






嵌入式考点
一、进程与线程
1、什么是进程、线程,有什么区别?
进程是资源(CPU、内存等)分配的基本单位,线程是CPU调度和分配的基本单位(程序执行的最小单位)。同一时间,如果CPU是单核,只有一个进程在执行,所谓的并发执行,也是顺序执行,只不过由于切换速度太快,你以为这些进程在同步执行而已。多核CPU可以同一时间点有多个进程在执行。
2、多进程、多线程的优缺点
说明:一个进程由进程控制块、数据段、代码段组成,进程本身不可以运行程序,而是像一个容器一样,先创建出一个主线程,分配给主线程一定的系统资源,这时候就可以在主线程开始实现各种功能。当我们需要实现更复杂的功能时,可以在主线程里创建多个子线程,多个线程在同一个进程里,利用这个进程所拥有的系统资源合作完成某些功能。
优缺点:
1)一个进程死了不影响其他进程,一个线程崩溃很可能影响到它本身所处的整个进程。
2)创建多进程的系统花销大于创建多线程。
3)多进程通讯因为需要跨越进程边界,不适合大量数据的传送,适合小数据或者密集数据的传送。多线程无需跨越进程边界,适合各线程间大量数据的传送。并且多线程可以共享同一进程里的共享内存和变量。
3、什么时候用进程,什么时候用线程
1)创建和销毁较频繁使用线程,因为创建进程花销大。
2)需要大量数据传送使用线程,因为多线程切换速度快,不需要跨越进程边界。
3)安全稳定选进程;快速频繁选线程
4、多进程、多线程同步(通讯)的方法
发展
Linux进程间通信**(IPC)**由以下几部分发展而来:
(1)UNIX进程间通信
(2)基于System V进程间通信
(3)POSIX进程间通信
分类
现在Linux使用的进程间通信方式**(IPC)**包括:
(1)管道:无名管道(pipe)和有名管道(FIFO)
(2)信号(signal)
(3)消息队列
(4)共享内存
(5)信号量
(6)套接字(socket)
(1)管道:半双工
a)管道是单向的、先进先出的,它把一个进程的输出和另一个进程的输入连接在一起。
b)一个进程(写进程)在管道的尾部写入数据,另一个进程(读进程)从管道的头部读出数据。
c)数据被一个进程读出后,将被从管道中删除,其它读进程将不能再读到这些数据。
d)管道提供了简单的流控制机制,进程试图读空管道时,进程将阻塞。同样,管道已经满时,进程再试图向管道写入数据,进程将阻塞
e)管道包括无名管道和有名管道两种,前者用于父进程和子进程间的通信,后者可用于运行于同一系统中的任意两个进程间的通信。

无名管道
管道用于不同进程间通信。通常先创建一个管道,再通过fork函数创建一个子进程,该子进程会继承父进程所创建的管道,必须在系统调用fork( )前调用pipe( ),否则子进程将不会继承文件描述符。
// 需要的头文件
#include <unistd.h>
// 通过pipe()函数来创建匿名管道
// 返回值:成功返回0,失败返回-1
// fd参数返回两个文件描述符
// fd[0]指向管道的读端,fd[1]指向管道的写端
// fd[1]的输出是fd[0]的输入。
int pipe (int fd[2]);
管道通讯是单向的,有固定的读端和写端。
a)数据被进程从管道读出后,在管道中该数据就不存在了。
b)当进程去读取空管道的时候,进程会阻塞。
c)当进程往满管道写入数据时,进程会阻塞。
d)管道容量为64KB
有名管道
有名管道和无名管道基本相同,但也有不同点:无名管道只能由父子进程使用;但是通过有名管道,不相关的进程也能交换数据。创建了一个FIFO,就可用open打开它,一般的文件访问函数(close、read、write等)都可用于FIFO。
FIFO文件在使用上和普通文件有相似之处,但是也有不同之处:
a)读取fifo文件的进程只能以**”只读”**方式打开fifo文件。
b)写fifo文件的进程只能以”只写”方式打开fifo
c)fifo文件里面的内容被读取后,就消失了。但是普通文件里面的内容读取后还存在。
(2)信号
信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
(3)消息队列:
消息队列是消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点
(4)共享内存 :
由一个进程映射一段能被其他进程所访问的共享内存,是最快的 IPC 方式,与信号量通信配合使用来实现进程间的同步和通信。
(5)信号量通信
信号量是一个计数器,可以用来控制多个进程对共享资源的访问。防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
(6)套接字通信
套接字( socket ) : 套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
#命名
-->struct sockaddr
#绑定
-->int bind(int socket, const struct sockaddr *address, size_t address_len);
#监听
-->int listen(int socket, int backlog);
+int accept(int socket, struct sockaddr *address, size_t *address_len);
#连接
-->int connect(int socket, const struct sockaddr *address, size_t address_len);
+connect(client_sockfd, (struct
sockaddr*)&client_address,sizeof(client_address));
#传输数据
-->int read(int socket, char *buffer, size_t len);
+int write(int socket, char *buffer, size_t len);
#断开
-->int close(int socket);
6.1命名socket
SOCK_STREAM 式本地套接字的通信双方均需要具有本地地址,其中服务器端的本地地址需要明确指定,指定方法是使用 struct sockaddr_un 类型的变量。
6.2 绑定
将命名后的socket的相应字段赋值,再将其绑定在创建的服务器套接字上,绑定要使用 bind 系统调用,代码如下:
int bind(int socket, const struct sockaddr *address, size_t address_len);
其中 socket表示服务器端的套接字描述符,address 表示需要绑定的本地地址,是一个 struct sockaddr_un 类型的变量,address_len 表示该本地地址的字节长度。
6.3 监听
命名和绑定后,需要进行监听,等待客户端连接并处理请求,监听使用 listen 系统调用,接受客户端连接使用accept系统调用,它们的原形如下:
int listen(int socket, int backlog);
int accept(int socket, struct sockaddr *address, size_t *address_len);
6.4 连接服务器
客户端套接字创建完毕并赋予本地地址值后,需要连接到服务器端进行通信,让服务器端为其提供处理服务。
对于SOCK_STREAM类型的流式套接字,需要客户端与服务器之间进行连接方可使用。连接要使用 connect 系统调用,其原形为
int connect(int socket, const struct sockaddr *address, size_t address_len);
其中socket为客户端的套接字描述符,address表示当前客户端的本地地址,是一个 struct sockaddr_un 类型的变量,address_len 表示本地地址的字节长度。实现连接的代码如下:
connect(client_sockfd, (struct sockaddr*)&client_address, sizeof(client_address));
6.5 相互发送接收数据
无论客户端还是服务器,都要和对方进行数据上的交互,这种交互也正是我们进程通信的主题。一个进程扮演客户端的角色,另外一个进程扮演服务器的角色,两个进程之间相互发送接收数据,这就是基于本地套接字的进程通信。发送和接收数据要使用 write 和 read 系统调用,它们的原形为:
int read(int socket, char *buffer, size_t len);
int write(int socket, char *buffer, size_t len);
其中 socket 为套接字描述符;len 为需要发送或需要接收的数据长度;
对于 read 系统调用,buffer 是用来存放接收数据的缓冲区,即接收来的数据存入其中,是一个输出参数;
对于 write 系统调用,buffer 用来存放需要发送出去的数据,即 buffer 内的数据被发送出去,是一个输入参数;返回值为已经发送或接收的数据长度。
6.6 断开连接
交互完成后,需要将连接断开以节省资源,使用close系统调用,其原形为:
int close(int socket);
线程通讯(锁):
#(1)信号量(2)读写锁(3)条件变量(4)互斥锁(5)自旋锁
同步与互斥
同步:两个或两个以上的进程或线程在运行过程中协同步调,按预定的先后次序运行。比如 A 任务的运行依赖于 B 任务产生的数据
互斥:一个公共资源同一时刻只能被一个进程或线程使用,多个进程或线程不能同时使用公共资源。
(1)信号量
信号量广泛用于进程或线程间的同步和互斥,信号量本质上是一个非负的整数计数器,它被用来控制对公共资源的访问。
编程时可根据操作信号量值的结果判断是否对公共资源具有访问的权限,当信号量值大于 0 时,则可以访问,否则将阻塞。PV 原语是对信号量的操作,一次 P 操作使信号量减1,一次 V 操作使信号量加1。
(2)读写锁(同步)
读写锁也叫共享互斥锁,允许更改的并行性。互斥量要么是锁住状态,要么就是不加锁状态,而且一次只有一个线程可以对其加锁。读写锁可以有3种状态:读模式下加锁状态、写模式加锁状态、不加锁状态。
一次只有一个线程可以占有写模式的读写锁,但是多个线程可以同时占有读模式的读写锁(允许多个线程读但只允许一个线程写)。
【特点】:
a)如果有其它线程申请了读锁,则允许其它线程执行读操作,但不允许写操作;
b)如果有其它线程申请了写锁,则其它线程都不允许读、写操作。
c)读写锁适合于对数据结构的读次数比写次数多得多的情况。
(3)条件变量(同步)
条件变量用来自动阻塞一个线程,直到某特殊情况发生为止。通常条件变量和互斥锁同时使用。通过while循环就能避免虚假唤醒造成的错误
【原理】:
条件的检测是在互斥锁的保护下进行的。线程在改变条件状态之前必须首先锁住互斥量。
条件变量使我们可以睡眠等待某种条件出现。条件变量是利用线程间共享的全局变量进行同步 的一种机制,主要包括两个动作:
- 一个线程等待"条件变量的条件成立"而挂起;
- 另一个线程使 “条件成立”(给出条件成立信号)。
条件变量可以被用来实现两进程共享可读写的内存。
【条件变量的操作流程如下】:
a)初始化:init()或者pthread_cond_tcond=PTHREAD_COND_INITIALIER;属性置为NULL;
b)等待条件成立:pthread_wait,pthread_timewait.wait()释放锁,并阻塞等待条件变量为真 timewait()设置等待时间,仍未signal,返回ETIMEOUT(加锁保证只有一个线程wait);
c)激活条件变量:pthread_cond_signal,pthread_cond_broadcast(激活所有等待线程)
d)清除条件变量:destroy;无线程等待,否则返回EBUSY
(4)互斥锁(同步)
在多任务操作系统中,同时运行的多个任务可能都需要使用同一种资源。
在线程里也有这么一把锁——互斥锁(mutex),分为:上锁( lock )和解锁( unlock )。
【特点】
**a)原子性:**把一个互斥量锁定为一个原子,其他线程在同一时间可以成功锁定这个互斥量;
**b)唯一性:**如果一个线程锁定了一个互斥量,在它解除锁定之前,没有其他线程可以锁定这个互斥量;
**c)非繁忙等待:**如果一个线程已经锁定了一个互斥量,第二个线程又试图去锁定这个互斥量,则第二个线程将被挂起(不占用任何cpu资源),直到第一个线程解除锁定并且销毁后,第二个线程被唤醒并继续执行,同时锁定这个互斥量。
(5)自旋锁
自旋锁与互斥量功能一样,不同的就是互斥量阻塞后休眠让出cpu,而自旋锁阻塞后不会让出cpu,会一直忙等待,直到得到锁。
自旋锁在用户态使用的比较少,在内核使用的比较多。
自旋锁的使用场景:锁的持有时间比较短,或者说小于2次上下文切换的时间。
自旋锁在用户态的函数接口和互斥量一样,把pthread_mutex_xxx()中mutex换成spin,如:pthread_spin_init()
5、进程线程的状态转换图
(1)就绪状态:进程已获得除CPU外的所有必要资源,只等待CPU时的状态。一个系统会将多个处于就绪状态的进程排成一个就绪队列。
(2)执行状态:进程已获CPU,正在执行。单处理机系统中,处于执行状态的进程只一个;多处理机系统中,有多个处于执行状态的进程。
(3)阻塞状态:正在执行的进程由于某种原因而暂时无法继续执行,便放弃处理机而处于暂停状态,即进程执行受阻。(这种状态又称等待状态或封锁状态)
1|通常导致进程阻塞的典型事件有:请求I/O,申请缓冲空间等。
2|将处于阻塞状态的进程排成一个队列,系统根据阻塞原因不同把阻塞集成排成多个队列。
请添加图片描述

(1) 就绪→执行
处于就绪状态的进程,当进程调度程序为之分配了处理机后,该进程便由就绪状态转变成执行状态。
(2) 执行→就绪
处于执行状态的进程在其执行过程中,因分配给它的一个时间片已用完而不得不让出处理机,于是进程从执行状态转变成就绪状态。
(3) 执行→阻塞
正在执行的进程因等待某种事件发生而无法继续执行时,便从执行状态变成阻塞状态。
(4) 阻塞→就绪
处于阻塞状态的进程,若其等待的事件已经发生,于是进程由阻塞状态转变为就绪状态。
6、父进程、子进程
父进程调用fork()以后,克隆出一个子进程,子进程和父进程拥有相同内容的代码段、数据段和用户堆栈。父进程和子进程谁先执行不一定,看CPU。所以我们一般我们会设置父进程等待子进程执行完毕。
7、说明什么是上下文切换?
有进程上下文,有中断上下文。
进程上下文:一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容,当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
中断上下文:由于触发信号,导致CPU中断当前进程,转而去执行另外的程序。那么当前进程的所有资源要保存,比如堆栈和指针。保存过后转而去执行中断处理程序,快读执行完毕返回,返回后恢复上一个进程的资源,继续执行。这就是中断的上下文。
8、中断
8.1中断定义
当出现需要时,CPU暂时停止当前程序的执行转而执行处理新情况的程序和执行过程。
硬件中断保存了一部分=>栈
软件中断保存了一部分(处理中断时 需要调用其他函数)
8.2中断类型
中断包括软件中断(不可屏蔽)和硬件中断。
软件中断为内核触发机制引起,模拟硬件中断。硬件中断又分为外部中断(可屏蔽)和内部中断(不可屏蔽)
外部中断为一般外设请求;内部中断包括硬件出错(掉电,校验,传输)和运算出错(非法数据,地址,越界,溢出)
8.3 硬件中断
1|硬件中断是由与系统相连的外设(比如硬盘 键盘等)自动产生的.
2|每个设备有自己的IRQ(中断请求),基于IRQ, CPU将的请求发送到相应的硬件驱动上
3|处理中断的驱动运行在CPU上,当中断产生时, CPU会暂时停止当前程序转而执行中断请求.
4|硬件中断又分为外部中断(可屏蔽)和内部中断(不可屏蔽)
5|外部中断为一般外设请求;
6|内部中断包括硬件出错(掉电,校验,传输)和运算出错(非法数据,地址,越界,溢出)
8.4 软件中断
1|内核触发机制引起,模拟硬件中断
2|软中断不会直接中断CPU, 也只有当前正在运行的代码(或进程)才会产生软中断.
3|软中断是一种需要内核为正在运行的进程去做一些事情(通常为I/O)的请求.
8.5 软件中断和软件中断的区别
1|硬件中断是由外设引发的, 软中断是执行中断指令产生的.
2|硬件中断的中断号是由中断控制器提供的, 软中断的中断号由指令直接指出, 无需使用中断控制器.
3|硬件中断是可屏蔽的, 软中断不可屏蔽.
4|硬件中断处理程序要确保它能快速地完成任务, 这样程序执行时才不会等待较长时间, 称为上半部.
5|软中断处理硬中断未完成的工作, 是一种推后执行的机制, 属于下半部.
二、C/C++题目
1、new和malloc
做嵌入式,对于内存是十分在意的,因为可用内存有限,所以嵌入式笔试面试题目,内存的题目高频。
1)malloc和free是c++/c语言的库函数,需要头文件支持stdlib.h;new和delete是C++的关键字,不需要头文件,需要编译器支持;
2)使用new操作符申请内存分配时,无需指定内存块的大小,编译器会根据类型信息自行计算。而malloc则需要显式地支持所需内存的大小。
3)new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无需进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void*,需要通过强制类型转换将void*指针转换成我们需要的类型。
4)new内存分配失败时,会抛出bad_alloc异常。malloc分配内存失败时返回NULL。
2、在1G内存的计算机中能否malloc(1.2G)?为什么?(2021浙江大华二面问题)
答:是有可能申请1.2G的内存的。
1|回答这个问题前需要知道malloc的作用和原理,
2|应用程序通过malloc函数可以向程序的虚拟空间申请一块虚拟地址空间,
3|与物理内存没有直接关系,得到的是在虚拟地址空间中的地址,
4|之后程序运行所提供的物理内存是由操作系统完成的。
3 、extern”C” 的作用
我们可以在C++中使用C的已编译好的函数模块,这时候就需要用到extern”C”。也就是extern“C” 都是在c++文件里添加的。
extern在链接阶段起作用(四大阶段:预处理--编译--汇编--链接)
4、strcat、strncat、strcmp、strcpy哪些函数会导致内存溢出?如何改进?(2021浙江大华二面问题)
strcpy函数会导致内存溢出。
strcpy拷贝函数不安全,他不做任何的检查措施,也不判断拷贝大小,不判断目的地址内存是否够用。
char *strcpy(char *strDest,const char *strSrc)
strncpy拷贝函数,虽然计算了复制的大小,但是也不安全,没有检查目标的边界。
strncpy(dest, src, sizeof(dest));
strncpy_s是安全的。
strcmp(str1,str2),是比较函数,若str1=str2,则返回零;若str1<str2,则返回负数;若str1>str2,则返回正数。(比较字符串)
strncat()主要功能是在字符串的结尾追加n个字符。
char * strncat(char *dest, const char *src, size_t n);
strcat()函数主要用来将两个char类型连接。例如:
char d[20]="Golden";
char s[20]="View";
strcat(d,s);
//打印d
printf("%s",d);
-----------
输出 d 为 GoldenView (中间无空格)
延伸:
memcpy拷贝函数,它与strcpy的区别就是memcpy可以拷贝任意类型的数据,strcpy只能拷贝字符串类型。
memcpy 函数用于把资源内存(src所指向的内存区域)拷贝到目标内存(dest所指向的内存区域);有一个size变量控制拷贝的字节数;
函数原型:
void *memcpy(void *dest, void *src, unsigned int count);
5 、static的用法(定义和用途)(必考)
1)用static修饰局部变量:使其变为静态存储方式(静态数据区),那么这个局部变量在函数执行完成之后不会被释放,而是继续保留在内存中。
2)用static修饰全局变量:使其只在本文件内部有效,而其他文件不可连接或引用该变量。
3)用static修饰函数:对函数的连接方式产生影响,使得函数只在本文件内部有效,对其他文件是不可见的(这一点在大工程中很重要很重要,避免很多麻烦,很常见)。这样的函数又叫作静态函数。使用静态函数的好处是,不用担心与其他文件的同名函数产生干扰,另外也是对函数本身的一种保护机制。
6、const的用法(定义和用途)(必考)
const主要用来修饰变量、函数形参和类成员函数:
1)用const修饰常量:定义时就初始化,以后不能更改。
2)用const修饰形参:func(const int a){};该形参在函数里不能改变。
3)用const修饰类成员函数:该函数对成员变量只能进行只读操作,就是const类成员函数是不能修改成员变量的数值的。
被const修饰的东西都受到强制保护,可以预防意外的变动,能提高程序的健壮性。
参考一个大佬的回答:
我只要一听到被面试者说:“const意味着常数”,我就知道我正在和一个业余者打交道。
去年Dan Saks已经在他的文章里完全概括了const的所有用法,
因此每一位读者应该非常熟悉const能做什么和不能做什么.如果你从没有读到那篇文章,
只要能说出const意味着"只读"就可以了。尽管这个答案不是完全的答案,但我接受它作为一个正确的答案。
如果应试者能正确回答这个问题,我将问他一个附加的问题:下面的声明都是什么意思?
1|const int a;
2|int const a;
3|const int *a;
4|int * const a;
5|int const * a const;
--------------------
1|前两个的作用是一样,a是一个常整型数。
2第三个意味着a是一个指向常整型数的指针(也就是,整型数是不可修改的,但指针可以)。
3|第四个意思a是一个指向整型数的常指针(也就是说,指针指向的整型数是可以修改的,但指针是不可修改的)。
4|最后一个意味着a是一个指向常整型数的常指针(也就是说,指针指向的整型数是不可修改的,同时指针也是不可修改的)。
7、volatile作用和用法
一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。精确地说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量在内存中的值,而不是使用保存在寄存器里的备份(虽然读写寄存器比读写内存快)。
回答不出这个问题的人是不会被雇佣的。这是区分C程序员和嵌入式系统程序员的最基本的问题。搞嵌入式的家伙们经常同硬件、中断、RTOS等等打交道,所有这些都要求用到volatile变量。不懂得volatile的内容将会带来灾难。
以下几种情况都会用到volatile:
1、并行设备的硬件寄存器(如:状态寄存器)
2、一个中断服务子程序中会访问到的非自动变量
3、多线程应用中被几个任务共享的变量
8、const常量和#define的区别(编译阶段、安全性、内存占用等)
用#define max 100 ; 定义的常量是没有类型的(不进行类型安全检查,可能会产生意想不到的错误),所给出的是一个立即数,编译器只是把所定义的常量值与所定义的常量的名字联系起来,define所定义的宏变量在预处理阶段的时候进行替换,在程序中使用到该常量的地方都要进行拷贝替换;
用const int max = 255 ; 定义的常量有类型(编译时会进行类型检查)名字,存放在内存的静态区域中,在编译时确定其值。在程序运行过程中const变量只有一个拷贝,而#define所定义的宏变量却有多个拷贝,所以宏定义在程序运行过程中所消耗的内存要比const变量的大得多。
9、变量的作用域(全局变量和局部变量)
全局变量:在所有函数体的外部定义的,程序的所在部分(甚至其它文件中的代码)都可以使用。全局变量不受作用域的影响(也就是说,全局变量的生命期一直到程序的结束)。
局部变量:出现在一个作用域内,它们是局限于一个函数的。局部变量经常被称为自动变量,因为它们在进入作用域时自动生成,离开作用域时自动消失。关键字auto可以显式地说明这个问题,但是局部变量默认为auto,所以没有必要声明为auto。
1|局部变量可以和全局变量重名
2|在局部变量作用域范围内,全局变量失效,采用的是局部变量的值。
10、sizeof 与strlen (字符串,数组)
1.如果是数组
include<stdio.h>
int main()
{
int a[5]={1,2,3,4,5};
printf(“sizeof 数组名=%d\n”,sizeof(a));
printf(“sizeof *数组名=%d\n”,sizeof(*a));
}
------------------------
sizeof 数组名=20
sizeof *数组名=4
2.如果是指针,sizeof只会检测到是指针的类型,指针都是占用4个字节的空间(32位机)。
sizeof是什么?是一个操作符,也是关键字,就不是一个函数,这和strlen()不同,strlen()是一个函数。
那么sizeof的作用是什么?返回一个对象或者类型所占的内存字节数。我们会对sizeof()中的数据或者指针做运算吗?基本不会。例如sizeof(1+2.0),直接检测到其中类型是double,即是sizeof(double) = 8。如果是指针,sizeof只会检测到是指针的类型,指针都是占用4个字节的空间(32位机)。
char *p = "sadasdasd";
sizeof(p):4
sizeof(*p):1//指向一个char类型的
除非使用strlen(),仅对字符串有效,直到’\0’为止了,计数结果不包括\0。
要是非要使用sizeof来得到指向内容的大小,就得使用数组名才行, 如
char a[10];
sizeof(a):10 //检测到a是一个数组的类型。
```
关于strlen(),它是一个函数,考察的比较简单:
```cpp
strlen “\n\t\tag\AAtang”
-------
11
11、经典的sizeof(struct)和sizeof(union)内存对齐
内存对齐作用:
1.平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2.性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
结构体struct内存对齐的3大规则:
1.对于结构体的各个成员,第一个成员的偏移量是0,排列在后面的成员其当前偏移量必须是当前成员类型的整数倍;
2.结构体内所有数据成员各自内存对齐后,结构体本身还要进行一次内存对齐,保证整个结构体占用内存大小是结构体内最大数据成员的最小整数倍;
3.如程序中有#pragma pack(n)预编译指令,则所有成员对齐以n字节为准(即偏移量是n的整数倍),不再考虑当前类型以及最大结构体内类型。
#pragma pack(1)
struct fun{
int i;
double d;
char c;
};
//sizeof(fun) = 13
struct CAT_s
{
int ld;
char Color;
unsigned short Age;
char *Name;
void(*Jump)(void);
}Garfield;
1.使用32位编译,int占4, char 占1, unsigned short 占2,char* 占4,函数指针占4个,由于是32位编译是4字节对齐,所以该结构体占16个字节。(说明:按几字节对齐,是根据结构体的最长类型决定的,这里是int是最长的字节,所以按4字节对齐);
2.使用64位编译 ,int占4, char 占1, unsigned short 占2,char* 占8,函数指针占8个,由于是64位编译是8字节对齐(说明:按几字节对齐,是根据结构体的最长类型决定的,这里是函数指针是最长的字节,所以按8字节对齐)所以该结构体占24个字节。
//64位
struct C
{
double t; //8 1111 1111
char b; //1 1
int a; //4 0001111
short c; //2 11000000
};
sizeof(C) = 24; //注意:1 4 2 不能拼在一起
联合体union内存对齐的2大规则:
1|找到占用字节最多的成员;
2|union的字节数必须是占用字节最多的成员的字节的倍数,而且需要能够容纳其他的成员。
//x64
typedef union {
long i;
int k[5];
char c;
}D
要计算union的大小,首先要找到占用字节最多的成员,本例中是long,占用8个字节,int k[5]中都是int类型,仍然是占用4个字节的,然后union的字节数必须是占用字节最多的成员的字节的倍数,而且需要能够容纳其他的成员,为了要容纳k(20个字节),就必须要保证是8的倍数的同时还要大于20个字节,所以是24个字节。
引申:位域(大疆笔试题)
C语言允许在一个结构体中以位为单位来指定其成员所占内存长度,这种以位为单位的成员称为“位段”或称“位域”( bit field) 。利用位段能够用较少的位数存储数据。一个位段必须存储在同一存储单元中,不能跨两个单元。如果第一个单元空间不能容纳下一个位段,则该空间不用,而从下一个单元起存放该位段。
1.位段声明和结构体类似
2.位段的成员必须是int、unsigned int、signed int
3.位段的成员名后边有一个冒号和一个数字
typedef struct_data{
char m:3;
char n:5;
short s;
union{
int a;
char b;
};
int h;
}_attribute_((packed)) data_t;
答案12
m和n一起,刚好占用一个字节内存,因为后面是short类型变量,所以在short s之前,应该补一个字节。所以m和n其实是占了两个字节的,然后是short两个个字节,加起来就4个字节,然后联合体占了四个字节,总共8个字节了,最后int h占了四个字节,就是12个字节了。
1|attribute((packed)) 取消对齐
2|GNU C的一大特色就是__attribute__机制。__attribute__可以设置函数属性(Function Attribute)、变量属性(Variable Attribute)和类型属性(Type Attribute)。
3|__attribute__书写特征是:__attribute__前后都有两个下划线,并且后面会紧跟一对括弧,括弧里面是相应的__attribute__参数。
跨平台通信时用到。不同平台内存对齐方式不同。如果使用结构体进行平台间的通信,会有问题。例如,发送消息的平台上,结构体为24字节,接受消息的平台上,此结构体为32字节(只是随便举个例子),那么每个变量对应的值就不对了。
不同框架的处理器对齐方式会有不同,这个时候不指定对齐的话,会产生错误结果。
12、inline函数
在C语言中,如果一些函数被频繁调用,不断地有函数入栈,即函数栈,会造成栈空间或栈内存的大量消耗。为了解决这个问题,特别的引入了inline修饰符,表示为内联函数。
大多数的机器上,调用函数都要做很多工作:调用前要先保存寄存器,并在返回时恢复,复制实参,程序还必须转向一个新位置执行C++中支持内联函数,其目的是为了提高函数的执行效率,用关键字 inline 放在函数定义(注意是定义而非声明)的前面即可将函数指定为内联函数,内联函数通常就是将它在程序中的每个调用点上“内联地”展开。
内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率。
13、内存四区,什么变量分别存储在什么区域,堆上还是栈上。

文字常量区,叫.rodata,不可以改变,改变会导致段错误
int a0=1;
static int a1;
const static a2=0;
extern int a3;
void fun(void)
{
int a4;
volatile int a5;
return;
}
------------------------------
a0 :全局初始化变量;生命周期为整个程序运行期间;作用域为所有文件;存储位置为data段。
a1 :全局静态未初始化变量;生命周期为整个程序运行期间;作用域为当前文件;储存位置为BSS段。
a2 :全局静态变量
a3 :全局初始化变量;其他同a0。
a4 :局部变量;生命周期为fun函数运行期间;作用域为fun函数内部;储存位置为栈。
a5 :局部易变变量;
14、使用32位编译情况下,给出判断所使用机器大小端的方法。

**联合体方法判断方法:**利用union结构体的从低地址开始存,且同一时间内只有一个成员占有内存的特性。大端储存符合阅读习惯。联合体占用内存是最大的那个,和结构体不一样。
a和c公用同一片内存区域,所以更改c,必然会影响a的数据。
#include<stdio.h>
int main(){
union w
{
int a;
char b;
}c;
c.a = 1;
if(c.b == 1)
printf("小端存储\n");
else
printf("大端存储\n");
return 0;
}
指针方法
通过将int强制类型转换成char单字节,p指向a的起始字节(低字节)
#include <stdio.h>
int main ()
{
int a = 1;
char *p = (char *)&a;
if(*p == 1)
{
printf("小端存储\n");
}
else
{
printf("大端存储\n");
}
return 0;
}
15、用变量a给出下面的定义
a) 一个整型数;
b)一个指向整型数的指针;
c)一个指向指针的指针,它指向的指针是指向一个整型数;
d)一个有10个整型的数组;
e)一个有10个指针的数组,该指针是指向一个整型数;
f)一个指向有10个整型数数组的指针;
g)一个指向函数的指针,该函数有一个整型参数并返回一个整型数;
h)一个有10个指针的数组,该指针指向一个函数,该函数有一个整型参数并返回一个整型数
------------------------------------------
a) int a
b) int *a;
c) int **a;
d) int a[10];
e) int *a [10];
f) int a[10], *p=a;
g) int (*a)(int)
h) int( *a[10])(int)
16、与或非,异或。运算符优先级
sum=a&b<<c+a^c;
其中a=3,b=5,c=4(先加再移位再&再异或)
----------
答案4

三、网络编程
1 、TCP、UDP的区别
TCP—传输控制协议,提供的是面向连接、可靠的字节流服务。当客户和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据。
UDP—用户数据报协议,是一个简单的面向数据报的运输层协议。UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。
1)TCP是面向连接的,UDP是面向无连接的
2)UDP程序结构较简单
3)TCP是面向字节流的,UDP是基于数据报的
4)TCP保证数据正确性,UDP可能丢包
5)TCP保证数据顺序到达,UDP不保证
2 、TCP、UDP的优缺点
TCP优点:可靠稳定
TCP的可靠体现在TCP在传输数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完之后,还会断开来连接用来节约系统资源。
TCP缺点:慢,效率低,占用系统资源高,易被攻击
在传递数据之前要先建立连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞机制等都会消耗大量时间,而且要在每台设备上维护所有的传输连接。然而,每个连接都会占用系统的CPU,内存等硬件资源。因为TCP有确认机制、三次握手机制,这些也导致TCP容易被利用,实现DOS、DDOS、CC等攻击。
UDP优点:快,比TCP稍安全
UDP没有TCP拥有的各种机制,是一种无状态的传输协议,所以传输数据非常快,没有TCP的这些机制,被攻击利用的机会就少一些,但是也无法避免被攻击。
UDP缺点:不可靠,不稳定
因为没有TCP的这些机制,UDP在传输数据时,如果网络质量不好,就会很容易丢包,造成数据的缺失。
3 、TCP、UDP适用场景
TCP:传输一些对信号完整性,信号质量有要求的信息。
UDP:对网络通讯质量要求不高时,要求网络通讯速度要快的场景。
4、 TCP为什么是可靠连接?
因为tcp传输的数据满足3大条件,不丢失,不重复,按顺序到达。
5、OSI典型网络模型,简单说说有哪些?
6、三次握手、四次挥手
三次握手

1、TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了LISTEN(监听)状态;
2、TCP客户进程也是先创建传输控制块TCB
然后向服务器发出连接请求报文,这是报文首部中的同部位SYN=1
同时选择一个初始序列号seq=x ,此时,TCP客户端进程进入了 SYN-SENT(同步已发送状态)状态。
TCP规定,SYN报文段(SYN=1的报文段)不能携带数据
但需要消耗掉一个序号。
3、TCP服务器收到请求报文后,如果同意连接,则发出确认报文。
确认报文中应该ACK=1,SYN=1,确认号是ack=x+1
同时也要为自己初始化一个序列号seq=y
此时,TCP服务器进程进入了SYN-RCVD(同步收到)状态
这个报文也不能携带数据,但是同样要消耗一个序号。
4、TCP客户进程收到确认后,还要向服务器给出确认
确认报文的ACK=1,ack=y+1,自己的序列号seq=x+1
此时,TCP连接建立,客户端进入ESTABLISHED(已建立连接)状态
TCP规定,ACK报文段可以携带数据,但是如果不携带数据则不消耗序号。
5、当服务器收到客户端的确认后也进入ESTABLISHED状态,此后双方就可以开始通信了。
四次挥手

1、客户端进程发出连接释放报文,并且停止发送数据
释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1)
此时,客户端进入FIN-WAIT-1(终止等待1)状态
TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2、服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1
并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态
TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了
这时候处于半关闭状态,即客户端已经没有数据要发送了
但是服务器若发送数据,客户端依然要接受
这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3、客户端收到服务器的确认请求后
此时,客户端就进入FIN-WAIT-2(终止等待2)状态
等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4、服务器将最后的数据发送完毕后,就向客户端发送连接释放报文
FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据
假定此时的序列号为seq=w
此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5、客户端收到服务器的连接释放报文后,必须发出确认,
ACK=1,ack=w+1,而自己的序列号是seq=u+1
此时,客户端就进入了TIME-WAIT(时间等待)状态
注意此时TCP连接还没有释放,必须经过2∗ *∗MSL(最长报文段寿命)的时间后
当客户端撤销相应的TCB后,才进入CLOSED状态。
6、服务器只要收到了客户端发出的确认
立即进入CLOSED状态。同样,撤销TCB后
就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
四、常见算法
1、十种常见排序算法可以分为两大类:
**非线性时间比较类排序:**通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序。
**线性时间非比较类排序:**不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。
2、算法优劣评价术语
稳定性:
稳定:如果 a 原本在 b 前面,而 a = b,排序之后 a 仍然在 b 的前面;
不稳定:如果 a 原本在 b 的前面,而 a = b,排序之后 a 可能会出现在 b 的后面;
排序方式:
内排序:所有排序操作都在内存中完成,占用常数内存,不占用额外内存。
外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行,占用额外内存。
复杂度:
时间复杂度: 一个算法执行所耗费的时间。
空间复杂度: 运行完一个程序所需内存的大小。

五、Linux操作系统题目
1、 Linux内核的组成部分
Linux内核主要由五个子系统组成:进程调度,内存管理,虚拟文件系统,网络接口,进程间通信。
2Linux系统的组成部分
Linux系统一般有4个主要部分:内核、shell、文件系统和应用程序。
3、用户空间与内核通信方式有哪些?
1)系统调用。用户空间进程通过系统调用进入内核空间,访问指定的内核空间数据;
2)驱动程序。用户空间进程可以使用封装后的系统调用接口访问驱动设备节点,以和运行在内核空间的驱动程序通信;
3)共享内存mmap。在代码中调用接口,实现内核空间与用户空间的地址映射,在实时性要求很高的项目中为首选,省去拷贝数据的时间等资源,但缺点是不好控制;
4)copy_to_user()、copy_from_user(),是在驱动程序中调用接口,实现用户空间与内核空间的数据拷贝操作,应用于实时性要求不高的项目中。
4、系统调用与普通函数调用的区别
系统调用:
1.使用INT和IRET指令,内核和应用程序使用的是不同的堆栈,因此存在堆栈的切换,从用户态切换到内核态,从而可以使用特权指令操控设备。
2.依赖于内核,不保证移植性
3.在用户空间和内核上下文环境间切换,开销较大
4.是操作系统的一个入口点
普通函数调用:
1.使用CALL和RET指令,调用时没有堆栈切换
2.平台移植性好
3.属于过程调用,调用开销较小
4.一个普通功能函数的调用
5、内核态,用户态的区别
1|内核态,操作系统在内核态运行——运行操作系统程序
2|用户态,应用程序只能在用户态运行——运行用户程序
当一个进程在执行用户自己的代码时处于用户运行态(用户态),此时特权级最低,为3级,是普通的用户进程运行的特权级,大部分用户直接面对的程序都是运行在用户态。Ring3状态不能访问Ring0的地址空间,包括代码和数据;当一个进程因为系统调用陷入内核代码中执行时处于内核运行态(内核态),此时特权级最高,为0级。执行的内核代码会使用当前进程的内核栈,每个进程都有自己的内核栈
6、 bootloader、内核 、根文件的关系
1|启动顺序:bootloader->linux kernel->rootfile->app
Bootloader全名为启动引导程序,是第一段代码,它主要用来初始化处理器及外设,然后调用Linux内核。
Linux内核在完成系统的初始化之后需要挂载某个文件系统作为根文件系统(RootFilesystem),然后加载必要的内核模块,启动应用程序。
7 、Bootloader启动的两个阶段:
Stage1:汇编语言
1)基本的硬件初始化(关闭看门狗和中断,MMU(带操作系统),CACHE。配置系统工作时钟)
2)为加载stage2准备RAM空间
3)拷贝内核映像和文件系统映像到RAM中 4)设置堆栈指针sp 5)跳到stage2的入口点
Stage2:c语言
1)初始化本阶段要使用到的硬件设备(led uart等)
2)检测系统的内存映射
3)加载内核映像和文件系统映像
4)设置内核的启动参数
嵌入式系统中广泛采用的非易失性存储器通常是Flash,而Bootloader就位于该存储器的最前端,所以系统上电或复位后执行的第一段程序便是Bootloader。
8、 linux下检查内存状态的命令
1)查看进程:top
2)查看内存:free
3)cat /proc/meminfo
4)vmstat
假如一个公司服务器有很多用户,你使用top命令,可以看到哪个同事在使用什么命令,做什么事情,占用了多少CPU。
9 、一个程序从开始运行到结束的完整过程(四个过程)
预处理(Pre-Processing)、编译(Compiling)、汇编(Assembling)、链接(Linking)
1|预编译
命令是gcc -E main.c -o main.o 假设当前要编译的文件是main.c;
--将所有的define删除,并展开所有的宏定义;处理所有的预编译指令;处理include预编译指令,将被包含的文件插入到预编译指令的位置
--添加行号信息文件名标识,便于调试;删除所有的注释;保留所有的pragma编译指令;生成.i文件
2|编译:C语言——>汇编:gcc -s main.i -o main.s
--扫描,语法分析,语义分析,源代码优化,目标代码生成,目标代码优化;、生成汇编代码;汇总符号;生成.s文件
3|汇编:汇编——>二进制 gcc -c main.s -o main.o
--根据汇编指令和特定平台,把汇编指令翻译成二进制形式;合并各个section,合并符号表;生成.o文件。
4|链接
--合并各个.obj文件的section,合并符号表,进行符号解析;符号地址重定位;生成可执行文件
也可以从c源代码开始经过预处理,编译,汇编,链接直接输出可执行文件,他的命令是:gcc -c main.s -o main.o 。
10、什么是堆,栈,内存泄漏和内存溢出?
栈由系统操作,程序员不可以操作。
所以内存泄漏是指堆内存的泄漏。堆内存是指程序从堆中分配的,大小任意的(内存块的大小可以在程序运行期决定),使用完后必须显式释放的内存。应用程序一般使用malloc,new等函数从堆中分配到一块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块,否则,这块内存就不能被再次使用。
**内存溢出:**你要求分配的内存超出了系统能给你的,系统不能满足需求,于是产生溢出。
**内存越界:**向系统申请了一块内存,而在使用内存时,超出了申请的范围(常见的有使用特定大小数组时发生内存越界)
内存溢出问题是 C 语言或者 C++ 语言所固有的缺陷,它们既不检查数组边界,又不检查类型可靠性(type-safety)。众所周知,用C/C++ 语言开发的程序由于目标代码非常接近机器内核,因而能够直接访问内存和寄存器,这种特性大大提升了 C/C++语言代码的性能。只要合理编码,C/C++ 应用程序在执行效率上必然优于其它高级语言。然而,C/C++语言导致内存溢出问题的可能性也要大许多。
11、死锁的原因、条件
产生死锁的原因主要是:
(1) 因为系统资源不足。
(2) 进程运行推进的顺序不合适。
(3) 资源分配不当等。
如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则就会因争夺有限的资源而陷入死锁。其次,进程运行推进顺序与速度不同,也可能产生死锁。
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3)不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
12、硬链接与软链接
链接操作实际上是给系统中已有的某个文件指定另外一个可用于访问它的名称。对于这个新的文件名,我们可以为之指定不同的访问权限,以控制对信息的共享和安全性的问题。如果链接指向目录,用户就可以利用该链接直接进入被链接的目录而不用打一大堆的路径名。而且,即使我们删除这个链接,也不会破坏原来的目录。
1)硬链接
硬链接只能引用同一文件系统中的文件。它引用的是文件在文件系统中的物理索引(也称为inode)。当您移动或删除原始文件时,硬链接不会被破坏,因为它所引用的是文件的物理数据而不是文件在文件结构中的位置。硬链接的文件不需要用户有访问原始文件的权限,也不会显示原始文件的位置,这样有助于文件的安全。如果您删除的文件有相应的硬链接,那么这个文件依然会保留,直到所有对它的引用都被删除。
2)软链接(符号链接)
软连接,其实就是新建立一个文件,这个文件就是专门用来指向别的文件的(那就和windows 下的快捷方式的那个文件有很接近的意味)。软连接产生的是一个新的文件,但这个文件的作用就是专门指向某个文件的,删了这个软连接文件,那就等于不需要这个连接,和原来的存在的实体原文件没有任何关系,但删除原来的文件,则相应的软连接不可用。
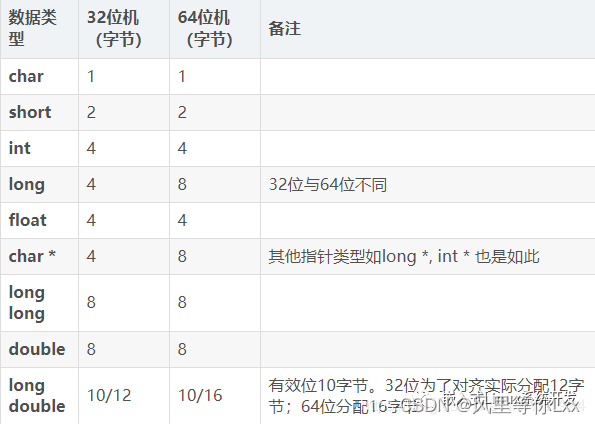
13、计算机中,32bit与64bit有什么区别
64bit计算主要有两大优点:可以进行更大范围的整数运算;可以支持更大的内存。
64位操作系统下的虚拟内存空间大小:地址空间大小不是2^32, 也不是2^64, 而一般是2^48。 因为并不需要2^64 那么大的寻址空间,过大的空间只会造成资源的浪费。所以64位Linux一般使用48位表示虚拟空间地址,40位标识物理地址。
14、中断和异常的区别
**内中断:**同步中断(异常)是由cpu内部的电信号产生的中断,其特点为当前执行的指令结束后才转而产生中断,由于有cpu主动产生,其执行点必然是可控的。
**外中断:**异步中断是由cpu的外设产生的电信号引起的中断,其发生的时间点不可预期。
15、中断怎么发生,中断处理流程
请求中断→响应中断→关闭中断→保留断点→中断源识别→保护现场→中断服务子程序→恢复现场→中断返回。 
16、 Linux 操作系统挂起、休眠、关机相关命令
1|关机命令有halt, init 0, poweroff ,shutdown -h 时间,其中shutdown是最安全的。
2|重启命令有reboot,init 6,,shutdow -r时间
3|在linux命令中reboot是重新启动,shutdown -r now是立即停止然后重新启动。
17、说一个linux下编译优化选项:
1|加:-o
18、在有数据cache情况下,DMA数据链路为:
1|DMA(直接储存器访问)
2|外设-DMA-DDR-cache-CPU
19、linux命令
1、改变文件属性的命令:chmod (chmod 777 /etc/squid
运行命令后,squid文件夹(目录)的权限就被修改为777(可读可写可执行))
2、查找文件中匹配字符串的命令:grep
3、查找当前目录:pwd
4、删除目录:rm -rf 目录名
5、删除文件:rm 文件名
6、创建目录(文件夹):mkdir
7、创建文件:touch
8、vi和vim 文件名也可以创建
9、解压:tar -xzvf 压缩包
打包:tar -cvzf 目录(文件夹)
10、查看进程对应的端口号
1、先查看进程pid
ps -ef | grep 进程名
2、通过pid查看占用端口
netstat -nap | grep 进程pid
20、硬实时系统和软实时系统
软实时系统:
Windows、Linux系统通常为软实时,当然有补丁可以将内核做成硬实时的系统,不过商用没有这么做的。
硬实时系统:
对时间要求很高,限定时间内不管做没做完必须返回。
VxWorks,uCOS,FreeRTOS,WinCE,RT-thread等实时系统;
21、MMU基础
现代操作系统普遍采用虚拟内存管理(Virtual Memory Management) 机制,这需要MMU( Memory Management Unit,内存管理单元) 的支持。有些嵌入式处理器没有MMU,则不能运行依赖于虚拟内存管理的操作系统。
1|也就是说:操作系统可以分成两类,用MMU的、不用MMU的。
**用MMU的是:**Windows、MacOS、Linux、Android;
**不用MMU的是:**FreeRTOS、VxWorks、UCOS……
1|与此相对应的:CPU也可以分成两类,带MMU的、不带MMU的。
带MMU的是:Cortex-A系列、ARM9、ARM11系列;
不带MMU的是:Cortex-M系列……(STM32是M系列,没有MMU,不能运行Linux,只能运行一些UCOS、FreeRTOS等等)。
MMU就是负责虚拟地址(virtual address)转化成物理地址(physical address),转换过程比较复杂。















 1471
1471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









