






 参加星环科技大数据架构师培训,深入了解大数据平台、容器云操作系统的研发与服务。掌握架构师职责,学习解决方案设计,提升项目管理和风险控制能力。
参加星环科技大数据架构师培训,深入了解大数据平台、容器云操作系统的研发与服务。掌握架构师职责,学习解决方案设计,提升项目管理和风险控制能力。

本篇推文共计1500个字,阅读时间约3分钟。
2020年3月,有幸参与了星环科技大数据架构师的培训认证。在范颖捷老师的授课中,感慨颇多。今天我根据学习到的部分知识谈谈自己的心得体会。
在谈培训心得之前,我得先向大家介绍一下向我提供星环大数据架构师的培训认证的
[星环科技公司]

图片来源:星环科技官网
星环科技是大数据基础平台供应商,专注于提供企业级容器云计算、大数据和人工智能核心平台的研发和服务,打造大数据和人工智能生态的“中国心”。
公司以上海为总部,以北京、广州、多伦多为区域总部,并在南京、郑州、成都设有支持中心,同时在深圳、武汉等地设有办事机构。
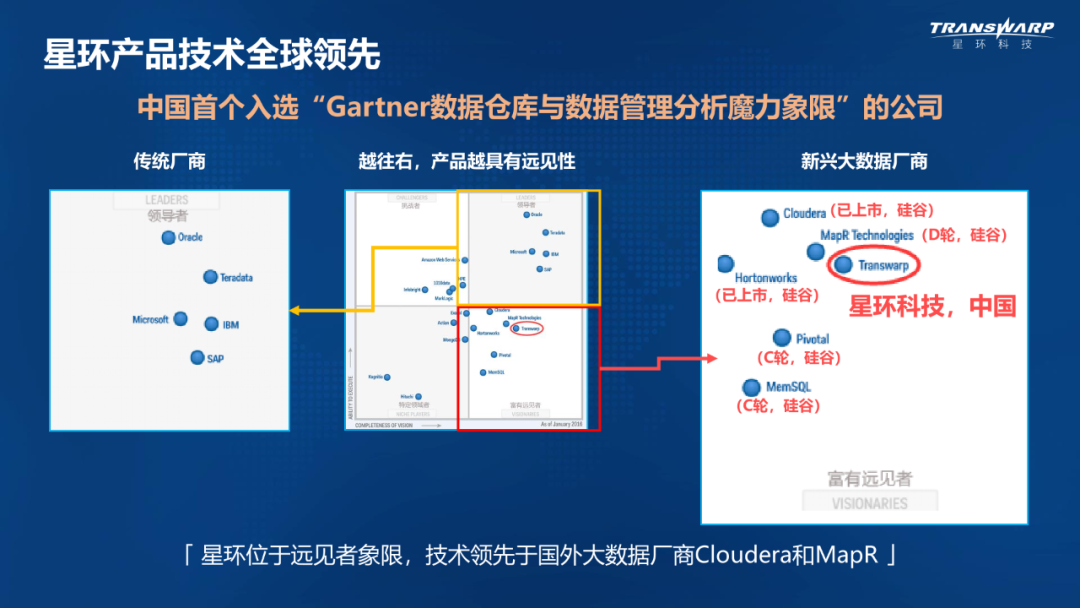
图片来源:星环科技培训官网
经过多年自主研发,星环科技建立了三条产品线:一站式大数据平台Transwarp Data Hub(TDH)、基于容器的云操作系统Transwarp Operating System(TOS)和超融合大数据一体机TxData Appliance,并拥有多项专利技术。
 图片来源:星环科技官网
图片来源:星环科技官网
2016年被Gartner评为全球最具有前瞻性的数据仓库及数据管理解决方案厂商,2017年被IDC评为中国大数据市场领导者。公司产品已经在十多个行业应用落地,是国内落地案例较多的大数据和人工智能平台供应商。
目前星环科技已完成D2轮融资,由腾讯领投。

图片来源:星环科技培训官网

架构师
言归正传,可能很多人知道码农是码代码的程序员,但是对架构师的概念确实一头雾水。
通过这段时间的学习,我了解到架构师这个职业主要工作任务不再是做具体代码编写,而是负责更高层次的开发构架工作。因为一个架构师工作能力的强弱以及专业素养的高低可能决定了整个软件项目的成败,所以作为架构师,他必须对开发技术非常了解,并且需要有良好的组织管理能力以及责任心。
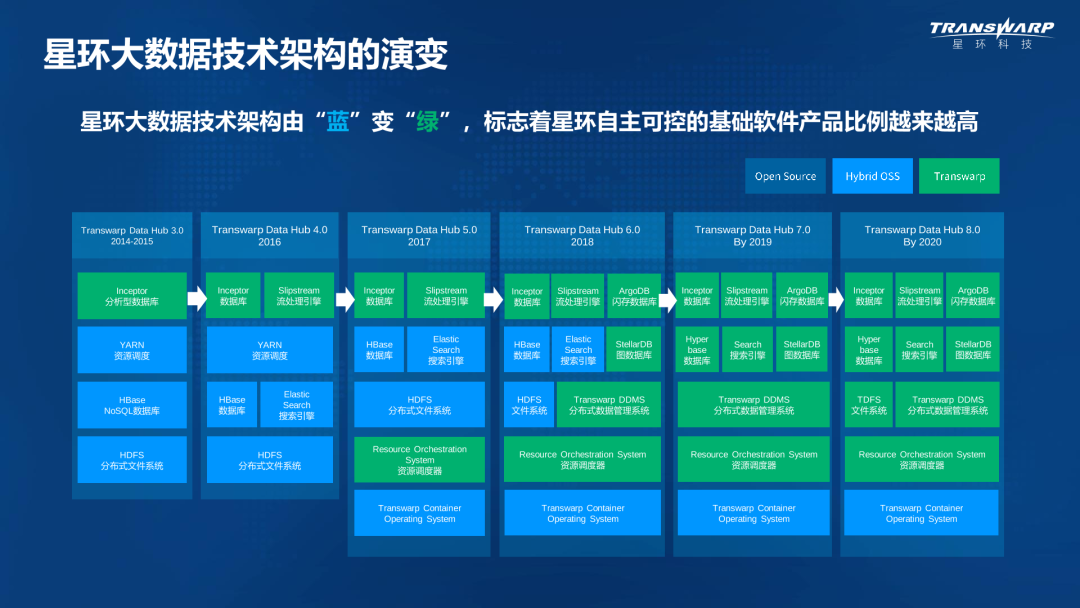
图片来源:星环科技培训官网
培训流程
整个星环大数据架构师的培训认证流程以线上直播的形式,结合实践案例,由浅入深地向我们展示了星环科技针对不同需求而推出的行业解决方案。
如果直播没有听懂的话,还可以登录培训认证官网
http://university.transwarp.cn/
进行回放,这一点对初学者来说很棒。
课程中向我们介绍的行业解决方案中包括:
星环产品体系&一站式大数据平台TDH
星环新一代逻辑数据仓库解决方案
星环高性能数据集市解决方案与典型案例
星环统一架构解决方案
星环智能实时流处理解决方案与典型案例
星环大规模综合搜索解决方案
星环新一代交易型数据库解决方案
星环智能物联解决方案与典型案例
星环实体画像解决方案与典型案例
星环知识图谱解决方案与典型案例
星环数据云解决方案与典型案例
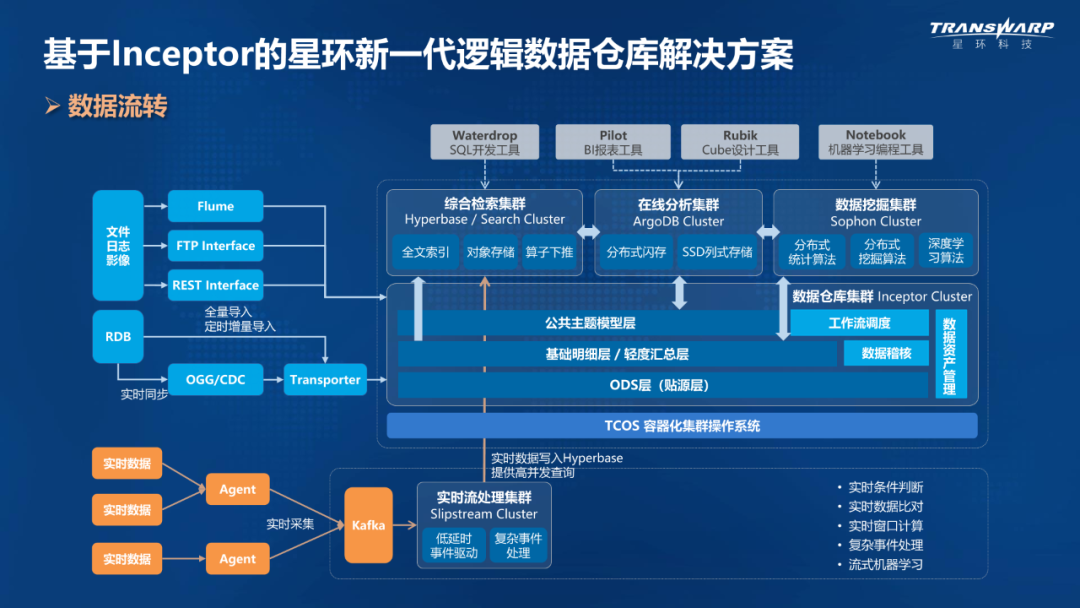
图片来源:星环科技培训官网
虽然初期听起来一头雾水,但是结合实际解决方案案例讲解的时候往往能理解开始的疑惑,加深了自己对这部分知识的理解。

图片来源:星环科技培训官网
课下,同学们的学习热情也很棒,一直会在学习群中交流学习心得,感受其它同学们的学习氛围,我也默默地坚持在学习。
学习完后,我就参加了星环科技提供的线上考试,整场考试时间一共两个小时,题型分为单选,多选,以及简答题。选择题大概20几道,简单题大概有5道。可以说考试难度还是比较大的,非常考验对所学知识和实际案例的理解。希望可以顺利过关。
星环科技大数据架构师的培训除了教会我大数据架构师的知识,整个培训让我明白了三件事情:
架构师是干嘛的?
大数据项目如何根据需求做好解决方案?
作为架构师应该如何推进项目以及把控风险?
架构,越是简单抽象的定义,越是美,越是通用。
小到一个玩具,大到一个国家的运作都可以隐含着这样的内容。
最后由衷感谢星环科技,感谢范颖捷老师为我们提供的这次培训,虽然培训时间较短,但这为我今后的职业生涯规划产生了深远的影响。如果有机会真希望可以去参观星环科技总部,感受数据跳动的魅力。
 图片来源:星环科技官网
图片来源:星环科技官网

往期回顾
武汉加油,中国加油!
欢迎各位读者在下方进行留言
☆ END ☆

你与世界
只差一个
公众号
喜欢本推文的话麻烦你点个“在看”或“分享至朋友圈”

















 1667
1667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









