用,数据集被获取来自Fisher的论文
- 样本总量:150(每个类别50个)
- 特征值:
- sepal length(萼片长度,单位cm)
- sepal width(萼片宽度,单位cm)
- petal length(花瓣长度,单位cm)
- petal width(花瓣宽度,单位cm)
- 标签值:Iris-Setosa,Iris-Versicolour,Iris-Virginica
- 缺失数据:无缺失数据
- 汇总统计:下图分别为四个属性值的最大值、最小值、平均值、方差、类相关性
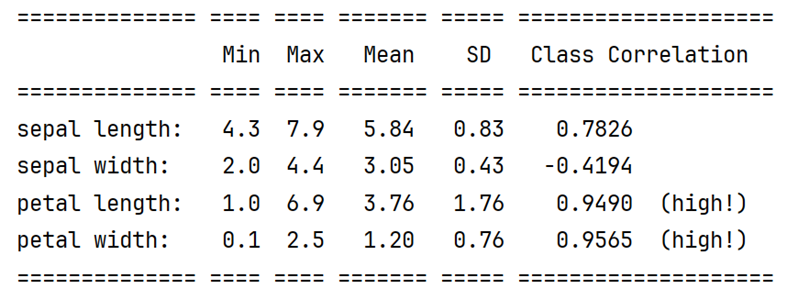
-
样本标签值分布
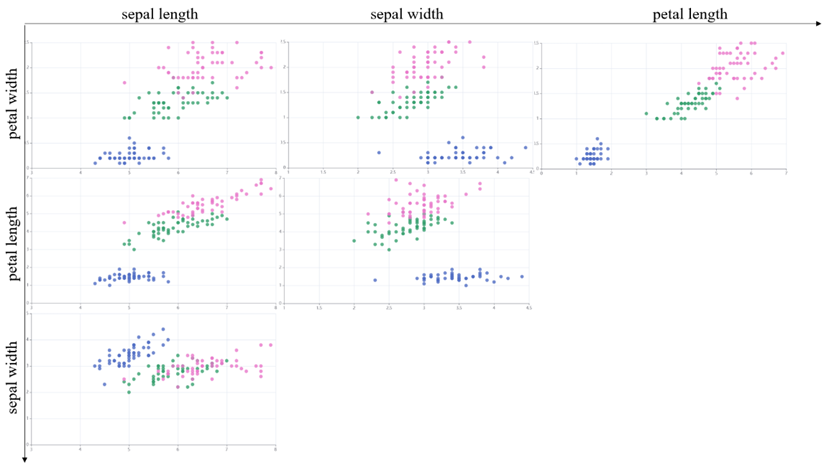
图中展示了鸢尾花数据集的不同维度特征: “sepal length”(花萼长度)、“sepal width”(花萼宽度)和“petal length”(花瓣长度)
不同颜色的点代表了不同的类别:Setosa、Versicolour和Virginica
通过观察散点图,我们可以初步了解各个特征之间的分布关系
在这些散点图中存在明显的聚类或分离现象,这有助于我们识别不同类别之间的潜在模式或边界 -
样本特征值分布
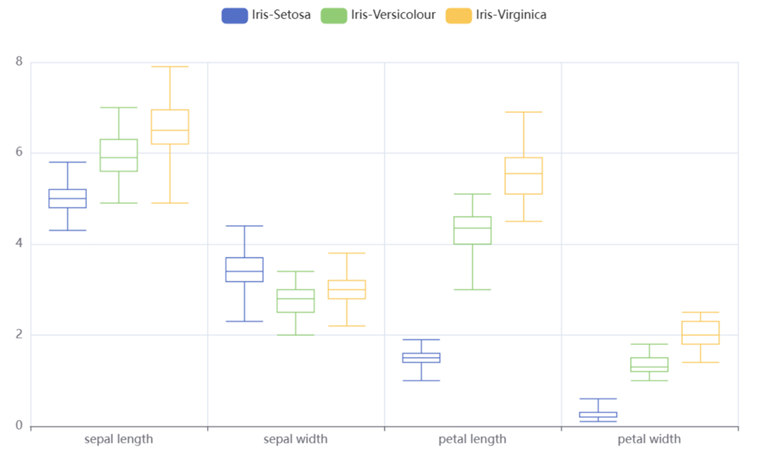
箱线图能够清晰地展示数据的分布,包括上四分位数(Q3)、中位数(Q2)、下四分位数(Q1)、最大值(非异常值中的最大值)和最小值(非异常值中的最小值),这些信息可以帮助我们了解数据在各个特征上的分散程度
我们可以也比较Iris Setosa、Iris Versicolor和Iris Virginica三种鸢尾花在花瓣长度、花瓣宽度、花萼长度和花萼宽度这四个特征上的数据分布
通过观察箱线图的形状,我们可以判断数据分布的对称性:如果中位数位于箱子的中心位置,且箱子两边(即Q1到中位数和中位数到Q3)的长度相近,那么数据分布可能是对称的 -
相关性热力图
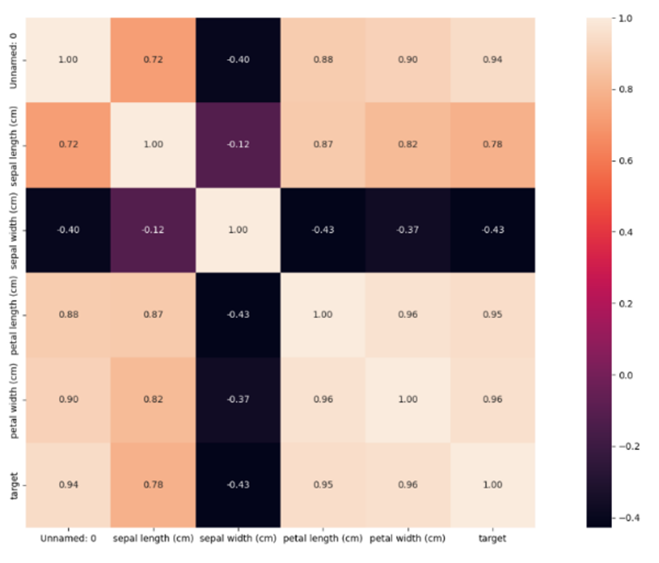
热力图中的每个方块代表两个属性之间的相关性
颜色深浅(从浅黄色到深紫色)反映了相关性的强度和方向
浅色通常表示高相关性(无论是正相关还是负相关),而深色表示低相关性或没有相关性
3.2 KNN算法
3.2.1 模型搭建
- 加载鸢尾花数据集
- 划分训练集和测试集
- 训练KNN分类器
- 使用分类器进行预测
- 结果评估
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
def knn_iris_classify( x, y, testSize=0.3, k=3, trainWay='euclidean'):
"""
使用KNN算法实现鸢尾花分类
:param x: 鸢尾花数据集的属性值,[[ ] [ ]]
:param y: 鸢尾花数据集的类别,[ ]
:param testSize: 训练集占比, 0.1
:param k: KNN模型的值, 3
:param trainWay: 距离度量的方法,有:'euclidean','manhattan','chebyshev'
:return:控制台输出结果,无返回值
"""
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=testSize, random_state=10)
# 初始化KNN分类器,并指定邻居数为3
knn = KNeighborsClassifier(n_neighbors=k, metric=trainWay)
# 训练KNN分类器
knn.fit(x_train, y_train)
# 使用KNN分类器进行预测
y_pred = knn.predict(x_test)
# 结果评估
print("正确率:", accuracy_score(y_test, y_pred),
" 精确率:", precision_score(y_test, y_pred, average='weighted'),
" 召回率:", recall_score(y_test, y_pred, average='weighted'),
" F1值:", f1_score(y_test, y_pred, average='weighted'))

3.2.2 模型调优:距离度量方式+k值
from knn_iris_classify import knn_iris_classify as knn_iris_classify # 导入上3.2.1的knn_iris_classify函数
from sklearn.datasets import load_iris
def knn_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









