







引出问题
如果机器学习的目标是尽量捕获少数类,那么就不能只看模型准确率,需要一个新的评估指标来判断模型好坏。简单来看,只需要查看模型在少数类上的准确率就好,只要能够将少数类尽量捕捉出来,就能够达到目的。
但是,新问题又出现了,对多数类判断错误后,会需要人工甄别或者更多的业务上的措施来逐一排除判断错误的多数类,这往往伴随着很高的成本。
比如银行在判断《申请信用卡的客户是否会出现违约行为》的时候,如果一个客户被判断为”会违约“,这个客户的信用卡申请就会被驳回,如果为了捕捉出”会违约“的人,大量地将”不会违约“的客户判断为”会违约“的客户,就会有许多无辜的客户申请被驳回。信用卡对银行来说意味着利息收入,而拒绝了许多本来不会违约的客户,对银行来说就是巨大的损失。同理,大众在召回不符合欧盟标准的汽车时,如果为了找到所有不符合标准的汽车,而将一堆本来符合标准了的汽车召回,这个成本是不可估量的。
也就是说,单纯地追求捕捉出少数类,会使成本太高,而不顾及少数类,又无法达成模型的效果。所以,在现实中,往往在寻找捕获少数类的能力和将多数类判错后需要付出的成本的平衡。如果一个模型在能够尽量捕获少数类的情况下,还能够尽量对多数类判断正确,则这个模型就非常优秀了。为了评估这样的能力,我们将引入新的模型评估指标:混淆矩阵。
混淆矩阵
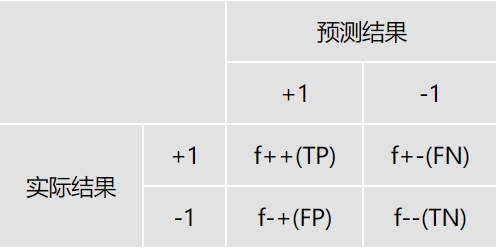
混淆矩阵通常也被称之为”联列表“ 或 ”误差矩阵“,混淆矩阵是二分类问题的多维衡量量指标体系,在样本不平衡时极其有用。
 | or |  |
在描述混淆矩阵,我们经常使用下面的术语。
- 真正例(true positive,TP)或 真正(f+ +),正样本被预测为正的个数
- 伪反例(false negative,FN)或 假负(f+ -),正样本被预测为负的个数
- 伪正例(false positive,FP)或 假正(f- +),负样本被预测为正的个数
- 真反例(true negative,TN)或 真负(f- -),负样本被预测为负的个数
准确率
准确率: 所有预测正确的样本数除以总样本数
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
Accuracy=\frac{TP+TN}{TP+TN+FP+FN}
Accuracy=TP+TN+FP+FNTP+TN
精确度
精确度: 又叫查准率。所有预测结果为1的样例数中,实际为1的样例数所占比重。
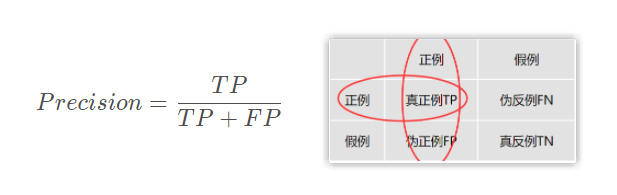
精确度越低,则代表误伤了过多的多数类。精确度是”将多数类判错后所需付出成本“的衡量。
做了样本平衡之后,精确度是下降的。因为很明显,样本平衡之后,有更多的多数类被我们误伤了。精确度可以帮助我们判断,是否每一次对少数类的预测都精确,所以又被称为”查准率“。在现实的样本不平衡例子中,当每一次将多数类判断错误的成本非常高昂的时候(比如大众召回车辆的例子),我们会追求高精确度。精确度越低,我们对多数类的判断就会越错误。当然了,如果我们的目标是不计一切代价捕获少数类,那我们并不在意精确度。
召回率
召回率: 又被称为灵敏度(sensitivity),真正率,查全率,表示所有真实为1的样本中,被我们预测正确的样本所占的比例。

召回率越高,代表我们尽量捕捉出了越多的少数类,召回率越低,代表我们没有捕捉出足够的少数类。
召回率可以帮助判断是否捕捉了全部的少数类,所以又叫做查全率。
如果希望不计一切代价,找出少数类(比如找出潜在犯罪者的例子),就会追求高召回率,相反,如果目标不是尽量捕获少数类,就不需要在意召回率。
可以注意到,召回率和精确度的分子是相同的(都是TP),只是分母不同,而召回率和精确度是此消彼长的,两者之间的平衡代表了捕捉少数类的需求和尽量不要误伤多数类的需求的平衡。究竟要偏向于哪一方,取决于我们的业务需求:究竟是误伤多数类的成本更高,还是无法捕捉少数类的代价更高。
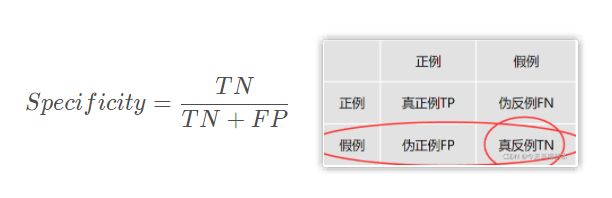
特异度
特异度: 又被称为特异性(specificity),表示所有真实为-1的样本中,被我们预测正确的样本所占的比例。
F指标
F指标: 精确度和召回率的调和均值
F
−
m
e
a
s
u
r
e
=
2
1
P
r
e
c
i
s
i
o
n
+
1
R
e
c
a
l
l
=
2
T
P
2
T
P
+
F
P
+
F
N
F-measure=\frac{2}{ \frac{1}{Precision} + \frac{1}{Recall} }=\frac{2TP}{2TP+FP+FN}
F−measure=Precision1+Recall12=2TP+FP+FN2TP
同时兼顾精确度和召回率,我们创造了两者的调和平均数作为考量量两者平衡的综合性指标,称之为F1 score(F measure)。两个数之间的调和平均倾向于靠近两个数中比较小的那一个数,因此,追求尽量量高的F measure,能够保证精确度和召回率都比较高。F measure在[0,1]之间分布,越接近1越好。
以上四个值都是越接近1越好
ROC曲线
另一个用于度量分类中的非均衡性的工具是接受者操作特征(receiver operating characteristic)曲
线,简称ROC曲线。下图就是AdaBoost病马数据集的ROC曲线。

我们可以看到,ROC曲线的横坐标是 【1-特异度】,纵坐标是【灵感度】也就是召回率。图中还有两条线,一条虚线一条实线。虚线给出的是随机猜测的结果曲线。
在理想的情况下,最佳的分类器应该尽可能地处于左上角,这就意味着分类器在敏感度很高的情况下也有很高的特异度,大家再看一下敏感度和特异度的定义,也就是说,我们在把正样本更多地正确分类的同时也能把负样本更多的正确分类。
AUC面积
对不同的ROC曲线进行比较的一个指标就是曲线下的面积(area under the curve),简称AUC。一个完美分类器的AUC为1.0 ,随机猜测的AUC为0.5,所以我们比较两个模型之间的优劣通常使用虚线和实线之间的面积,面积越大则模型效果越好。
混淆矩阵样例
import pandas as pd
from sklearn import metrics # sklearn中的导入混淆矩阵模块
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 从sklearn库中获取红酒数据集
wine = load_wine()
# 红酒数据集是三分类问题,现在丢掉一部分,将它处理成二分类
x = pd.DataFrame(wine.data,columns=wine.feature_names)
y = pd.DataFrame(wine.target,columns=['lab'])
data = pd.concat([x,y],axis=1)
data = data.iloc[:130,:]
# 划分训练测试集
X_train, X_test, Y_train, Y_test = train_test_split(data.iloc[:,:-1], data.iloc[:,-1], test_size=0.3, random_state=30, stratify=data.iloc[:,-1])
# 训练模型
# model = DecisionTreeClassifier(criterion="entropy", random_state=30, splitter='random')
model = DecisionTreeClassifier(criterion="gini", splitter='best', max_depth=9, random_state=30)
model = model.fit(X_train, Y_train)
# 测试集的预估值
pred = model.predict(X_test)
# 训练集评分
print(model.score(X=X_train, y=Y_train))
print(metrics.accuracy_score(y_true=Y_train, y_pred=model.predict(X_train)))
# 测试集评分
print(model.score(X_test, Y_test))
print(metrics.accuracy_score(Y_test,pred))
print("精确度为: {},\n准确率为: {},\n召回率为: {},\nF-measure为: {}"
.format(metrics.precision_score(Y_test,pred), # Precision
metrics.accuracy_score(Y_test,pred), # accuracy
metrics.recall_score(Y_test,pred), # Recall
metrics.f1_score(Y_test,pred)), # F-measure
)
print('混淆矩阵: ')
print(metrics.confusion_matrix(Y_test,pred))















 3358
3358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









