







1.没有Web服务器,我们不需要提HTTP协议
2.没有Web服务器的时候,只能在资源所在的电脑_上,通过浏览器访问资源
3.有了Web服务器,可以为所有电脑提供服务,只要有网络和Web服务器所在的电脑连接,则,都可以访问web资源
4. IP地址分为内网地址和外网地址
酒店的房价电话: 4529 (内网号)
平时使用的电话: 139XXX (外网号)
我们平时的电脑,一般是没有外网地址
即使我们现在使用了Web服务器,也只能在局域网内有效

-
HTTP 是一种纯文本协议,控制信息是纯文本的,但其携带的数据信息不做要求。
传输的信息 = 控制信息+携带的负荷信息
主要格式 HTML,css,js的内容

-
URL属于URI的一种具体实现(Unique Resource Location唯一 资源路径)
一个完整的URL, 一定描述网络.上的唯一的一个资源的
URL 不仅仅可以服务于HTTP协议

URL最关键的四个部分:
- 域名/IP
- 端口号
- 带层次的路径
- 查询字符串 query string
http://web服务器所在/
web服务器所在= web服务器所在的主机+ web服务器所占用的端口:8080
ip地址: 192.168.1.5 / 127.0.0.1
域名: www.baidu.com / www.qq.com
当Web服务器占用的是:80时,由于HTTP协议规定的默认端口就是:80,所以,省略端口信息
192.168.1.5:80 <=> 192.168.1.5

网络的规定:任意主机在网络上(同一网络),一定是有一个唯一的 ip地址绑定的(酒店的房间都有唯一的一 个房间号)
号码不方便记忆,所以一般会起一些方便记忆的名称(西安厅、北京厅、华清池厅…同理表现为域名(domain)
www.baidu.com / www.qq.com => 20.135.48.9/ 10.17.22.24
背后有个DNS (Domain Name Service)会帮你把域名解析成ip
查询字符串(query string)
跟在路径后边,以问号开头(?),后边是一组 key=value的形式,之间用and符(&)分割
/blog/article.html 不带query string
/blog/article.html?id=1 带一个kv的query string
/blog/article.html?id= 1&name=2 带两个kv
/blog/article.html?id=1 &name= 2&age=3 kv 没有任何规定
主要应用于动态资源请求,资源固定,但内容不固定
#跟一个id(了解即可)
片段标识符(segment)
用来在同一资源上,定位当前显示位置的
https://docs.oracle.com/javase/8/docs/api/java/util/Deque.html#addFirst-E-
展示该资源的哪个位置
完整的URL由:
1.协议号(http://)
2.定位主机= ip/域名+端口(其中,端口可以省略)
3.路径(/index.* 可以省略,写作/)
4.查询字符串
5.片段标识符
省略版本的URL
1.省略协议号 ://www.baidu.com/
http://192.168.1 .5:8080/blog/index.html 当前资源是 http 当前资源用https
点击<a href= "//192.168.1.7:8080/no-such-file">... </a>
http://192.168.1.7:8080/no-such-file 所以新的请求也是http 也会 是https
在http下点击省略协议号的,新的请求也会是http,https同理
2.省略协议号+ web服务器地址
http://192.168.1.5:8080/blog/index.html
<a href= */no-such.html">点击</a>
访问当前资源所在web服务器下的新的路径的资源
http://192.168.1.5:8080/no-such.html
绝对路径(absolute path) vs相对路径(relative path)
背景知识:到目前为止的所有电脑,它的文件系统都是按照树形结构来组织文件的

其中web服务器,维护资源时,也是同理,只是以webroot作为资源树的整体的根

在这棵上定位某个资源:
数据结构的视角:从根出发,写一条路径(path) ,定位唯一的树的结点

/blog/index.html 绝对路径
从树的根结点出发,进行路径的描述,就是绝对路径
特点:无论“我”身处何处, 一个资源的绝对路径是唯一的
相对路径




URL总结:
1.完整
其中,协议号、web服务器地址、路径不能没有的
查询字符串、片段标识符可以没有
query string: ?k1 =v1 &k2=v2&k3=v3
2.不完整
1)可以省略协议号(跟着当前资源的协议走)
2)可以省略协议号+ web服务器地址(跟着当前资源的协议+ web服务器地址走)
3.绝对路径vs相对路径
绝对路径:从根开始的路径(/ 开头)
相对路径:从当前位置开始的路径(不以/开头)
1)根的位置
2)当前位置
3)对于.和…的理解
URL中的编码问题:由于URL中能出现的字符是有限的,所以,当出现URL中不允许出现的字符时,会被URL编码
URL编码(URL Encode)和URL解码(URL Decode)



请求方法

区别:
!语义上的不同的! GET:获取 POST:提交
由于语义上有区别,所以表现在很多现象上有区别:
1. GET请求不携带请求体(正文)的; POST 请求允许携带请求体,但是否携带看具体情况
2. GET请求具备幂等性; POST请求不具备幂等性
GET想象成SELECT操作; POST 想象成INSERT操作。
幂等性:假设没有其他第三方在动服务器资源的前提下:
GET请求,即使发起多次,得到的结果应该是完全一致的
POST请求,第二次请求,可能得到和第一次请求不同的结果
3. GET请求是缓存友好的,POST请求不允许缓存



响应(Response) :服务器应答哪些信息比较合适?
1.协议版本
2.本次请求的结果(成功、失败(具体的失败细节))
3.本次响应的元信息:响应头
4.响应的资源内容(红楼梦正文) :响应体/正文

状态码和状态描述

hhhhhhhhhhhhhh

重要的几个:
- 200 OK 成功
- 404 Not Found 请求的资源不存在
- 500 Internal Server Error 动态资源,由于我们的Java代码异常,所有tomcat报500
请求 /响应头
content-***:用来描述正文的元信息 【请求/响应】
content-type:正文的类型 (浏览器根据content-type决定如何处理资源)
常见的content-type:(具体的搜索MIME-Type)
text/...肯定是文本, 具体是什么类型的文本,看后边的类型
text/html:文本+ html格式
text/css :文本+ Css格式
text/plain :文本+纯文本信息(想象txt文件)
application/...肯定是应用(大部分现在也是文本)
application/javascript: js 应用(js 文件)
application/json: 结构化的数据格式
image/...
肯定是图片
image/jpeg jpg格式的图片
image/png png
content-length:正文有多长:字节数

响应总结
- 响应的格式
响应行(协议号+状态码+状态描述)
响应头(K-V …直到空行)
正文(不规定)
2.状态码
1)总览 1XX 2XX 3XX 4XX 5XX
2)最常见的三种含义200、404、 500
3.常见头信息: Content-Type
text/html、text/ plain、text/Css ; charset=utf-8
application/javascript、application/json
总结
HTTP知识点浮现的逻辑:
必须要有Web服务器,才能让网络上的其他浏览器也能访问自己的web资源,通信使用HTTP协议
HTTP协议:请求-响应周期:只能访问一个web资源
浏览器拿到某个资源(特指html资源后), 通过该资源的内容,会自动发起其他关联资源的请求
<link href.=..">
<script src=" .> </script>
<img src=" .>
或者,用户点击页面上的某些位置,浏览器也会对新的资源发起请求
<a href.=..">
< form action=".." >
其中: form表单的method方法,决定了发起的get还是post请求,其他的请求都是发起get请求
URL的知识点: url 的格式、url 编码、绝对路径Vs相对路径
请求:格式+方法(GET VS POST)
响应:格式+状态+ Content-Type




一个HTTP请求可以认为分成4个部分:
- 首行
- 请求头(header)
- 空行
- 正文(body)
如果是GET请求,没有body
如果是POST请求,一般有body
GET和POST的典型区别
这里的差别并没有本质区别,在大部分场景下,两者都可以相互代替,但是在使用习惯上,还是有很大差别。
- GET也可以给服务器转递一些信息,GET传递的信息一般都放在query string,POST传递消息通过body
- 语义上的差别:GET一般用于从服务器获取数据;POST一般用于给服务器提交数据。
- GET通常会被设计成幂等的,POST不要求幂等。
幂等:每次相同的输入,得到的结果也是确定的稳定的 - GET可以被缓存,POST一般不能被缓存。
Host:
描述了服务器所在的地址和端口。这里用于描述最终要访问的目标。
内容大概率和URL中一样,也有可能不一样。
Content-Length:body中的数据长度
Content-Type:请求的body中的数据格式
User Agent:简称UA,描述了浏览器和操作系统的版本
Referer:当前页面的”来源“,从哪个页面跳转到该页面的
Cookie:浏览器给网页提供的本地存储数据的机制。
cookie浏览器对于访问硬盘做出了明确的限制。cookie就是通过键值对的方式组织数据的。
cookie中的数据来自服务器,服务器会通过HTTP响应的报头部分(set-cookie字段)服务器来决定浏览器的cookie要存什么
cookie可以认为是存在于浏览器中,存在于硬盘的。在存的时候,是按照浏览器+域名维度来细分的。不同的浏览器,各自存各自的cookie,同一个浏览器不同的域名,对应不同的cookie。
cookie要回到服务器去。客户端同一时刻是有很多的。客户端这边就会通过 Cookie 来保存当前用户使用中间状态当客户端访问浏览器的时候, 就会自动的把 Cookie 的内容带入到请求中,服务器就能够知道现在客户端是啥样子了
常见状态码:
200:成功
404:Not Found 访问资源不存在,在服务器上没找到
403:Forbidden 拒绝被访问(没有权限)
302:Move Temporarily 重定向(类型呼叫转移),通过location属性描述要跳转到哪个新的地址。
500:服务器内部错误 (服务器代码抛异常)
504:gateway timeout 响应超时。
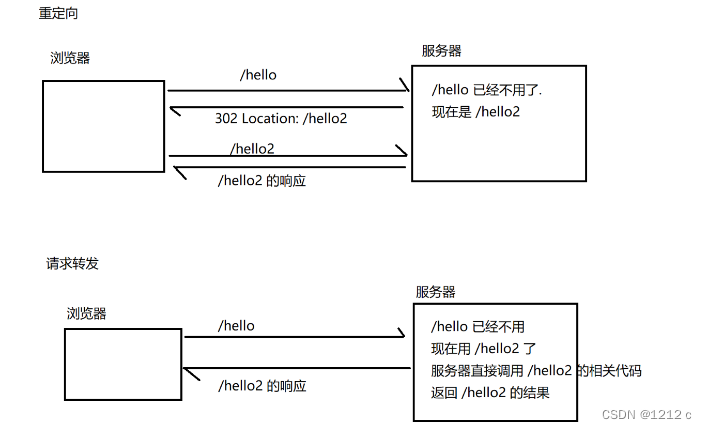
重定向,可以重定向到外部资源的(跳转到别的网站)
请求转发只能该服务器内部的资源之间转发,少了一次交互,更高效
















 2000
2000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









