







字符串方法

缺失数据处理
- 缺失类型
- NaN(not a number)需要处理
- 0,可能是缺失数据,也可能有意义,需要判断后处理
- 处理步骤
- 判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
- 确定NaN处理方式
方法一:删除NaN所在的行列
dropna()
方法二:填充数据
df.fillna(),可填充均值、中位数或0 - 处理为0的数据
当0为无意义数值时,df[df==0]=np.nan,将0用nan替换。统计数据时,NaN不参与计算的,但是0会。
import pandas as pd
import numpy as np
# 判断nan值
d = pd.DataFrame(np.arange(12).reshape(3, 4))
print(d)
d.iloc[1, [2, 0]] = np.nan
print(d)
print(pd.isnull(d))
print(pd.notnull(d))
# 利用nan取值
print(d[pd.notnull(d.iloc[:, 0])]) # 显示第0列,notnull返回True的行
print(pd.notnull(d.iloc[:, 0]))
# 删除nan所在行列
print(d.dropna(axis=0)) # 删除含有nan的行
print(d.dropna(axis=1)) # 删除含有nan的列
print(d)
print(d.dropna(axis=1, how='all')) # 默认情况下参数how='any',只要该行/列含有nan就删除,赋值all则整行/整列都为nan时删除
# print(d.dropna(axis=1, inplace=True)) # 当参数inplace赋值True时,在原对象上进行更改,此时d改变
print(d)
# 给nan赋值
print(d.mean())
print(d.fillna(d.mean())) # 对nan填入该列均值
print(d.iloc[:, 0].fillna(d.iloc[:, 0].mean(),inplace=True)) # 仅对地一列的nan填入该列均值
print(d)
pandas练习
- 假设现有一组从2006年到2016年1000部最流行的电影数据,想知道这些电影数据中评分的平均分,导演与演员的人数等信息。
import pandas as pd
import numpy as np
file_path = './datasets_IMDB-Movie-Data.csv'
movie_csv = pd.read_csv(file_path, encoding="gbk")
print(movie_csv.info()) # 显示数据信息
# 获取电影的平均评分
print(movie_csv['Rating'].mean())
# 导演人数
print(len(set(movie_csv['Director'].tolist()))) # 先通过.tolist()将列数据转化为列表形式,再利用集合去重
print(len(movie_csv['Director'].unique())) # .unique()直接对该列去重后列表展示
# 获取演员人数
actors_list = movie_csv['Actors'].str.split(',').tolist() # 演员列各演员名是用逗号分隔的,.tolist()将每一行演员名存放在列表中,整体列存放入列表
print(actors_list)
actors = [i for j in actors_list for i in j]
'''
actors = []
for j in actors_list:
for i in j:
actors.append(i)
'''
actors_num = len(set(actors))
print(actors_num)
- 对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
# 展示rating,runtime分布情况,选择直方图
import pandas as pd
from matplotlib import pyplot as plt
file_path = './datasets_IMDB-Movie-Data.csv'
movie_csv = pd.read_csv(file_path)
print(movie_csv.head(1)) # 显示首行数据
print(movie_csv.info()) # 显示数据信息
# 准备数据
runtime_data = movie_csv['Runtime (Minutes)'].values # 单取value是ndarray类型
# 确认数据上下界,上下界相差125分钟
max_runtime = runtime_data.max()
min_runtime = runtime_data.min()
# 通过调整组距确认组数
d = 5
num = (max_runtime - min_runtime) // d
# 作图
plt.figure(figsize=(15, 5), dpi=80)
plt.hist(runtime_data, num)
plt.xticks(range(min_runtime, max_runtime + 5, 5))
plt.show()
# rating为浮点数,需要自定义组距和匹配坐标轴
# 准备数据
rating_data = movie_csv['Rating'].values
# 确认数据上下界,上下界相差7.1分
max_rating = rating_data.max()
min_rating = rating_data.min()
# 通过调整组距确认组数1.9-3.5分的数据占比小,设置不等宽的组距
x_label = [1.9, 3.5] # 在列表中存放第一、第二个刻度值
i = 3.5
while i <= max_rating: # 后续数据按0.5刻度分组
i += 0.5
x_label.append(i)
# 做图
plt.figure(figsize=(20, 8), dpi=80)
# hist方法中取到的会是一个左闭右开的区间,所以要确保x_label内最后一个元素大于max_rating
plt.hist(rating_data, x_label)
# .xticks让自定义的组距与轴刻度一一对应上
plt.xticks(x_label)
plt.show()
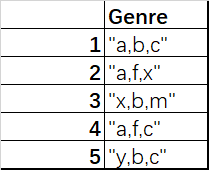
- 对于这一组电影数据,如果希望统计电影分类(Genre)的情况,应该如何处理数据?
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# 不分段显示
pd.set_option('display.width', 1000)
# 显示所有列
pd.set_option('display.max_columns', None)
file_path = './datasets_IMDB-Movie-Data.csv'
movie_csv = pd.read_csv(file_path)
print(movie_csv.info()) # 查看文件属性
print(movie_csv['Genre']) # 查看分类数据
思路
- 确认所有分类的集合
- 创建一个全为0的DataFrame,列索引就位分类名
- 读取文件Genre列中每行记录,在出现了的分类下赋值1
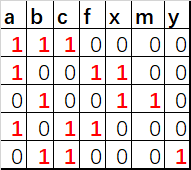
# 获取所有分类,用集合去重
genre_list = movie_csv['Genre'].str.split(',').tolist() # [[],[],[]]
gener = []
for j in genre_list:
for i in j:
gener.append(i)
unique_gener = set(gener)
# print(unique_gener)
# 构造全为0的数组
# 行数与源文件统一,列数为分类的个数;用类型名自定义列索引
zero_data = pd.DataFrame(np.zeros((movie_csv.shape[0], len(unique_gener))), columns=list(unique_gener))
# print(zero_data)
# 给出现了该分类的位置赋值1
for i in range(movie_csv.shape[0]): # 遍历文件数据行
# zero_data.loc[0,['Sci-Fi','History']=1,取一行多列,对文件中第一行分类为'Sci-Fi'和'History'索引处数据赋值1
zero_data.loc[i, genre_list[i]] = 1
# print(zero_data.head())
# 统计每个分类的和
type_sum = zero_data.sum(axis=0)
print(type_sum)
# 排序
type_sum = type_sum.sort_values()
# 作图
plt.figure(figsize=(15, 4), dpi=80)
x = type_sum.index
y = type_sum.values
plt.bar(x,y)
plt.xticks(x,x,rotation=45)
plt.show()















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









