









写在前面
本博客深度讲解广度优先遍历及其代码实现
1. 广度优先搜索
- 是关于图数据结构的一种算法,它可以回答两个问题:
①从节点A出发,有前往结点B的路径么?
②从节点A出发,前往结点B的哪条路径最短?
2. 预备概念
- 一度关系:A——>B
- 二度关系:A——>B——>C,A与C为二度关系
我们搜索最短路径是按照一度关系优于二度关系以此类推,找到最短路径的。
- 广度有限搜索需要一个队列来存储每次访问结点的信息
3. 举个简单例子
现在假设我们要寻找结点A到结点G的最短路径,考虑下面这张图
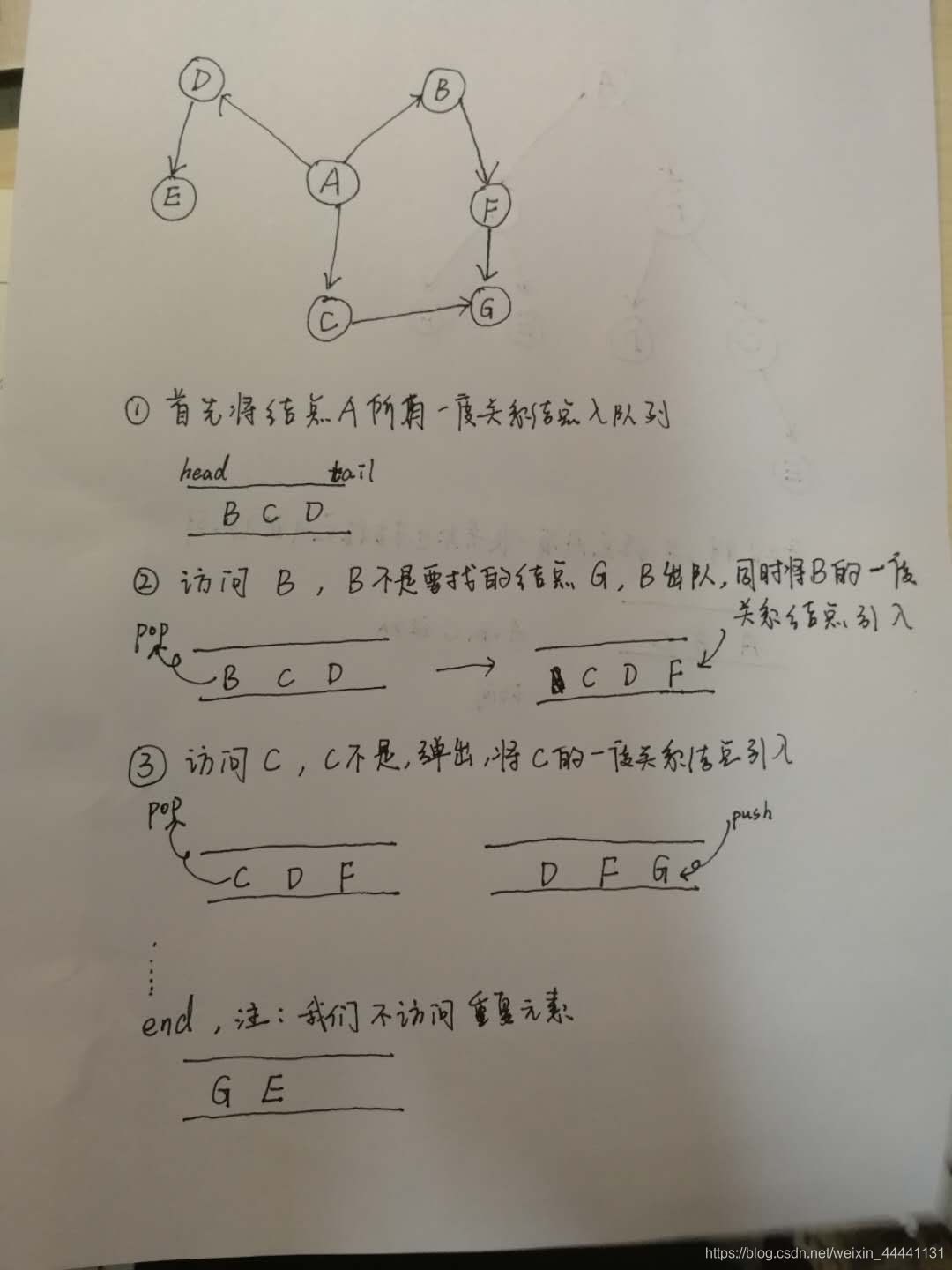
可以看到就是这么简单,运用一个队列来记录访问顺序,我们先访问的永远都是一度关系结点。
4. 代码实现
4.1 如何构建图结构
- 我们使用哈希表来表示图结构,键表示某个结点,值表示该节点对应的一度关系结点
# 构建图结构,value只记录一度关系的结点
graph = {}
graph["A"] = ["B","C","D"]
graph["B"] = ["F"]
graph["C"] = ["G"]
graph["D"] = ["E"]
graph["E"] = []
graph["F"] = ["G"]
graph["G"] = []
- 顺便提一句,键-值对的添加顺序不是很重要,因为散列表是无序的。
4.2 实现算法
def search(name):
flag = 0
search_queue = deque() #创建一个队列
search_queue += graph["A"] # 将起点的一度关系结点加入队列
searched = [] # 记录检查过的人
string = "A" # 记录路径
while search_queue:
node = search_queue.popleft() # 取出队首第一个元素
if node not in searched:
if node == name:
string += "-->" + node
flag = 1
print(string)
return True
else:
string += "-->" + node
search_queue += graph[node] # 不是G,将该节点的一度关系结点加入队列末尾
if flag == 1:
print(string)
else :
print(name,"not in graph")
search('G')
search('k')
# result
A-->B-->C-->D-->F-->G
k not in graph
4.3 运行时间
O(V+E),V表示结点数(因为要将结点加入队列,指的是 加入操作的复杂度),E是边的个数,因为要访问查看当前是否为需要的结点。
总结
为了实现广度优先遍历你需要:
- 一个图
- 一个队列用来存储访问顺序
- 一个数组用来存储已经访问过的元素(我们肯定不希望访问重复的元素)















 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











