







摘要
知识图的表示学习旨在将实体和关系编码到一个连续的低维向量空间中。大多数现有的方法只专注于学习位于三元组中的结构化信息表示,而忽略了位于层次类型实体中的丰富信息,这些信息可以在大多数知识图中收集。在本文中,我们提出了一种利用分层实体类型的新方法——类型嵌入知识表示学习(TKRL)。我们建议实体应该具有不同类型的多个表示。更具体地说,我们将层次类型视为实体的投影矩阵,并设计了两个类型编码器来建模层次结构。同时,类型信息也被用作关系特定的类型约束。我们在知识图补全和三重分类两个任务上评估了我们的模型,并进一步探讨了在长尾数据集上的性能。实验结果表明,我们的模型在这两个任务上都明显优于所有基线,特别是在长尾分布情况下。这表明我们的模型能够捕获层次类型信息,这在构建知识图表示时是非常重要的。本文的源代码可从https://github.com/thunlp/TKRL获取。
1.介绍
Freebase、DBpedia和YAGO等知识图(KGs)提供了有效的结构化信息,在信息检索和问题解答中起着至关重要的作用。典型的KG通常表示为具有大量三重事实的多关系数据,其形式为(头实体、关系、尾实体),简化为(h, r, t)。
随着KG大小的增加,由于数据稀疏和计算效率低,KG应用变得更具挑战性。针对这些问题,将实体和关系投射到连续低维语义空间的表示学习(R-L)在知识补全、融合和推理中得到了广泛应用。它显著提高了KGs的认知和推理能力[Bordes et al., 2013;杨杨等,2014;董等,2014;Neelakantan et al., 2015]。
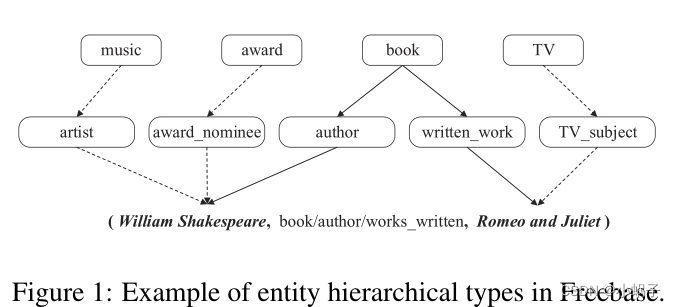
基于翻译的模型简单有效,具有最先进的性能。不幸的是,大多数传统方法只关注三元组中的结构化信息,而很少关注位于分层实体类型中的丰富信息。图1显示了一个组合了从Freebase采样的部分层次类型的三元组实例,其中实线表示头和尾在这个三元组中扮演的最重要的角色。
具有多种类型的实体应该在不同的场景中具有不同的表示形式,这是很直观的。为了充分利用实体类型的优势,我们提出了一种新的有效的知识学习方法——Type-embodied Knowledge
Representation Learning (TKRL)。在TKRL中,我们遵循TransE [Bordes等人,2013]中的假设,将关系视为头部和尾部之间的翻译操作。对于每个三元组(h, r, t), h和t首先以这种关系投影到对应的类型空间![]() ,根据用两个分层类型编码器构造的类型特定投影矩阵。然后通过最小化
,根据用两个分层类型编码器构造的类型特定投影矩阵。然后通过最小化![]() 的能量函数来优化TKRL。此外,在训练和评估中,类型信息也被视为类型约束。
的能量函数来优化TKRL。此外,在训练和评估中,类型信息也被视为类型约束。
利用知识图补全和三重分类的方法对Freebase基准数据集上的TKRL模型进行了评价。实验结果表明,与所有基线相比,TKRL在两个任务上都有显著和一致的改进,特别是在长尾分布情况下,验证了TKRL建模KGs的能力。
2.相关工作
2.1基于翻译的模型
近年来,知识图的表示学习有了很大的进展。TransE [Bordes等人,2013]将实体和关系投射到相同的连续低维向量空间中,将关系解释为头部和尾部实体之间的翻译操作。TransE假设尾t的嵌入应该在h+r的附近。TransE是有效和高效的,而简单的翻译操作可能会导致建模更复杂的关系如1到n, n到1和n到n的问题。
为了解决这个问题,TransH [Wang等人,2014b]将关系解释为特定于关系的超平面上的翻译操作,允许实体在不同的关系中有不同的距离。TransR [Lin et al., 2015b]直接在独立的实体和关系空间中建模实体和关系,在判断实体之间的距离时,将实体从实体空间投影到特定于关系的空间。TransD [Ji et al., 2015]提出了实体和关系同时构建的动态映射矩阵,同时考虑了实体和关系的多样性。此外,[林等,2015a;Gu et al., 2015]还将多步关系路径信息编码为KG表示学习。然而,这些模型只关注三元组中的信息,忽略了实体类型中的丰富信息,而TKRL模型将考虑实体类型中的丰富信息。
2.2多源信息学习
多源信息,如文本信息和类型信息,被认为是嵌入在三元组中的结构化信息的补充,对KGs中的RL具有重要意义。NTN [Socher等人,2013]将 3-way tensors编码到神经网络中,并将实体表示为实体名称中单词嵌入的平均。王等,2014a;Zhong等人,2015]通过使用维基百科锚、实体名称或实体描述的对齐模型,将实体和单词编码到联合连续向量空间中。DKRL [Xie等人,2016]提出了基于描述的实体表示,用CBOW或CNN从实体描述中构建实体,这能够在零样本场景中建模实体。
位于层次实体类型中的丰富信息对KGs也很重要,尽管它刚刚引起关注。[Krompaß et al., 2015]认为实体类型是KG潜变量模型中的硬约束,但类型信息没有显式编码到KG表示中,他们的方法没有考虑实体类型的层次结构。此外,硬约束可能存在噪声和类型信息不完整的问题,这在现实KGs中很常见,因此我们提出了TKRL模型来克服这些不足。据我们所知,TKRL是第一个借助层次结构将类型信息显式编码为KGs中的多个表示形式的方法。
3.方法
为了利用实体类型中丰富的信息,我们在构造实体的投影矩阵时考虑了类型信息,并使用两个分层类型编码器建模分层结构。此外,在训练和评估中,类型信息也被用作关系特定的类型约束。
3.1分层类型结构
层次类型信息意味着一个实体在不同场景中可能扮演不同的角色,这对知识图中的表示学习具有重要意义。大多数典型的知识图(例如Freebase和DBpedia)拥有它们自己的实体类型信息,或者可以通过实体对齐从大型百科全书(如Wikipedia)收集这些信息。这些类型通常是用分层结构构造的,在这种结构中,不同粒度的语义概念被视为不同层中的子类型。大多数实体都有不止一种层次类型。图1显示了层次类型结构的简单示例。

3.2总的架构
现有的基于翻译的模型在知识图中表现良好,但很少能充分利用位于实体类型中的丰富信息。TransE表示低维向量空间中的实体和关系,并将关系解释为实体之间的转换操作。然而,TransE在建模N-to-1、1-to-N和N-to-N关系时存在问题,因为每个实体在每个场景中只有一种表示。例如,威廉·莎士比亚有多种类型(例如e.g. book/author, award/award nominee and music/artist),并在不同类型下表现出不同的属性。我们认为,每个实体在不同的场景中,作为自身从不同角度的反映,应该有不同的表征。

3.3分层编码器
为了将分层类型信息编码到表示学习中,我们首先提出了一种类型编码器的一般形式,为每个实体构造投影矩阵。其次,提出了两种先进的编码器,利用了层次结构中的内部连接和特定关系类型信息中的先验知识。
类型编码器的一般形式

递归层次编码器

加权层次编码器

3.4目标形式化

3.5信息类型约束
我们使用分层类型编码器来构建特定于类型的投影矩阵,将实体映射到不同场景中的不同语义向量空间。此外,我们不仅可以将类型信息用作投影矩阵,还可以借助特定于关系的类型信息作为约束。我们提出了在训练和评估中使用类型信息作为约束的两种方法。
训练的类型限制
在训练中,我们从E中的所有实体中选取概率相等的负实体样本。在这种情况下,具有相同类型的实体倾向于聚集并具有相似的表示,这实际上成为实体预测错误的主要原因。为了解决这一问题,我们提出了一种称为软类型约束(Soft Type Constraint, STC)的负采样方法。STC提高了受关系特定的类型信息约束的具有相同类型的实体的选择概率,从而扩大了相似实体之间的距离。我们没有像[Krompaß et al., 2015]那样设置可能会干扰相似实体聚类的硬约束,而是使用了软约束,其中选择相同类型的实体的概率如下:

评估的类型约束
除了训练中的类型约束外,我们还可以利用信息作为评估中的类型约束。头部和尾部实体应该遵循特定于关系的类型信息提供的类型约束,这是很直观的。我们可以在评估中简单地删除不符合类型约束的候选者。然而,TCE的性能主要基于特定于关系的类型信息的正确性和完整性,因为类型约束可能是不完整的,甚至是错误的,这可能导致预测失误。在评价中,我们将展示TCE在辅助实验中的作用。
3.6优化与实现细节


实现细节
我们通过查找KG来收集实体和特定于关系的类型信息的类型实例。为了减少KGs中不完全性的影响,我们还采用了[Krompaß等人,2015]中提出的局部封闭世界假设(LCWA)作为补充方法。在LCW A中,所有出现在head(或tail)中具有相同关系的实体都应该用相同的类型分配。根据[Wang et al., 2014b],在选择负样本时,我们实施了两种策略(即“unif”和“bern”),用相等或不同的概率替换头或尾。考虑到效率,我们采用多线程版本进行学习。
4.实验
4.1数据集和实验设置
数据集
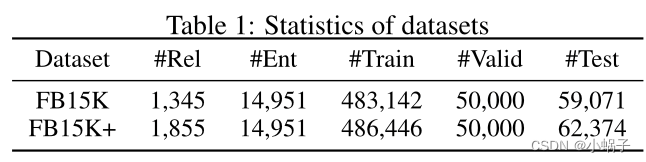
在本文中,我们首先使用一个典型的知识图FB15K [Bordes等人,2013]来评估我们的知识图补全和三重分类模型。FB15K是一个从Freebase [Bollacker et al., 2008]提取的数据集,包含14,951个实体,1,345个关系和592,213个三元组。接下来[Bordes等人,2013],我们将这些三元组分为训练集、验证集和测试集。
至于类型信息,我们收集了FB15K中位于type/instance字段中的实体的所有类型实例,以及位于 rdf-schema#domain和rdf-schema#range字段中的特定于关系的类型信息。我们还过滤了从未出现在提取的关系特定类型信息中的类型实例,因为这些类型对FB15K中的关系影响很小。经过筛选,我们有571种类型。FB15K中的所有实体至少有一种层次类型,类型的平均数量约为8。
FB15K中的实体和关系是有限的,它们应该在Freebase中至少有100次提及[Bordes等人,2013]。然而,由于长尾效应,现实世界中KGs中的关系和实体比FB15K要稀少得多。为了进一步展示我们的模型在现实分布中的优势,我们构建了FB15K+,它包含FB15K中相同的实体以及这些实体之间的几乎所有关系。我们只丢弃只出现过一次的关系,因为它们不可能同时存在于训练集和测试集中。新增的6,607个三元组被分为列集和测试集,其中每个关系在列集中至少被提及一次。FB15K+过滤后有806种。数据集的统计情况如表1所示。
实验设置
在评估中,我们实现了TransE和TransR进行比较。对于TransE,我们用L1范数改进了它们的不相似度量,并在负采样时替换了关系和实体。我们还使用“bern伯尔尼”替换具有不同概率跟随的头部或尾部[Wang et al., 2014b]。对于TransR,我们直接使用[Lin等人,2015b]中给出的发布代码,并利用负采样中的关系替换来获得更好的关系预测性能。TransE和TransR都用他们论文中报道的最佳参数进行训练。对于其他基准,包括RESCAL [Nickel等,2011;2012], SE [Bordes等,2011],SME [Bordes等,2012;2014]和LFM [Jenatton et al., 2012],我们直接使用[Lin et al., 2015b]中报道的结果。
我们用小批量SGD训练TKRL模型。对于参数,我们在{20,240,1200,4800}中选择批大小B,在{0.5,1.0,1.5,2.0}中选择margin γ。我们还将实体和关系的维数设为相同的n,并将所有投影矩阵设为n × n。对于学习率λ,我们可以选择一个固定的学习率如下[Bordes et al., 2013;Lin等人,2015b]或设计一个灵活的学习率,该学习率将通过迭代下降。对于WHE,我们在{0.1,0.15,0.2}之间选择子类型之间的降权η。对于类型约束中的k,我们在{5,10,15}中进行选择。模型的优化配置为:B = 4800, γ = 1.0, η = 0.1, k = 10, λ设计采用线性递减策略,取值范围为0.0025 ~ 0.0001。TKRL和TransR使用预先训练的TransE (unif)模型初始化的实体和关系进行训练。为了比较公平,所有模型都在相同的维数n = 50下训练。
4.2知识图谱补全
评估协议
知识图补全的目的是在缺少一个h, r, t时补全一个三重(h, r, t),在[Bordes et al.2011;2012;2013]。我们的评价指标有两个:(1)正确实体或关系的平均排名;(2)正确答案排名前10(实体题)或前1(关系题)的比例。我们还遵循两个评估设置,即" raw "和" filter "。
我们对FB15K进行评估,并将任务分为两个子任务:实体预测和关系预测。为了公平的比较,所有模型的评价条件都是相同的。我们还使用了类型约束评价方法(TCE)和一个新的长尾分布数据集作为辅助实验。
实体的预测
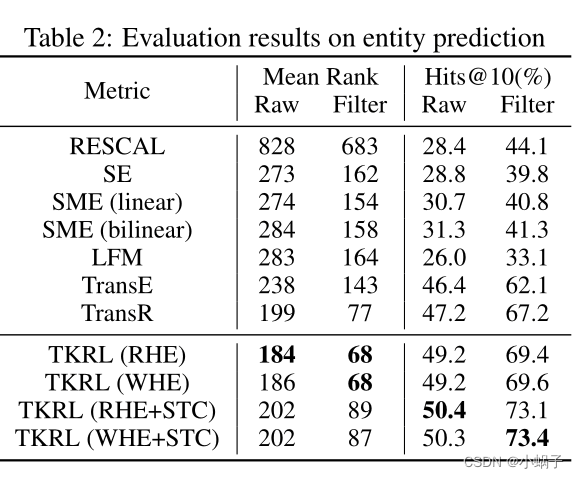
实体预测结果如表2所示。从结果中我们观察到:(1)RHE和WHE在平均排名和Hits@10上都显著优于所有基线。结果表明,将层次类型信息成功地编码到实体和关系嵌入中,可以改善知识图的表示学习。(2) WHE+STC的性能最好,与Hits@10中的TransR相比提高了约6.2%,这种由软类型约束(Soft Type Constraint, STC)提供的改进也可以在RHE中找到。这是因为STC增加了负采样时与黄金值类型相同的实体被选中的概率,从而拉大了相同类型实体之间的距离,从而降低了这些相似实体造成的误差。然而,STC有副作用,它可能会导致更高的平均排名,因为一些错误预测的实例具有极高的排名会显著提高平均排名。(3)类型信息无论是以投影矩阵的形式还是类型约束的形式,都可以为KGs的RL提供显著的补充。
关系预测
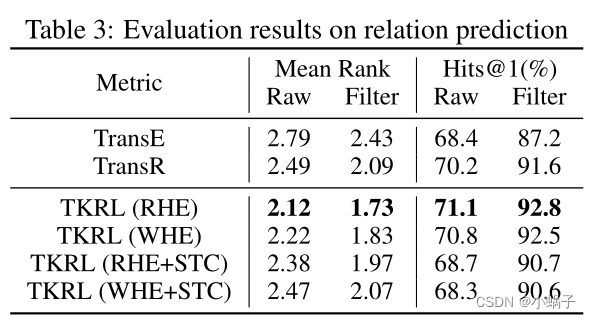
关系预测结果如表3所示。我们实现了两个典型的模型,包括TransE和TransR作为基线。从表3可以看出:(1)RHE和WHE在平均排名和Hits@10上都显著优于TransE和TransR,其中RHE的表现最好。结果表明,RHE在关系预测方面优于WHE,在实体预测方面优于WHE。(2)由于相同类型的实体之间的距离较长,可能导致实体聚类的混乱,STC降低了关系预测的性能。尽管如此,所有带有STC的模型仍然优于TransE,这表明类型信息作为约束的积极影响。
评估的类型约束
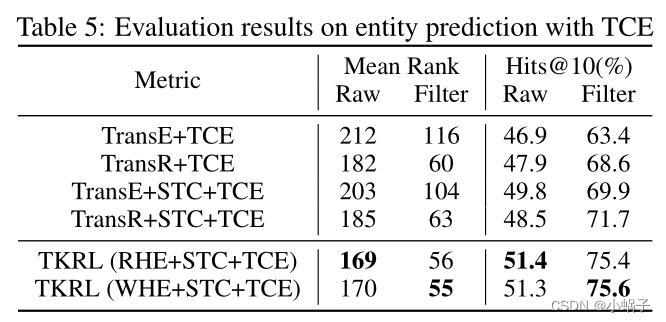
训练中的类型约束已被证明是有效的,而类型约束在评估(TCE)可以在特定关系的类型信息相对完整的情况下获得更好的实体预测性能。为了进行公平的比较,我们在STC和TCE的帮助下实现基线。从表5的结果可以看出:(1)与表2中不使用TCE的模型相比,使用TCE的所有模型的性能都有更好的提高,并且与STC结合后的改善更为显著。这是因为TCE去掉了不符合类型约束的候选项,而STC则细化了相似实体之间的差异。(2) TKRL模型优于所有基线,即使与使用STC的增强版本相比,这意味着分层类型编码器的重要性。
Knowledge Graph Completion with Long Tail
现实世界KG的表示学习受到长尾分布的影响。我们构建了FB15K+,它包含了FB15K中几乎所有实体之间的关系以及对应的三元组,来模拟真实KGs中的分布。从表4中我们可以观察到:(1)即使在没有STC的情况下,WHE在所有条件下都显著且持续优于TransE和TransR。(2)与fr <= 10的TransR相比,WHE在实体和关系预测上分别提高了5.8%和4.5%,而在所有三元组上分别提高了2.0%和0.9%。结果表明,TKRL比TransR具有优势,特别是在低频关系下,因此在模拟具有真实分布的KGs时更稳健。

4.3三元组分类
三重分类的目的是确认一个三重(h, r, t)是否正确。这种二元分类任务在[Socher等人,2013;王等,2014b;Lin等人,2015b]进行评估。
评估协议
我们在FB15K上评估这个任务。由于FB15K没有显式的负三元组,我们按照[Socher等人,2013]中使用的相同协议构建负三元组。分类策略如下:我们为每个关系设置不同的关系特定阈值δr。对于一个三元组(h, r, t),如果E(h, r, t)的不相似度评分低于δr,则预测三重函数为正,否则为负。关系特定阈值δr通过最大化所有三元组的分类精度在验证集上相应的r进行优化。
结果
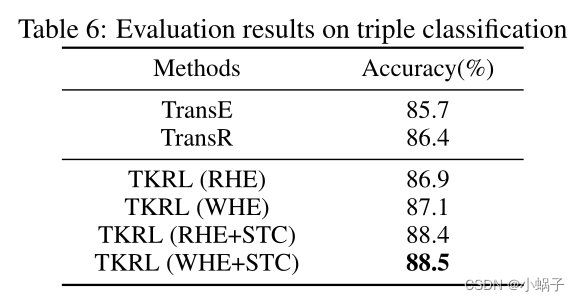
三元组分类评价结果如表6所示。由表6可知:(1)TKRL模型优于所有基线,且WHE+STC的性能最好,证实了TKRL在三元组分类中优于基线。(2) STC同时提高了RHE和WHE的性能,这表明锐化相同类型实体之间的差异对三重分类有显著的帮助。
5.结论和未来工作
本文提出了一种TKRL模型,用于分层类型知识图的表示学习。我们认为类型信息是实体的投影矩阵,它是由两个层次类型编码器构造的。此外,类型信息也被视为培训和评估的约束条件。在实验中,我们在知识图补全和三元组分类两个任务上对模型进行了评价。实验结果表明,类型信息在两种任务中都具有显著性,特别是在长尾分布情况下,TKRL模型能够将层次类型信息编码为KG表示。
未来我们将探索以下研究方向:(1)TKRL模型在KGs的表示学习中只考虑类型信息,而有丰富的图像和文本形式的信息可以整合到我们的模型中。我们将在未来探索这些丰富信息的优势。(2)可以引入更多的分层类型结构,如维基百科类别,以引入更深层的分层信息,而分层类型编码器可以进一步改进,采用更复杂的针对分层结构设计的算法。
















 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











