







1. 混淆矩阵
混淆矩阵是二分类问题的多维衡量指标体系,在样本不平衡时极其有用。在混淆矩阵中,我们将少数类认为是正例,多数类认为是负例。在决策树,随机森林这些普通的分类算法里,即是说少数类是1,多数类是0。在SVM里,就是说少数类是1,多数类是-1。普通的混淆矩阵,一般使用{0,1}来表示。

- 混淆矩阵中,永远是真实值在前,预测值在后。其实可以很容易看出,11和00的对角线就是全部预测正确的,01和10的对角线就是全部预测错误的。基于混淆矩阵,我们有六个不同的模型评估指标,这些评估指标的范围都在[0,1]之间,所有以11和00为分子的指标都是越接近1越好,所以以01和10为分子的指标都是越接近0越好。对于所有的指标,我们用橙色表示分母,用绿色表示分子,则我们有:
1.1 准确率(Accuracy)
- 为了方便作对比,我们先看一下熟知的准确率是什么意思:就是预测正确的占总样本的比例。一般在样本不平衡问题下,不使用这个评估指标。可以想象一下,假设我们有999个负例,1个正例,假设预测正确了900个样本(包括那个正例),则准确率为90%,这就一定很好么,很显然模型对正例的预测是很差的,模型只是对学习负例有很好的表现,所以这个评价指标在样本不平衡时不能使用。


1.2 精确度/查准率(Precision)
注意:精确度中这个对象指的是少数类(好瓜)的精确度,在下面要介绍的查全率中,针对的对象还是少数类,也即少数类的精确度和少数类的查全率
- 精确度表示在我们预测为正例的样本中,有多少被真正的预测对了。比如我们预测有60个正例,其中40个是真正的正例,20个是负例,即被预测错了。那么准确率就是40/60.
- 精确度又叫查准率。精确度是”将多数类判错后所需付出成本“的衡量。
- 当每一次将多数类判断错误的成本非常高昂的时候(比如大众召回车辆的例子),我们会追求高精确度。精确度越低,我们对多数类的判断就会越错误。当然了,如果我们的目标是不计一切代价捕获少数类,那我们并不在意精确度。

1.3 召回率/查全率(Recall)
- 描述在所有正例中,有多少被我们预测出来了。比如我们原来数据集中有60个正例,其中有40个被我们预测出来了(11),剩下的20个就没有被真正的预测出来(预测为正例实际为负例)那么Recall=40/60.
- 召回率越高,代表我们尽量捕捉出了越多的少数类,召回率越低,代表我们没有捕捉出足够的少数类。
- 如果我们希望不计一切代价,找出少数类(比如找出潜在犯罪者的例子),那我们就会追求高召回率,相反如果我们的目标不是尽量捕获少数类,那我们就不需要在意召回率。

1.4 F1-measure(F-score)
- 为了同时兼顾精确度和召回率,我们创造了两者的调和平均数作为考量两者平衡的综合性指标,称之为F1-score。两个数之间的调和平均倾向于靠近两个数中比较小的那一个数,因此我们追求尽量高的F1-measure,能够保证我们的精确度和召回率都比较高。F1 measure在[0,1]之间分布,越接近1越好。
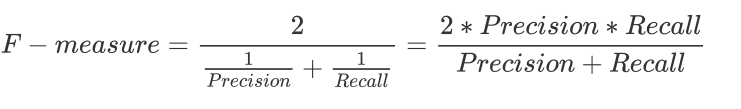
2. 查准率和查全率之间的矛盾
- 先说结果:并不是绝对的矛盾,而是实际应用中经常会发生这样的情况。
个人理解:
- Recall提高,我们可以认为我们降低了阈值,从而可以找出更多的潜在正例。例如,假设原本有100个正例,阈值为0.5,此时有70个正例被预测出来了,剩下的30个正例预测成了负例,这可能是阈值设置的过大,那么我们就可以减小阈值,例如减小到0.3,可能把90个正例都找出来了。
- 相反,我们减小阈值的同时分析查准率,直接考虑极端情况,置阈值为0.1,这时候,我们把大部分的样本都预测成了正例,负例极大部分都预测错误了,这时候查准率会大大下降。
- 我们一般认为,0.5是个分界线,大于0.5偏向正例(意味着少数处于小于0.5);小于0.5偏向负例(意味着少数处理大于0.5).当我们要追求那些少数的时候,必然会对另一端产生影响,这就是矛盾的分析。
- 所以说,这两个评估指标是相对矛盾的。
3. sklearn中的混淆矩阵及一些API

4. ROC曲线
4.1 假正率
- 假正率表示在所有的负例(多数类)中,有多少被我们预测错了。

4.2 假正例的应用:ROC曲线
- 假正率有一个非常重要的应用:我们在追求较高的Recall的时候,Precision会下降,就是说随着更多的少数类被捕捉出来,会有更多的多数类被判断错误,但我们很好奇,随着Recall的逐渐增加,模型将多数类判断错误的能力如何变化呢?我们希望理解,我每判断正确一个少数类,就有多少个多数类会被判断错误。假正率正好可以帮助我们衡量这个能力的变化。相对的,Precision无法判断这些判断错误的多数类在全部多数类中究竟占多大的比例,所以无法在提升Recall的过程中也顾及到模型整体的Accuracy。因此,我们可以使用Recall和FPR之间的平衡,来替代Recall和Precision之间的平衡,让我们衡量模型在尽量捕捉少数类的时候,误伤多数类的情况如何变化,这就是我们的ROC曲线衡量的平衡。
- ROC(The Receiver Operating Characteristic Curve),源自二战时期用于敌机检测的雷达信号技术分析。
- ROC评价的就是如何在尽量捕获少数类的同时减少对多数类别的判错

- 黄色线包含的面积就是AUC(Aera under ROC curve)
那么怎么捕捉假正率和Recall之间的平衡呢?

我们希望我们的模型在尽量捕捉少数类的时候能够减少误伤多数类。横坐标是假正率,假正率越大,表示被误伤的多数类越多,所以我们希望我们的假正率不要太大,同时希望Recall尽量的大,也就是说如果我们画出来的ROC曲线整体在左上角,则表明模型效果是不错的。
当ROC曲线为凹的时候,曲线应该越靠近右下角越好,预测结果与真实结果完全相反,那也不算太糟糕,只需要把数据集的label翻转过来就好了。
最糟糕的情况是,无论曲线是凹的还是凸的,曲线位于图像中间,和虚线非常靠近,这时候就要思考模型的问题了。
我们现在知道了什么样的情况模型的效果是好的,但是我们还没有量化它,这时候AUC曲线就登场了
既然说ROC曲线越靠近左上角越好,那我们就用左上角包围的面积来量化模型的效果。
在sklearn中,我们使用sklearn.metrics.roc_curve来获取假正率FPR、Recall和阈值集合
这里有一个名词叫做”约登指数”,为Recall和FPR差距最大的点对应的阈值

在sklearn中,auc的计算使用:
















 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











