









0、大量的malloc/free小内存所带来的弊端
1.弊端
- malloc/free的底层是系统调用,频繁的系统调用所带来的用户内核态切换花费大量时间, 大大降低系统执行效率;
- 频繁的申请小内存, 带来的大量内存碎片, 内存使用率低下且导致无法申请大块的内存;
- 没有内存回收机制, 很容易造成内存泄漏;
2.内存池的作用
- 内存池提前预先分配大块内存,统一释放,极大的减少了malloc 和 free 等函数的调用;
- 内存池每次请求分配大小适度的内存块,最大避免了碎片的产生;
- 在生命周期结束后统一释放内存,极大的避免了内存泄露的发生;
3.内存碎片出现原因解释
- 内部内存碎片: 因为所有的内存分配必须起始于可被 4、8 或 16 整除的地址。假设当某个客户请求一个 43 字节的内存块时,因为没有适合大小的内存,所以它可能会获得 44字节、48字节等稍大一点的字节,因此由所需大小四舍五入而产生的多余空间就叫内部碎片。
- 外部内存碎片:频繁的分配与回收物理页面会导致大量的、连续且小的页面块夹杂在已分配的页面中间,就会产生外部碎片。
解决「外部内存碎片」的问题就是内存交换。可以把程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里。
1、内存池的演变
1、 最简单的内存分配器
描述:做一个链表指向空闲内存,分配就是取出一块来,改写链表。释放就是放回到链表里面,并做好归并。
优点: 实现简单。
缺点: 分配时搜索合适的内存块效率低,释放回归内存后归并消耗大,实际中不实用。
2、定长内存分配器
描述:每个固定内存分配器里面有两个链表,OpenList 用于存储未分配的空闲对象,CloseList用于存储已分配的内存对象,分配时从 OpenList 中取出一个对象放到 CloseList 里并且返回给用户,释放就是从 CloseList 移回到 OpenList。
优点: 分配和释放的效率高。
缺点: 只能解决定长的内存需求,长期占着内存没有释放。
3、哈希映射的FreeList 池
描述:在定长分配器的基础上,按照不同对象大小(8,16,32,64,128,256,512,1k…64K),构造多个固定内存分配器,分配内存时根据要申请内存大小进行对齐,然后查表决定到底由哪个分配器负责。
优点:分配和释放的效率高,可以解决一定长度内的问题。
缺点:存在内碎片的问题,长期占着内存没有释放。多线程并发场景下,锁竞争激烈,效率降低。
2、并发内存池的设计
2.1 内存池结构
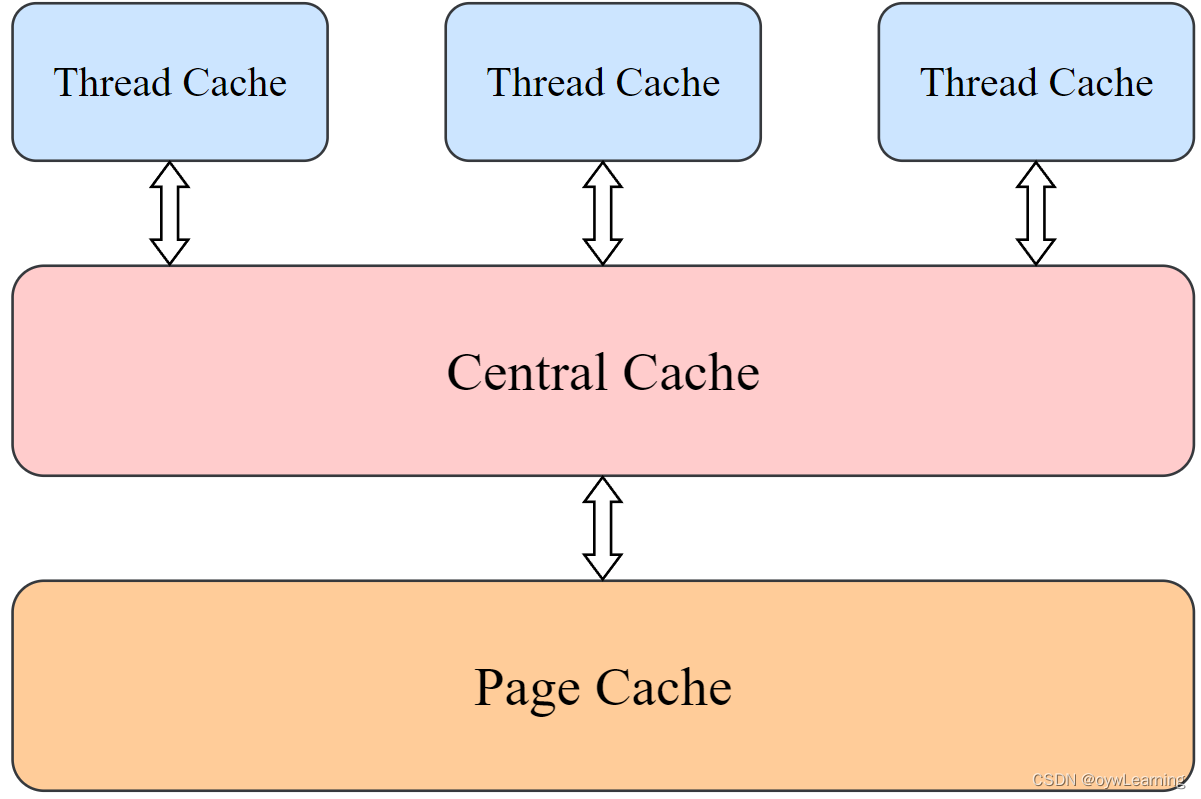
- 第一层是Thread Cache,线程缓存是每个线程独有的,在这里设计的是用于小于64k的内存分配,线程在这里申请不需要加锁,每一个线程都有自己独立的cache,这也就是这个项目并发高效的地方。
- 第二层是Central Cache,在这里是所有线程共享的,它起着承上启下的作用,Thread Cache是按需要从Central Cache中获取对象,它就要起着平衡多个线程按需调度的作用,既可以将内存对象分配给Thread Cache来的每个线程,又可以将线程归还回来的内存进行管理。Central Cache是存在竞争的,所以在这里取内存对象的时候是需要加锁的,但是锁的力度可以控制得很小。
- 第三层是Page Cache,存储的是以页为单位存储及分配的,Central Cache没有内存对象(Span)时,从Page Cache分配出一定数量的Page ,并切割成定长大小的小块内存,分配给Central Cache。Page Cache会回收Central Cache满足条件的Span(使用计数为0)对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
2.2 Thread Cache层

申请内存:
- 当在Thread Cache中申请内存块(size<=64k)时,首先计算size大小的内存块所对应的freelist链表在freelist数组中的位置,如果对应freelist链表中有内存块时,直接从freelist[i]中Pop出内存块,时间复杂度是O(1),且没有锁竞争。
- 当freelist[i]中没有内存块时,则批量从Central Cache中获取一定数量的块,插入到自由链表并返回一个size大小的内存块。
释放内存:
- 当释放内存小于64k时将内存释放回Thread Cache,首先计算size大小的内存块所对应的freelist链表在freelist数组中的位置,将内存块Push到freelist[i]。
- 当链表的长度过长,空闲的内存块数量过多,也就是超过freelist链表最大容纳内存块数目时,则将所有内存块回收到Central Cache。
class ThreadCache
{
private:
Freelist _freelist[NLISTS];//自由链表数组
public:
//申请内存对象
void* Allocate(size_t size);
//释放内存对象
void Deallocate(void* ptr, size_t size);
//从中心缓存获取对象
void* FetchFromCentralCache(size_t index, size_t size);
//释放内存对象时,对应索引的自由链表过长时,回收内存到中心缓存
void ListTooLong(Freelist* list, size_t size);
};
//**静态的,不是所有可见 !!!!**
//每个线程有个自己的指针, 用(_declspec (thread)),我们在使用时,每次来都是自己的,就不用加锁了
//每个线程都有自己的tlslist
_declspec (thread) static ThreadCache* tlslist = nullptr;
/*
* 从中心缓存获取对象,每一次取批量的数据。
* 因为每次到CentralCache申请内存的时候是需要加锁的,所以一次就多申请一些内存块,
* 防止每次到CentralCache去内存块的时候,多次加锁造成效率问题
*/
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
//获得指向该索引对应自由链表对象的指针
Freelist* freelist = &_freelist[index];
/* 不是每次申请10个,而是进行慢增长的过程,申请内存块数量原则如下:
(1)单个对象越小,申请内存块的数量越多
(2)单个对象越大,申请内存块的数量越少
(3)申请次数越多,申请内存块的数量越多
(4)申请次数越少,申请内存块的数量越少*/
size_t maxsize = freelist->MaxSize();
//获得需要从中心缓冲中拉取内存块的数量
size_t numtomove = min(SizeClass::NumMoveSize(size), maxsize);
//start, end分别表示取出来的内存的开始地址和结束地址
//取出来的内存是一个链在一起的内存对象,需要首尾标识
void* start = nullptr;
void* end = nullptr;
//batchsize表示实际取出来的size大小缓存的个数
//batchsize可能小于numtomove,因为可能对应的中心缓存中span对象的list内没有那么多大小的缓存块
size_t batchsize = CentralCache::Getinstence()->FetchRangeObj(start, end, numtomove, size);
//当申请的缓存个数大于1,则舍弃申请的缓存链表的第一个内存节点【为什么!!!】
if (batchsize > 1)
{
freelist->PushRange(NEXT_OBJ(start), end, batchsize - 1);
}
//当threadCache层申请的size大小缓存达到链表容纳节点最大值时,将链表容量扩增1
if (batchsize >= freelist->MaxSize())
{
freelist->SetMaxSize(maxsize + 1);
}
//返回申请的多个内存组成链表的首地址
return start;
}
/*
* 释放内存对象时,对应索引的自由链表过长时,回收内存到中心缓存
*/
void ThreadCache::ListTooLong(Freelist* freelist, size_t size)
{
//将freelist自由链表中内存对象个数置0
//返回指向自由链表首地址的指针
void* start = freelist->PopRange();
//将其释放回中心缓存的对应spanlist的span中
CentralCache::Getinstence()->ReleaseListToSpans(start, size);
}
/*
* 申请内存对象,从数组中对应索引的自由链表中弹出一个对象,作为申请的内存对象使用
*/
void* ThreadCache::Allocate(size_t size)
{
//计算size大小的对象应该对应自由链表数组中哪个索引
size_t index = SizeClass::Index(size);
//获得指向该索引对应自由链表对象的指针
Freelist* freelist = &_freelist[index];
//判断链表是否为空,如果链表不为空,则从中弹出一个对象指针
if (!freelist->Empty())
{
return freelist->Pop();
}
//如果自由链表为空,就要去中心缓存中拿取内存对象,一次拿取多个,防止多次去取而加锁带来的开销
/*【均衡策略】:每次中心堆分配给ThreadCache对象的个数是个慢启动策略
随着取的次数增加而内存对象个数增加,防止一次给其他线程分配太多,而另一些线程申请
内存对象的时候必须去PageCache去取,带来效率问题。*/
else
{
//从中心缓存CenterCache中获取内存
return FetchFromCentralCache(index, SizeClass::Roundup(size));
}
}
/*
* 释放内存对象,将一个大小为size的对象压入对应索引的自由链表中
*/
void ThreadCache::Deallocate(void* ptr, size_t size)
{
//计算size大小的对象应该对应自由链表数组中哪个索引
size_t index = SizeClass::Index(size);
//获得指向该索引对应自由链表对象的指针
Freelist* freelist = &_freelist[index];
//将对象压入对应的自由链表中(头插法)
freelist->Push(ptr);
//满足链表内当前对象个数大于设定链表内对象个数上限时
//释放一个批量的对象,释放回中心缓存CenterCache
if (freelist->Size() >= freelist->MaxSize())
{
ListTooLong(freelist, size);
}
}2.3 Central Cache层

申请内存:
- 当Thread Cache中没有内存时,就会批量向Central Cache申请一些内存对象,Central Cache有一个哈希映射的spanlist,spanlist中挂着span,从span中的list取出内存块给Thread Cache,这个过程是需要加锁的。
- Central Cache中没有非空的span时,则将空的span链在一起,向Page Cache申请一个newspan对象,将newspan对象中以页为单位的内存,切成需要的内存块大小,并链接起来,挂到newspan中。再将该newspan插入到Central Cache对应的spanlist链表中。
- Central Cache的span中有一个_usecount,每从span中分配一个内存块给Thread Cache,就++_usecount。
释放内存:
- 当Thread Cache过长或者线程销毁,则会将内存块释放回Central Cache中的,每个内存块被释放时,其所属span对象就会执行- -_usecount。
- 当_usecount减到0时则表示所有内存块都回到了span,则将span释放回Page Cache,如果span对象的内存块总量超过128页,则直接向系统释放该span对象,否则Page Cache中会对该span对象前后相邻的空闲页进行合并。
特别关心:怎么才能将Thread Cache中的内存对象还给它原来的span呢?
答:可以在Page Cache中维护一个pair<pageid, span对象>的映射,当Span Cache给Central Cache分配一个span时,将这个映射更新到unordered_map中去,在Thread Cache还给Central Cache时,可以查这个unordered_map找到对应的span。pageid = 地址void* pir/(1<<12),其中(1<<12)为1页所占字节数。
/*
* 进行资源的均衡,对于ThreadCache的某个资源过剩时,可以回收ThreadCache内部的内存
* 从而可以分配给其它的ThreadCache;当threadCache对应size的自由链表中没有空闲内存块,要从中心缓存获取
*
* 只有一个中心缓存,对于所有的线程来获取内存的时候都应该是一个中心缓存,
* 所以对于中心缓存可以使用单例模式来进行创建中心缓存的类,
* 对于中心缓存来说要加锁。
*/
//设计成单例模式
class CentralCache
{
public:
static CentralCache* Getinstence()
{
return &_inst;
}
//从page cache获取一个span
Span* GetOneSpan(SpanList& spanlist, size_t byte_size);
//从中心缓存中获取一定数量的对象给threadCache
size_t FetchRangeObj(void*& start, void*& end, size_t n, size_t byte_size);
//将一定数量的对象释放给span
void ReleaseListToSpans(void* start, size_t size);
private:
SpanList _spanlist[NLISTS];
private:
//声明构造函数,防止默认构造
CentralCache() {}
//强制默认不生成复制构造函数,防止浅拷贝
CentralCache(CentralCache&) = delete;
static CentralCache _inst;
};
CentralCache CentralCache::_inst;
/*
*从CenterCache获取一个span
*/
Span* CentralCache::GetOneSpan(SpanList& spanlist, size_t byte_size)
{
//遍历当前span链表,找出空闲的span对象,找到则直接返回该空闲对象节点
Span* span = spanlist.Begin();
while (span != spanlist.End())
{
//span链表节点中的list成员,标志该节点是否空闲,list!=nullptr,说明该span节点还有内存可分配
if (span->_list != nullptr)
return span;
else
span = span->_next;
}
//走到这,说明当前中心缓存的span链表中没有获取到空闲的span节点对象,到pageCache层获取newspan
Span* newspan = pageCache::GetInstence()->NewSpan(SizeClass::NumMovePage(byte_size));
/*将newspan对象切分成需要的内存块并链接起来*/
//通过对newspan节点的pageid计算获得newspan对象的起始地址
char* cur = (char*)(newspan->_pageid << PAGE_SHIFT);
//通过newspan的起始地址+newspan对象的大小,获得newspan对象的终止地址
char* end = cur + (newspan->_npage << PAGE_SHIFT);
//将新分配的span对象[cur, end]分割成由一个个byte_size大小的内存块串联起来的链表,存放在newspan对象的list成员中
newspan->_list = cur;//span中可分配内存块链表首地址
newspan->_objsize = byte_size;//span中可分配内存块的单位大小
//串联链表
while (cur + byte_size < end)
{
char* next = cur + byte_size;
NEXT_OBJ(cur) = next;
cur = next;
}
NEXT_OBJ(cur) = nullptr;
//往中心缓存对应索引的spanlist链表中插入新span对象
spanlist.PushFront(newspan);
return newspan;
}
/*
*从中心缓存中获取一定数量的内存块给threadCache
*/
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t n, size_t byte_size)
{
//获取size大小的内存块对应的spanlist链索引
size_t index = SizeClass::Index(byte_size);
SpanList& spanlist = _spanlist[index];//赋值->拷贝构造
//记得加锁
//spanlist.Lock();
std::unique_lock<std::mutex> lock(spanlist._mutex);
//获取一个span用于分割出多个byte_size大小的内存块
Span* span = GetOneSpan(spanlist, byte_size);
//从span对象的list链表中获取range[start, end]的n个内存块
size_t batchsize = 0;
void* prev = nullptr;//提前保存前一个
void* cur = span->_list;//用cur来遍历,往后走
for (size_t i = 0; i < n; ++i)
{
prev = cur;
cur = NEXT_OBJ(cur);
++batchsize;//累积byte_size大小缓存的个数
//随时判断cur是否为空,为空的话,提前停止
if (cur == nullptr)
break;
}
//赋值被分配缓存的首地址和尾地址
start = span->_list;
end = prev;
//从中心缓存的span节点中,获取[start, end]区间内的多个byte_size大小缓存
//此时移动span节点中的list链表指针,如果到end->next处,如果end==nullptr说明当前span节点已全部用完
span->_list = cur;
//累计当前span对象被使用的byte_size大小内存块的数量
span->_usecount += batchsize;
//如果当前span对象节点已经被分配完,则将空的span移到spanlist链表最后,保持非空的span在前面
if (span->_list == nullptr)
{
spanlist.Erase(span);
spanlist.PushBack(span);
}
//spanlist.Unlock();
//返回分配的byte_size大小缓存数量
return batchsize;
}
/*
*将一定数量的内存块释放给span
*/
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{
//计算分配该内存块的span所在的spanlist链表位置
size_t index = SizeClass::Index(size);
SpanList& spanlist = _spanlist[index];
//将锁放在循环外面
// CentralCache:对当前桶进行加锁(桶锁),减小锁的粒度
// PageCache:必须对整个SpanList全局加锁
// 因为可能存在多个线程同时去系统申请内存的情况
//spanlist.Lock();
std::unique_lock<std::mutex> lock(spanlist._mutex);
//采用头插法,逐个内存块地释放到size大小内存块对应的span对象的list链表中
while (start)
{
void* next = NEXT_OBJ(start);
//记得加锁
//spanlist.Lock(); // 构成了很多的锁竞争
//获取内存块start地址对应的页号,根据对应页号再map中的映射关系找到该内存块所属span对象
//因为链表串联的不同内存块,在虚拟地址上可能不属于同一页
Span* span = PageCache::GetInstence()->MapObjectToSpan(start);
//头插法,将当前被释放节点的尾部指向原span对象list链表的第一个内存块
NEXT_OBJ(start) = span->_list;
//更新span对象得第一个内存块指针
span->_list = start;
//当一个span的对象全部释放回来的时候,将span还给pagecache,并且做页合并
if (--span->_usecount == 0)
{
//将span节点从当前spanlist链表中移除(并未释放被移除的span对象)
spanlist.Erase(span);
PageCache::GetInstence()->ReleaseSpanToPageCache(span);
}
//spanlist.Unlock();
start = next;
}
//spanlist.Unlock();
}2.4 Page Cache层

申请内存:
- 当Central Cache向Page cache申请内存时,Page cache先检查对应spanlist链表有没有span,如果没有则向更大页寻找一个span,如果找到则分裂成两个。
- 比如:申请的是4page,4page后面没有挂span,则向后面寻找更大的span,假设在10page spanlist位置找到一个span,则将10page span分裂为一个4page span和一个6page span。将4page span返回给Central Cache,并将6page span所对应的span插入对应的spanlist中。
- 如果找到128 page spanlist都没有合适的span,则向系统使用mmap、brk或者是VirtualAlloc等方式申请128 page span挂在自由链表中,再重复1中的过程。
释放内存:
- 如果Central Cache释放回一个span,如果该span内存块总量大于128页,则直接将该span释放回系统中。
- 否则依次寻找span的前后_pageid的span,看是否可以合并,如果合并继续向前寻找。这样就可以将切小的内存合并收缩成大的span,减少内存碎片。当合并span内存块总量大于128页,将该span释放回系统中。
//对于Page Cache也要设置为单例,对于Central Cache获取span的时候
//每次都是从同一个page数组中获取span
//单例模式
class PageCache
{
public:
static PageCache* GetInstence()
{
return &_inst;
}
Span* AllocBigPageObj(size_t size);
void FreeBigPageObj(void* ptr, Span* span);
Span* _NewSpan(size_t n);
Span* NewSpan(size_t n);//获取的是以页为单位
//获取从对象到span的映射
Span* MapObjectToSpan(void* obj);
//释放空间span回到PageCache,并合并相邻的span
void ReleaseSpanToPageCache(Span* span);
private:
//spanlist数组
SpanList _spanlist[NPAGES];
//std::map<PageID, Span*> _idspanmap;
//map中存放<pageid, span>的映射关系,其中pageid可以由地址ptr计算得来
//因此可以认为map中存放“地址ptr与span对象的映射”
std::unordered_map<PageID, Span*> _idspanmap;
//页缓存锁
std::mutex _mutex;
private:
//声明构造函数,防止默认构造
PageCache() {}
//强制默认不生成复制构造函数,防止浅拷贝
PageCache(const PageCache&) = delete;
static PageCache _inst;
};
PageCache PageCache::_inst;
/*
*大对象申请,直接从系统
*/
Span* PageCache::AllocBigPageObj(size_t size)
{
//需要申请的内存大小大于64k
assert(size > MAX_BYTES);
//将需要分配的内存大小进行内存对齐,即转换成大于等于size的内存最小单位倍数
size = SizeClass::_Roundup(size, PAGE_SHIFT);
//将内存大小转换成页数量
size_t npage = size >> PAGE_SHIFT;
//情况一:需要申请的内存小于128k
if (npage < NPAGES)
{
//尝试在pageCache层的Spanlist中找到空闲链表中的Span返回
Span* span = NewSpan(npage);
span->_objsize = size;
return span;
}
//情况二:当申请的内存大于128k,则直接向系统申请内存
else
{
void* ptr = VirtualAlloc(0, npage << PAGE_SHIFT,MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
if (ptr == nullptr)
throw std::bad_alloc();
//构造一个Span对象描述从系统申请来的内存
Span* span = new Span;
span->_npage = npage;//Span对象的可分配内存页数
span->_pageid = (PageID)ptr >> PAGE_SHIFT; //Span对象的pageid
span->_objsize = npage << PAGE_SHIFT;//Span对象的可分配内存大小
//构建该span对象与pageid的映射关系
_idspanmap[span->_pageid] = span;
//返回申请的内存所构成的span对象
return span;
}
}
/*
*释放大对象,直接从系统
*/
void PageCache::FreeBigPageObj(void* ptr, Span* span)
{
//计算释放的Span对象的内存大小
size_t npage = span->_objsize >> PAGE_SHIFT;
//情况二:当释放的内存小于128页,直接从内存释放,即在pageCache中合并
if (npage < NPAGES)
{
span->_objsize = 0;
ReleaseSpanToPageCache(span);
}
//情况二:当释放的内存大于128页,直接从内存释放
else
{
_idspanmap.erase(npage);
delete span;
VirtualFree(ptr, 0, MEM_RELEASE);
}
}
/*
*新申请一个n页大小的Span
*/
Span* PageCache::NewSpan(size_t n)
{
// 加锁,防止多个线程同时到PageCache中申请span
// 这里必须是给全局加锁,不能单独的给每个桶加锁
// 如果对应桶没有span,是需要向系统申请的
// 可能存在多个线程同时向系统申请内存的可能
std::unique_lock<std::mutex> lock(_mutex);
return _NewSpan(n);
}
/*
*新申请一个n页大小的Span
*/
Span* PageCache::_NewSpan(size_t n)
{
//第一步首先确定需要从pageCache获取的页数小于等于128页
assert(n < NPAGES);
//判断索引n对应的span链表是否为空,如果不为空则弹出一个span节点返回给中心缓存
if (!_spanlist[n].Empty())
return _spanlist[n].PopFront();
//走到这说明索引为n的span链表为空,此时需要往n+1方向获取空闲span节点
for (size_t i = n + 1; i < NPAGES; ++i)
{
if (!_spanlist[i].Empty())
{
//找到第一个空闲span节点,将其从spanlist链表中弹出
Span* span = _spanlist[i].PopFront();
//创建新的span对象,承接所需的n*page大小的span对象
Span* splist = new Span;
//新span对象的pageid为源span对象pageid
splist->_pageid = span->_pageid;
//初始化新span对象的页数npage
splist->_npage = n;
//源span对象的pageid增加n
span->_pageid = span->_pageid + n;
//源span对象的页数减n
span->_npage = span->_npage - n;
//在pageid与span的映射map上,对应[span->pageid, span->pageid+n]位置映射对象为splist
for (size_t i = 0; i < n; ++i)
_idspanmap[splist->_pageid + i] = splist;
//将源span对象分割n*page后的span对象压入到页缓存中对应页数的spanlist链表中
_spanlist[span->_npage].PushFront(span);
//返回新span对象
return splist;
}
}
Span* span = new Span;
// 到这里说明SpanList中没有合适的span,只能向系统申请128页的内存
#ifdef _WIN32
void* ptr = VirtualAlloc(0, (NPAGES - 1) * (1 << PAGE_SHIFT), MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
// brk
#endif
//初始化span对象的pageid = 对象首地址整数化/每页的字节数
//因为两个span对象的整数化地址差即是相差对应字节数,字节数/页字节数 == 页数
span->_pageid = (PageID)ptr >> PAGE_SHIFT;
//设置新span对象的页数为128
span->_npage = NPAGES - 1;
//在pageid与span的映射map上,对应[span->pageid, span->pageid+128]位置映射对象为新对象span
for (size_t i = 0; i < span->_npage; ++i)
_idspanmap[span->_pageid + i] = span;
//将新对象压入到索引为128的spanlist链表中
_spanlist[span->_npage].PushFront(span); //方括号
return _NewSpan(n);
}
/*
*获取从对象到span的映射
*/
Span* PageCache::MapObjectToSpan(void* obj)
{
//计算页号
PageID id = (PageID)obj >> PAGE_SHIFT;
//根据页号pageid获得对象obj的映射span对象
auto it = _idspanmap.find(id);
if (it != _idspanmap.end())
{
//返回该pageid对应的span对象
return it->second;
}
else
{
assert(false);
return nullptr;
}
}
/*
*将一个Span从PageCache释放
*情况一:当释放的内存是大于128页,直接将内存归还给操作系统,不能合并
*情况二:当释放的内存是小于128页,将当前Span与前后空闲Span合并
*/
void PageCache::ReleaseSpanToPageCache(Span* cur)
{
// 必须上全局锁,可能多个线程一起从ThreadCache中归还数据
std::unique_lock<std::mutex> lock(_mutex);
// 当释放的内存是大于128页,直接将内存归还给操作系统,不能合并
if (cur->_npage >= NPAGES)
{
//将span根据spanid计算处实际地址ptr
void* ptr = (void*)(cur->_pageid << PAGE_SHIFT);
// 归还之前,先删除掉页到span的映射
_idspanmap.erase(cur->_pageid);
VirtualFree(ptr, 0, MEM_RELEASE);
delete cur;
return;
}
// 向前合并
while (1)
{
//超过128页则不合并
PageID curid = cur->_pageid;
PageID previd = curid - 1;
auto it = _idspanmap.find(previd);
// 没有找到
if (it == _idspanmap.end())
break;
// 前一个span不空闲,即还有内存空间再threadCache中未被释放的
if (it->second->_usecount != 0)
break;
Span* prev = it->second;
//超过128页则不合并
if (cur->_npage + prev->_npage > NPAGES - 1)
break;
// 先把prev从spanlist链表中移除
_spanlist[prev->_npage].Erase(prev);
// cur与prev合并
prev->_npage += cur->_npage;
//修正id->span的映射关系
for (PageID i = 0; i < cur->_npage; ++i)
{
_idspanmap[cur->_pageid + i] = prev;
}
delete cur;
// 继续向前合并
cur = prev;
}
//向后合并
while (1)
{
//超过128页则不合并
PageID curid = cur->_pageid;
PageID nextid = curid + cur->_npage;
auto it = _idspanmap.find(nextid);
if (it == _idspanmap.end())
break;
if (it->second->_usecount != 0)
break;
Span* next = it->second;
//超过128页则不合并
if (cur->_npage + next->_npage >= NPAGES - 1)
break;
_spanlist[next->_npage].Erase(next);
cur->_npage += next->_npage;
//修正id->Span的映射关系
for (PageID i = 0; i < next->_npage; ++i)
{
_idspanmap[next->_pageid + i] = cur;
}
delete next;
}
// 最后将合并好的span插入到当前的spanlist链中
_spanlist[cur->_npage].PushFront(cur);
}
2.5 向系统申请内存
- VirtualAlloc https://baike.baidu.com/item/VirtualAlloc/1606859?fr=aladdin
- brk和mmap https://www.cnblogs.com/vinozly/p/5489138.html
3. 项目不足及扩展学习
- 项目的独立性不足:
- 不足:当前实现的项目中我们并没有完全脱离malloc,比如在内存池自身数据结构的管理中,如SpanList中的span等结构,我们还是使用的new Span这样的操作,new的底层使用的是malloc,所以还不足以替换malloc,因为们本身没有完全脱离它。
- 解决方案:项目中增加一个定长的ObjectPool的对象池,对象池的内存直接使用brk、VirarulAlloc等向系统申请,new Span替换成对象池申请内存。这样就完全脱离的malloc,就可以替换掉malloc。
- 平台及兼容性:
- linux等系统下面,需要将VirtualAlloc替换为brk等。
- x64系统下面,当前的实现支持不足。比如:id查找Span得到的映射,我们当前使用的是map<pageid,Span*>。在64位系统下面,这个数据结构在性能和内存等方面都是撑不住。需要改进后基数树。
具体参考:基数树(radix tree)_uestc-leon的博客-CSDN博客_基数树
附录源码,包含构造freelist对象、span对象、spanlist对象,以及内存对齐等相关代码:
const size_t MAX_BYTES = 64 * 1024; //ThreadCache可申请的最大内存
const size_t NLISTS = 184; //每个线程的threadCache数组元素总的有多少个,由对齐规则计算得来
const size_t PAGE_SHIFT = 12; //用于在字节于页之间的单位转换
const size_t NPAGES = 129; //是否直接从系统中申请/释放的页数上限
/*
* 获取指向obj对象下一对象的指针的引用
*/
inline static void*& NEXT_OBJ(void* obj)
{
//先强转为void**,然后解引用就是一个void*
//(1)先强转void**,此时obj为指向指针的指针
//(2)解引用后获得对象内部的指向的指针,即指向obj下一对象的指针
return *((void**)obj);
}
/*
* ThreadCache层使用
* 公共的FreeList对象,每个对象还有多个接口,用一个类来管理自由链表
*/
class Freelist
{
private:
void* _list = nullptr; //始终指向自由链表的第一个对象
size_t _size = 0; //自由链表当前大小
size_t _maxsize = 1;//自由链表最大允许的大小(链表内对象个数超过该值,则将去合并释放到中心缓存CenterCache中)
public:
//将对象头插法插入链表头部,更新链表内对象个数
void Push(void* obj)
{
NEXT_OBJ(obj) = _list;
_list = obj;
++_size;
}
//采用头插法像链表list中插入[start,end]范围内串联的节点链表
void PushRange(void* start, void* end, size_t n)
{
NEXT_OBJ(end) = _list;
_list = start;
_size += n;
}
//将对象从链表头部弹出,并返回被弹出的对象指针
void* Pop() //把对象弹出去
{
void* obj = _list;
_list = NEXT_OBJ(obj);
--_size;
return obj;
}
//将链表内的对象个数置零,返回链表首地址副本
void* PopRange()
{
_size = 0;
void* list = _list;
_list = nullptr;
return list;
}
//list指针永远指向自由链表的头节点,大概list指针指向nullptr,说明改链表为空
bool Empty()
{
return _list == nullptr;
}
//返回当前链表中对象的数量
size_t Size()
{
return _size;
}
//返回自由链表的容量大小
size_t MaxSize()
{
return _maxsize;
}
//设置自由链表的容量
void SetMaxSize(size_t maxsize)
{
_maxsize = maxsize;
}
};
/*
*专门用来计算大小位置的类
*/
class SizeClass
{
public:
//获取size大小的对象在FreeList数组中的位置,其中align表示要对齐应该移动的位数
inline static size_t _Index(size_t size, size_t align)
{
size_t alignnum = 1 << align; //库里实现的方法
return ((size + alignnum - 1) >> align) - 1;
}
//用于内存对齐,找出第一个大于等于size的内存单位大小的倍数
inline static size_t _Roundup(size_t size, size_t align)
{
size_t alignnum = 1 << align;
return (size + alignnum - 1) & ~(alignnum - 1);
}
public:
// 控制在12%左右的内碎片浪费
// [1,128] 8byte对齐 freelist[0,16)
// [129,1024] 16byte对齐 freelist[16,72)
// [1025,8*1024] 128byte对齐 freelist[72,128)
// [8*1024+1,64*1024] 1024byte对齐 freelist[128,184)
//获取size大小的内存对象所对应的freelist链表在数组中的索引
inline static size_t Index(size_t size)
{
assert(size <= MAX_BYTES);
// 每个区间有多少个链
static int group_array[4] = { 16, 56, 56, 56 };
if (size <= 128)
{
return _Index(size, 3);
}
else if (size <= 1024)
{
return _Index(size - 128, 4) + group_array[0];
}
else if (size <= 8192)
{
return _Index(size - 1024, 7) + group_array[0] + group_array[1];
}
else//if (size <= 65536)
{
return _Index(size - 8 * 1024, 10) + group_array[0] + group_array[1] + group_array[2];
}
}
// 对齐大小计算,向上取整
static inline size_t Roundup(size_t bytes)
{
assert(bytes <= MAX_BYTES);
if (bytes <= 128) {
return _Roundup(bytes, 3);
}
else if (bytes <= 1024) {
return _Roundup(bytes, 4);
}
else if (bytes <= 8192) {
return _Roundup(bytes, 7);
}
else {//if (bytes <= 65536){
return _Roundup(bytes, 10);
}
}
//动态计算从中心缓存分配多少个内存对象到ThreadCache中
static size_t NumMoveSize(size_t size)
{
if (size == 0)
return 0;
//MAX_BYTES为64k,需要分配的对象size越大,分配的内存对象越少
//上限为512, 下限为2
int num = (int)(MAX_BYTES / size);
if (num < 2)
num = 2;
if (num > 512)
num = 512;
return num;
}
// 根据size计算中心缓存要从页缓存获取多大的span对象
static size_t NumMovePage(size_t size)
{
//第一步先计算需要分配的size对象数量
size_t num = NumMoveSize(size);
//计算分配num个size所需的页数
size_t npage = num * size;
npage >>= PAGE_SHIFT;
//确保至少分配1页
if (npage == 0)
npage = 1;
return npage;
}
};
#ifdef _WIN32
typedef size_t PageID;
#else
typedef long long PageID;
#endif //_WIN32
//页节点结构
struct Span
{
PageID _pageid = 0;//页号
size_t _npage = 0;//当前Span节点的页数
Span* _prev = nullptr; //指向当前页节点的上一节点的指针
Span* _next = nullptr;//指向当前页节点的下一节点的指针
void* _list = nullptr;//链接对象的自由链表,后面有对象就不为空,没有对象就是空
size_t _objsize = 0;//对象的大小
//页节点对象引用计数,分配一个对象给Thread Cache,就++usecount。
//当ThreadCache过长或者线程销毁,则会将内存释放回Central Cache中的,释放回来时--usecount。
//当usecount减到0时则表示所有对象都回到了span,则将Span释放回Page Cache
size_t _usecount = 0;//对象使用计数,
};
/*
* CenterCache层使用
* 公共的SpanList对象,每个对象还有多个接口,用一个类来管理双向带头循环链表
*/
class SpanList
{
public:
Span* _head;//双向循环链表的头节点,是个空节点,不分配内存大小
std::mutex _mutex;//中心内存使用互斥量
public:
/*构造函数,替代默认构造函数*/
SpanList()
{
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}
/*析构函数,释放链表的每个节点*/
~SpanList()
{
//head是个空节点,所以不用释放,直接从head->next开始释放
Span* cur = _head->_next;
while (cur != _head)
{
Span* next = cur->_next;
delete cur;
cur = next;
}
delete _head;
_head = nullptr;
}
//防止拷贝构造和赋值构造,将其封死,没有拷贝的必要,不然就自己会实现浅拷贝
//【由于对象内部涉及指针的成员变量,浅拷贝会造成一个指针被多次重复释放!!!】
SpanList(const SpanList&) = delete;
SpanList& operator=(const SpanList&) = delete;
/*左闭右开——返回第一个数据的指针*/
Span* Begin()
{
//因为head是一个空的头节点
return _head->_next;
}
/*左闭右开——返回最后一个的下一个指针*/
Span* End()
{
//因为head是一个空的头节点
return _head;
}
/*判断链表是否为空*/
bool Empty()
{
//当链表中第一个数据指针是空头节点,则说明该链表为空
return _head->_next == _head;
}
/*在cur位置的前面插入一个页节点newspan*/
void Insert(Span* cur, Span* newspan)
{
//获取当前节点的上一个节点指针
Span* prev = cur->_prev;
//按顺序排列pre newspan cur
prev->_next = newspan;
newspan->_next = cur;
newspan->_prev = prev;
cur->_prev = newspan;
}
/*假删除pos位置的节点,此处只是单纯的把pos拿出来,并没有释放掉,后面还有用处*/
void Erase(Span* cur)
{
Span* prev = cur->_prev;
Span* next = cur->_next;
prev->_next = next;
next->_prev = prev;
}
/*尾插*/
void PushBack(Span* newspan)
{
Insert(End(), newspan);
}
/*头插*/
void PushFront(Span* newspan)
{
Insert(Begin(), newspan);
}
/*尾删,实际是将尾部位置的节点拿出来*/
Span* PopBack()
{
Span* span = _head->_prev;
Erase(span);
return span;
}
/*头删,实际是将头部位置节点拿出来*/
Span* PopFront()
{
Span* span = _head->_next;
Erase(span);
return span;
}
/*给中心缓存CenterCache层上锁*/
void Lock()
{
_mutex.lock();
}
/*给中心缓存CenterCache层解锁*/
void Unlock()
{
_mutex.unlock();
}
};













 2179
2179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









