









 本文介绍了作者尝试TinyAgent项目的过程,涉及代码解析、使用趋动云进行低成本训练,以及对LLM.py中调用大模型和工具的详细说明。作者还讨论了代码中的思考过程和局限性,以及如何利用GPTAPI进行进一步实验。
本文介绍了作者尝试TinyAgent项目的过程,涉及代码解析、使用趋动云进行低成本训练,以及对LLM.py中调用大模型和工具的详细说明。作者还讨论了代码中的思考过程和局限性,以及如何利用GPTAPI进行进一步实验。
最近忙了许多事,终于抽出时间学习一下Agent了,就尝试尝试了Datawhale某不要葱姜蒜作者的大作TingAgent来作为非科班的入门项目。
TinyAgent/Agent.py at master · KMnO4-zx/TinyAgent · GitHub![]() https://github.com/KMnO4-zx/TinyAgent/blob/master/Agent.py粗略看了一下,这个项目比MetaGPT的代码简单不少,非常适合入门以摸清Agent简单框架的使用!
https://github.com/KMnO4-zx/TinyAgent/blob/master/Agent.py粗略看了一下,这个项目比MetaGPT的代码简单不少,非常适合入门以摸清Agent简单框架的使用!
这次使用的云计算厂商是比较便宜的趋动云,真的很慷慨,送了我不少,很适合新手免费训练!
另外,欢迎使用我的链接进行注册哦!
趋动云![]() https://growthdata.virtaicloud.com/t/aB在此不打广告了。
https://growthdata.virtaicloud.com/t/aB在此不打广告了。
本文一共三个部分,第一个部分简单地跑一下结果看效果怎么样,第二部分解析一下代码,第三部分尝试用GPT的API来试试Agent(略)。
第一部分
第一步:创建项目,进入开发环境

选择一个镜像,选Python3.10的

这里我选了两个模型
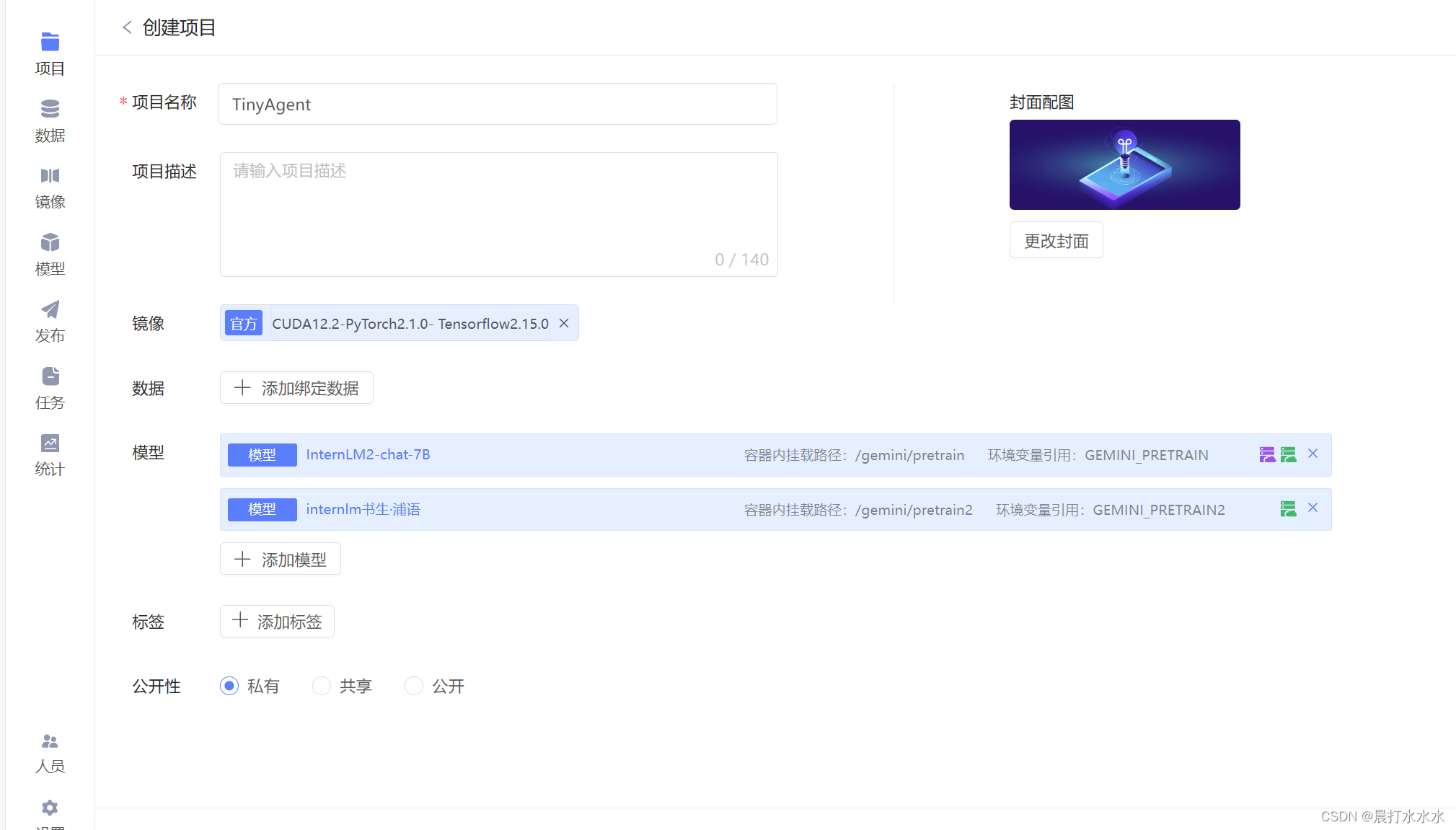
首先初始化配置,由于先看项目所以先选较便宜的,1.99的那个
 等待开发环境按钮变亮,然后点“进入开发环境”
等待开发环境按钮变亮,然后点“进入开发环境”

第二步、下载项目,安装一些必要的包
点击terminal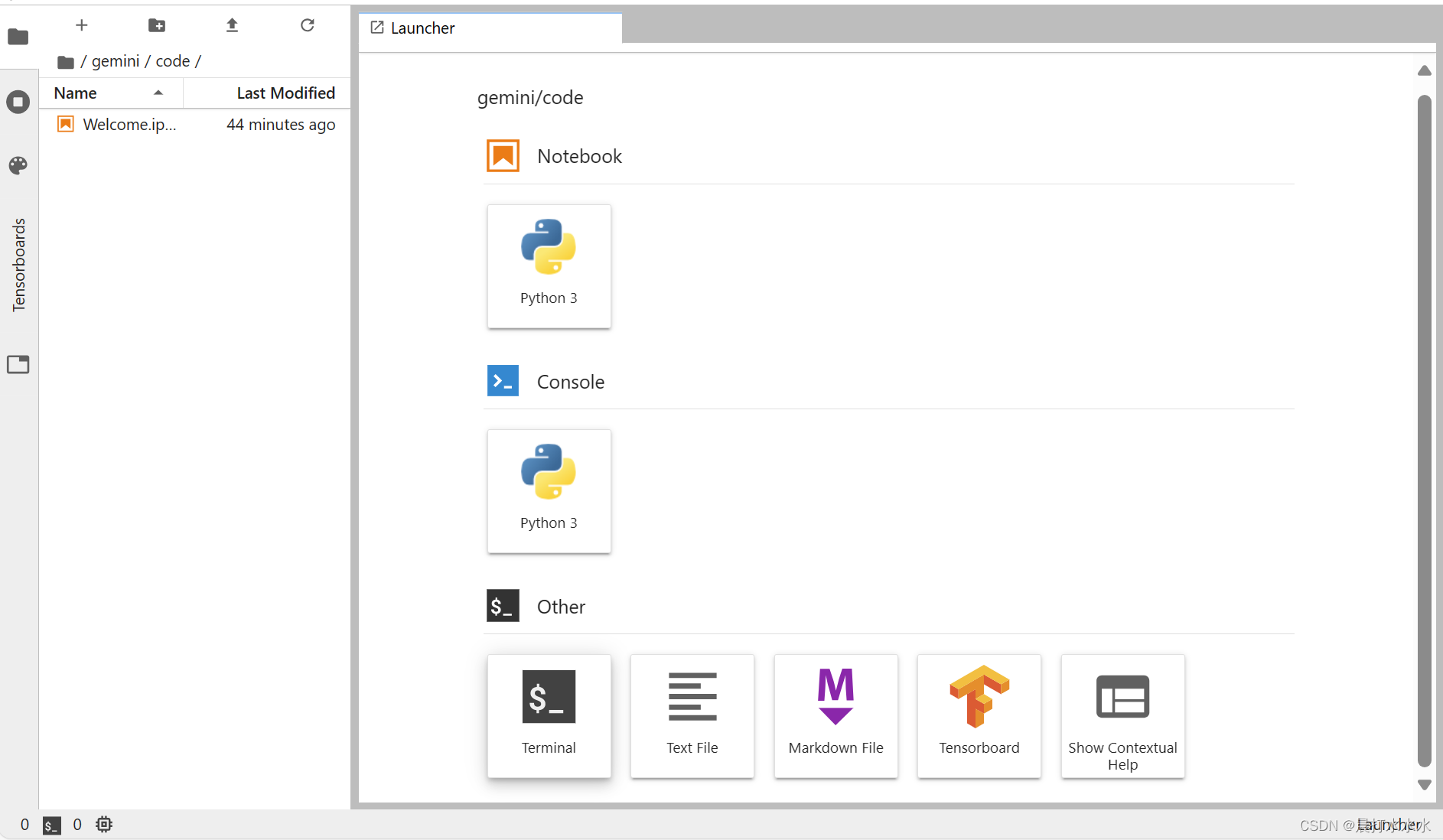 首先从github上下载这个项目,然后安装必要的库
首先从github上下载这个项目,然后安装必要的库
cd /gemini/code
git clone https://github.com/KMnO4-zx/TinyAgent.git
cd TinyAgent
pip install -r requirements.txt
我这里已经安装过了
 之后我们先跑一下demo文件试试,先将第二个cell里面的路径改为本次模型所在的位置,选择internlm2-7b的模型,Agent.py里面的路径也改一下。添加一下serper的APIKey(首先自己去申请)。访问以下网址自行注册!
之后我们先跑一下demo文件试试,先将第二个cell里面的路径改为本次模型所在的位置,选择internlm2-7b的模型,Agent.py里面的路径也改一下。添加一下serper的APIKey(首先自己去申请)。访问以下网址自行注册!
Serper - Dashboard![]() https://serper.dev/dashboard
https://serper.dev/dashboard
![]()

下面这个图里面表示加载完成了(有等一段时间哦),同时你可以查看自己的CPU状态,会有很大变化。

这里出一道题给它,回答的不错
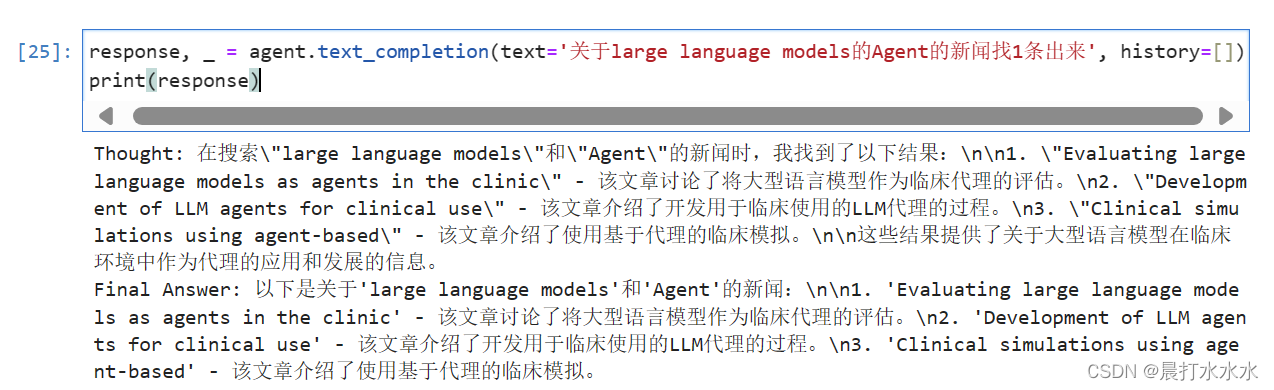
再来一道

但是也有局限,稍微复杂点的解决不了。这里也不清楚原因是什么,可能是7B的模型还不太行。
 第二部分:解析代码
第二部分:解析代码
这个项目代码主要部分分为4个,一个是tool.py用来调用工具的,一个是LLM.py用来调用大模型的,一个是Agent.py用于组合大模型和搜索工具的,最后一个agent_demo.ipynb用于做小案例演示的。
Tool.py
这个文件很简单,Tools类中有三个函数,第一个不说了;第二个和第一个紧密相连,用_tools是不想别人直接访问,但可以通过self.toolConfig获取;第三个函数其实就是搜索所得结果,具体写法见serper官网,类似如下:

LLM.py
这份代码文件具体解释详见TinyAgent项目readme文件,总的来说就是加载模型,与模型对话获得结果。
Agent.py
这份代码有三个函数值得细讲:
def parse_latest_plugin_call(self, text):
plugin_name, plugin_args = '', ''
# 下面使用rfind找最后一个出现的是因为所要求的格式可能有多个Action,Action Input,Observation
i = text.rfind('\nAction:')
j = text.rfind('\nAction Input:')
k = text.rfind('\nObservation:')
if 0 <= i < j: # If the text has `Action` and `Action input`,
if k < j: # but does not contain `Observation`,
text = text.rstrip() + '\nObservation:' # Add it back.
k = text.rfind('\nObservation:')
plugin_name = text[i + len('\nAction:') : j].strip()
plugin_args = text[j + len('\nAction Input:') : k].strip()
text = text[:k + len("\nObservation:")]
return plugin_name, plugin_args, text
def call_plugin(self, plugin_name, plugin_args):
plugin_args = json5.loads(plugin_args)
if plugin_name == 'google_search':
return '\nObservation:' + self.tool.google_search(**plugin_args)
def text_completion(self, text, history=[]):
text = "\nQuestion:" + text
response, his = self.model.chat(text, history, self.system_prompt)
# 一般和大模型对话到上面这一行就完了
# 下面这一行是为了将大模型按格式所回答的内容,包括其选择的“工具”、“工具所用参数”、“最后一个Observation前所有文本”
plugin_name, plugin_args, response = self.parse_latest_plugin_call(response)
# 如果“工具”不为空字符串,那么进行谷歌询问,并将返回的答案放到“Observation”后
if plugin_name:
response += self.call_plugin(plugin_name, plugin_args)
# 再将包含“Observation及其结果”的文本给大模型,让其进一步判断
# 1. observation的循环在哪里?
response, his = self.model.chat(response, history, self.system_prompt)
return response, his首先是parse_latest_plugin,这个函数是将第一次问答模型后的回答进行切片,获得Action(Plugin_name)、Action Input(Plugin_args)以及Observation及其之前的文本(text)
刚刚的这个图,虽然回答不对,但可以用来举例好对这个函数所获内容有更好了解:
Action后面是google_search,也即是名字;Action Input后面是传给谷歌搜索的参数。而之所以截取observation及之前的内容,是observation后表示大模型观察的内容,也就是谷歌搜索返回的答案。这个感觉很像RAG。
其实刚刚上面已经提到了,为了给大模型一个观察内容,我们需要谷歌搜索的发挥结果,而这也是函数call_plugin的作用。
最后是text_completion函数,如果不用tools,一般就在第二行差不多就结束了,因为普通一次问大模型就问一次就可以了。但后面先用函数parse_latest_plugin将第一次回答切分,得到大模型所得到的一些选择,包括工具名及参数之类的,然后谷歌搜索返回结果,再加到处理后的回答中。最后再一次通过处理后的回答询问大模型,大模型就会根据format直接返回observation之后的内容,比如Thought以及Final answer(如果大模型不抽风的话)。
在学习这些代码的时候我产生了一个疑问:
1. 这些代码似乎没有吧format里面的循环思考体现出来?
第三部分
这一部分其实更简单了,直接将LLM.py中复杂的内容,换成调用大模型API即可。另外还可以尝试使用其他工具。















 1274
1274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









