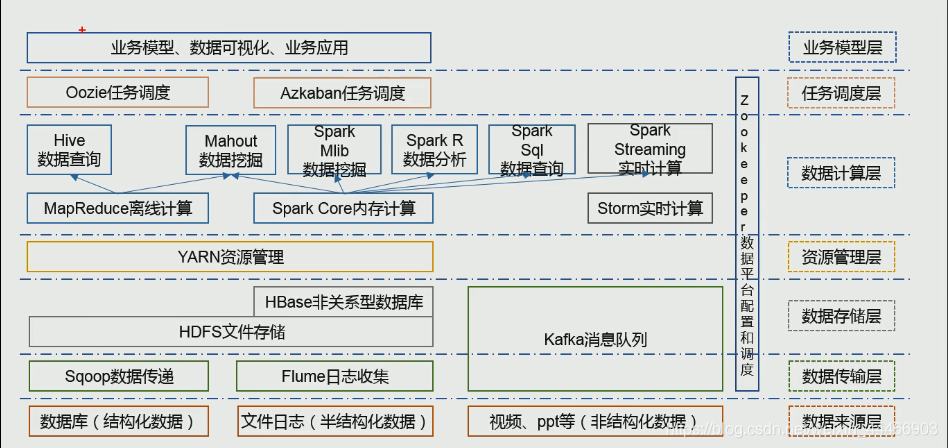
一、大数据技术生态体系示意图 1. 数据来源层 结构化数据:订单,支付记录等。 半结构化数据:用户行为等。 2.数据传输层 数据不会直接进入到数据分析体系,需要传输层进行数据的传递。 3.数据存储层 HDFS是主流,Kafka可以缓存数据。 4.资源管理层 分配计算资源,CPU,内存,网络等。 5.数据计算层 Hive到Spark Sql是离线计算,比如用于月度总结,年度总结 Spark Streaming: 准实时计算,是分批处理,一小批计算一次,近似实时 Storm : 实时计算 6.任务调度层 整个集群系统一时间运行着成百上千的任务,需要任务调度层来协调他们的运行








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






