







注意:
出现:
每个接收器都以 Spark 执行器程序中一个长期运行的任务的形式运行,因此会占据分配给应用的 CPU 核心。此外,还需要有可用的 CPU 核心来处理数据。
解决:
必须至少有和接收器数目相同的核心数,还要加上用来完成计算所需要的核心数(n+1) n为接收器数目,1为机器需要
例如,如果我们想要在流计算应用中运行 10 个接收器,那么至少需要为应用分配 11 个 CPU 核心。所以如果在本地模式运行,不要使用local或者local[1]
1.Socket数据源
在此博客:DStream入门操作
https://blog.csdn.net/weixin_44449054/article/details/114365774
2.文件数据源
2.1 概述
能够读取所有HDFS API兼容的文件系统文件,通过fileStream方法进行读取
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
Spark Streaming 将会监控 dataDirectory 目录并不断处理移动进来的文件,记住目前不支持嵌套目录
文件需要满足条件:
1、文件需要有相同的数据格式
2、文件进入 dataDirectory的方式需要通过移动或者重命名来实现。
3、一旦文件移动进目录,则不能再修改,即便修改了也不会读取新数据。
如果文件比较简单,则可以使用
streamingContext.textFileStream(dataDirectory)方法来读取文件。
注意: 文件流不需要接收器,不需要单独分配CPU核。
2.2 实现
在HDFS上建好目录:hdfs dfs -mkdir /stream-data
需求:
往hadoop目录/stream-data下上传文件(文件内容格式相同),要求实时读取,并将内容累加读取
使用textFileStream()读取hdfs文件
使用updateStateByKey()方法更新streaming信息,
自定义样式函数updateFunc()
def updateFunc(newValues:Seq[Int],runnintCount:Option[Int]):Option[Int] = {
val finalResult = runnintCount.getOrElse(0) + newValues.sum
Option(finalResult)
}
导入jar包:
同:https://blog.csdn.net/weixin_44449054/article/details/114365774
完整代码:
package cn.twy
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingFile {
def updateFunc( newvalue : Seq[Int], runvalue :Option[Int]) :Option[Int] ={
val sumvalue = newvalue.sum + runvalue.getOrElse(0)
Option(sumvalue)
}
def main(args: Array[String]): Unit = {
//获取sparkconf
val sparkConf = new SparkConf().setAppName("StreamingFile").setMaster("local[2]")
//设置日志级别
val sparkContext = new SparkContext(sparkConf)
sparkContext.setLogLevel("WARN")
//获取streamingcontext
val ssc = new StreamingContext(sparkContext,Seconds(5))
//设置sparkStreaming保存目录
ssc.checkpoint("./hdfs-data")
//读取文件
val fileStream = ssc.textFileStream("hdfs://node01:8020/stream-data")
//读取文本进行单词计数
val fileresult = fileStream.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//更新文件的状态,传入一个我们自定义的updateFunction
val overresult = fileresult.updateStateByKey(updateFunc)
overresult.print()
//启动流
ssc.start()
ssc.awaitTermination()
}
}
测试:
启动程序,并向指定目录上传文件
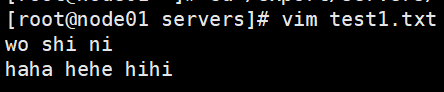


结果:
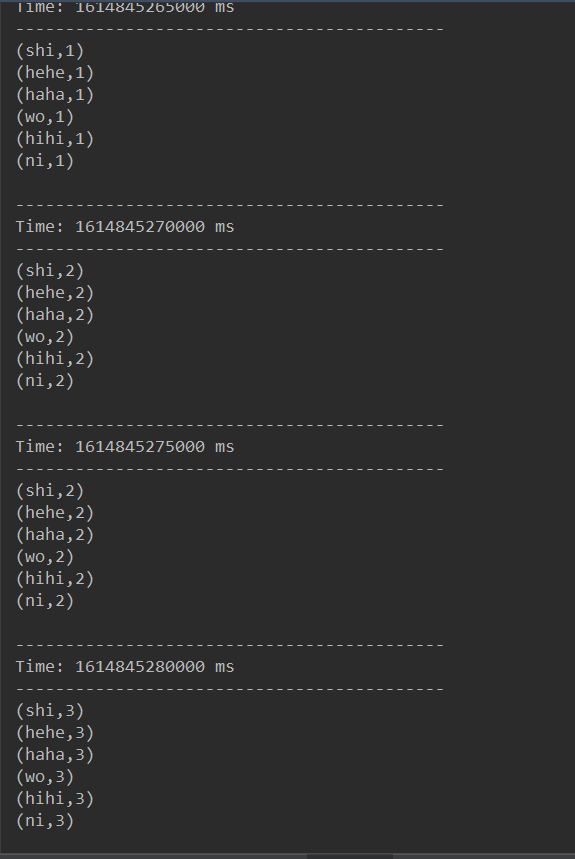
3.自定义数据源
通过继承Receiver,并实现onStart、onStop方法来自定义数据源采集。
需求:
自定义数据源,接收socket收据,并统计每个单词出现的次数
关键:
val customReceiverStream = ssc.receiverStream(new CustomReceiver(host, port))
代码:
package cn.twy
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import java.nio.charset.StandardCharsets
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.receiver.Receiver
class CustomReceiver (host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) {
override def onStart(): Unit = {
new Thread("Socket Receiver") {
override def run() { receive() }
}.start()
}
override def onStop(): Unit = {
}
/** Create a socket connection and receive data until receiver is stopped */
private def receive() {
var socket: Socket = null
var userInput: String = null
try {
socket = new Socket(host, port)
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8))
userInput = reader.readLine()
while(!isStopped && userInput != null) {
// 传送出来
store(userInput)
userInput = reader.readLine()
}
reader.close()
socket.close()
restart("Trying to connect again")
} catch {
case e: java.net.ConnectException =>
restart("Error connecting to " + host + ":" + port, e)
case t: Throwable =>
restart("Error receiving data", t)
}
}
}
object CustomReceiver {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(4))
val lines = ssc.receiverStream(new CustomReceiver("node03", 9999))
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
运行:


4.RDD队列
通过使用streamingContext.queueStream(queueOfRDDs)来创建DStream,每一个推送到这个队列中的RDD,都会作为一个DStream处理。
package cn.twy
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object QueueRdd {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("QueueRdd")
val ssc = new StreamingContext(conf, Seconds(3))
//创建RDD队列
val rddQueue = new mutable.SynchronizedQueue[RDD[Int]]()
// 创建QueueInputDStream
val inputStream = ssc.queueStream(rddQueue)
//处理队列中的RDD数据
val mappedStream = inputStream.map(x => (x % 10, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
//打印结果
reducedStream.print()
//启动计算
ssc.start()
for (i <- 1 to 30) {
rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)
Thread.sleep(2000)
}
}
}
运行:
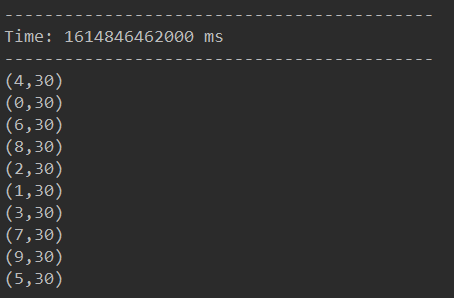















 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









