







上一章讲解了如何编写一个在GPU上并行执行的代码。但对于并行编程来说,最重要的一个方面就是,并行执行的各个部分如何通过相互协作来解决问题。本章主要就线程协作提供一种解决方案
文章目录
并行线程块的分解
之前有提到过CUDA运行时启动核函数的多个并行副本,这些并行副本称为线程块(Block)。
CUDA 运行时将把这些线程块分解为多个线程。当需要启动多个并行线程块时,只需将尖括号中的第一个参数由1改为想要启动的线程块数量。例如,在介绍矢量加法示例时,我们为矢量中的每个元素(共有N个元素)都启动了一个线程块,如下所示:
add<<<N,1>>>(dev_a, dev_b, dev_c);
在尖括号中,第二个参数表示CUDA运行时在每个线程块中创建的线程数量。上面这行代码表示在每个线程块中只启动一个线程。总共启动的线程数量可按以下公式计算:

事实上,我们也可以启动 N/2 个线程块,每个线程块包含2个线程,或者 N/4 个线程块,每个线程块包含4个线程,以此类推。
矢量求和
使用线程实现GPU上的矢量求和
这里我们启动 N 个线程,并且所有线程都在一个线程块中:
add<<<1,N>>>(dev_a, dev_b, dev_c);
然后之前在核函数中是通过线程块索引对输入数据和输出数据进行索引
int tid = blockIdx.x;
现在,只有一个线程块,因此需要通过线程索引来对数据进行索引
int tid = threadIdx.x;
其完整代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "../common/book.h"
#include <stdio.h>
#define N (33 * 1024)
__global__ void add(int* a, int* b, int* c) {
int tid = threadIdx.x;
if (tid < N)
c[tid] = a[tid] + b[tid];
}
int main()
{
int a[N], b[N], c[N];
int* dev_a, * dev_b, * dev_c;
//在GPU上分配内存
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_c, N * sizeof(int)));
//在CPU上为数组 'a' 和 'b' 赋值
for (int i = 0; i < N; i++) {
a[i] = i;
b[i] = i * i;
}
//将数组'a'和'b'复制到GPU
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice));
add << <1, N >> > (dev_a, dev_b, dev_c);
//将数组'c'从GPU复制到CPU
HANDLE_ERROR(cudaMemcpy(c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost));
//显示结果
for (int i = 0; i < N; i++) {
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
//释放在GPU上分配的内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
在GPU上对更长的矢量求和
我们知道硬件将线程块的数量限制为不超过65535。同样,对于启动核函数时每个线程块中的线程数量,硬件也进行了限制。具体地来说,最大的线程数量不能超过设备属性结构中 maxThreadsPerBlock 域的值,对于当前的许多图形处理器而言,这个限制值时每个线程块512个线程。因此,如何通过并行线程对长度大于512的矢量进行相加?在这种情况下,必须将线程与线程块结合起来才能实现这个计算。
与前面一样,这里需要改动两个地方:
- 核函数中的索引计算方法
- 核函数的调用方式
现在,我们需要多个线程块并且每个线程块中包含了多个线程,计算索引的方法看上去非常类似于将二维索引空间转换为线性空间的标准算法。
int tid = threadIdx.x + blockIdx.x * blockDim.x;
在上面的赋值语句中使用了一个新的内置变量,blockDim。对于所有线程块来说,这个变量是一个常数,保存的是线程块中每一维的线程数量。由于使用的是一维线程块,因此只需用到 blockDim.x。之前在 gridDim 中保存了一个类似的值,即在线程格中每一维的线程块数量。此外,gridDim 是二维的,而blockDim实际上是三维的。也就是说,CUDA运行时允许启动一个二维线程格,并且线程格中的每个线程块都是一个三维的线程数组。这是一种高维数组,虽然很少会用到这种高维索引,但如果需要也可以支持。
通过前面的运算来对线性数组中的数据进行索引是非常直观的。它可以帮助你从空间上来思考线程集合,这类似于一个二维的像素数组。下图给出了这种空间组织形式。
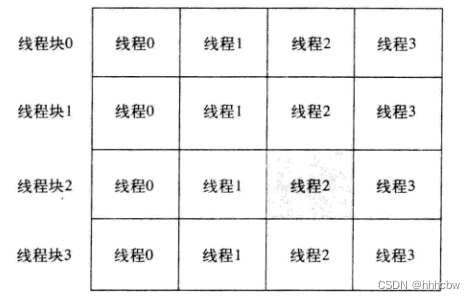
如果线程表示列,而线程块表示行,那么可以计算得到一个唯一的索引:将线程块索引blockIdx.x与每个线程块中的线程数量blockDim.x相乘,然后加上线程在线程块中的索引threadIdx.x。
另一处修改是核函数调用本身。虽然仍需要启动 N 个并行线程,但我们希望在多个线程块中启动它们,这样就不会超过 512 个线程的最大数量限制。其中一种解决方案是,将线程块的大小设置为某个固定数值,在这个示例中,我们每个线程块包含的线程数量固定为128。然后,可以启动 N/128 个线程块,这样总共就启动 N 个线程同时运行。
这里的问题在于,N/128 是一个整数除法。例如,如果 N 为 127,那么 N/128 等于0,因此将启动 0 个线程,而我们实际上也不会获得任何计算结果。事实上,当 N 不是 128 的整数倍时,启动的线程数量将少于预期数量,这种情况非常糟糕。所以,我们希望这个除法能够向上取整。
这里可以通过一种常见的技术在整数除法中实现这个功能,而不是调用 ceil(),而是计算 (N+127)/128 而不是 N/128。你也可以将这种算法理解为,计算大于或等于 N 的 128 的最小倍数。
我们选择了每个线程块拥有 128 个线程,因此使用以下的核函数调用:
add<<< (N+127)/128, 128 >>>(dev_a, dev_b, dev_c);
上面这行代码对除法进行了修改从而确保启动足够多的线程,因此当 N 不是 128 个整数倍时,将启动过多的线程。然而,在核函数中已经解决了这个问题。在访问输入数组和输出数组之前,必须检查线程的偏移是否位于 0 到 N 之间。
if (tid < N)
c[tid] = a[tid] + b[tid];
因此,当索引越过数组的边界时,例如当启动的并行线程数量不是 128 的整数倍时就会出现这种情况,那么核函数将自动停止执行计算。更重要的是,核函数不会对越过数组边界的内存进行读取或者写入。
在GPU上对任意长度的矢量求和
之前提到,线程格每一维的大小都不能超过 65535,那么对矢量加法的实现带来一个问题。如果启动 N/128 个线程块将矢量相加,那么当矢量的长度超过 65535x128=8388480 时,核函数调用会失败。
这个问题的解决方案非常简单,首先对核函数进行一些修改。
__global__ void add(int* a, int* b, int* c) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while (tid < N) {
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x;
}
}
这里使用了一个 while() 循环对数据进行迭代·,在线程计算完当前索引上的任务后,接着就需要对索引进行递增,其中递增的步长为线程格中正在运行的线程数量。这个数值等于每个线程块中的线程数量乘以线程格中线程块的数量,即 blockDim.x * gridDim.x。因此,递增语句如下所示:
tid += blockDim.x * gridDim.x;
之前提到过,当 (N+127)/128 大于 65535 时,核函数调用 add<<<(N+127)/128,128>>>(dev_a, dev_b, dev_c) 会失败。为了确保不会启动过多的线程块,我们将线程块的数量固定为某个较小的值。这里固定为128,每个线程块也固定包含128个线程。
add<<<128, 128>>>(dev_a, dev_b, dev_c);
完整代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "../common/book.h"
#include <stdio.h>
#define N (33 * 1024)
__global__ void add(int* a, int* b, int* c) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while (tid < N) {
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x;
}
}
int main()
{
int a[N], b[N], c[N];
int* dev_a, * dev_b, * dev_c;
//在GPU上分配内存
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_c, N * sizeof(int)));
//在CPU上为数组 'a' 和 'b' 赋值
for (int i = 0; i < N; i++) {
a[i] = i;
b[i] = i * i;
}
//将数组'a'和'b'复制到GPU
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice));
add << <128, 128 >> > (dev_a, dev_b, dev_c);
//将数组'c'从GPU复制到CPU
HANDLE_ERROR(cudaMemcpy(c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost));
//显示结果
for (int i = 0; i < N; i++) {
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
//释放在GPU上分配的内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
在GPU上使用线程实现波纹效果
这里已经将所有不相关的动画代码都封装到辅助函数中,这样你就无需预先掌握任何图形技术或动画技术,使用前要导入 /common/cpu_anim.h
struct DataBlock {
unsigned char* dev_bitmap;
CPUAnimBitmap* bitmap;
};
// 释放在GPU上分配的内存
void cleanup(DataBlock* d) {
cudaFree(d->dev_bitmap);
}
int main()
{
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
HANDLE_ERROR(cudaMalloc((void**)&data.dev_bitmap, bitmap.image_size()));
bitmap.anim_and_exit((void(*)(void*, int))generate_frame, (void(*)(void*))cleanup);
return 0;
}
main() 函数的大部分复杂性都被隐藏在辅助类 CPUAnimBitmap 中。这里再次遵循了前面采用的模式,即首先调用 cudaMalloc(),然后执行设备代码对内存内容进行计算,最后调用 cudaFree() 来释放这些内存。
在这个示例中,将把 “执行设备代码对内存内容进行计算” 这个步骤变得更复杂一些。我们将一个指向 generate_frame() 的函数指针传递给 anim_and_exit()。每当要生成一帧新的动画时,都将调用函数 generate_frame()。
void generate_frame(DataBlock* d, int ticks) {
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel << <blocks, threads >> > (d->dev_bitmap, ticks);
HANDLE_ERROR(cudaMemcpy(d->bitmap->get_ptr(), d->dev_bitmap, d->bitmap->image_size(), cudaMemcpyDeviceToHost));
}
这里只有 4 行代码,但其中包含 CUDA C 的所有重要概念。首先,代码声明了两个二维变量,blocks 和 threads。从名字就可以看出,变量 blocks 表示在线程格中包含的并行线程块数量。变量 threads 表示在每个线程块中包含的线程数量。由于生成的是一幅图像,因此使用了二维索引,并且每个线程都有一个唯一的索引 (x,y),这样可以很容易与输出图像中的像素一一对应起来。这里选择的线程块中包含了一个大小为 16 x 16 的线程数组。如果图像有 DIM x DIM 个像素,那么就需要启动 DIM/16 x DIM/16个线程块,从而使每个像素对应一个线程。
在声明了表示线程块数量和线程数量的变量后,接下来就需要调用核函数来计算像素值。
kernel<<< blocks, threads >>>(d->dev_bitmap, ticks);
核函数需要包含两个参数。首先,它需要一个指针来指向保存输出像素值的设备内存。这是一个全局变量,它指向的内存是在 main() 中分配的。然而,这个变量只是对于主机代码来说是 ”全局的“,因此我们需要将其作为一个参数传递进去,从而确保设备代码能够访问这个变量。
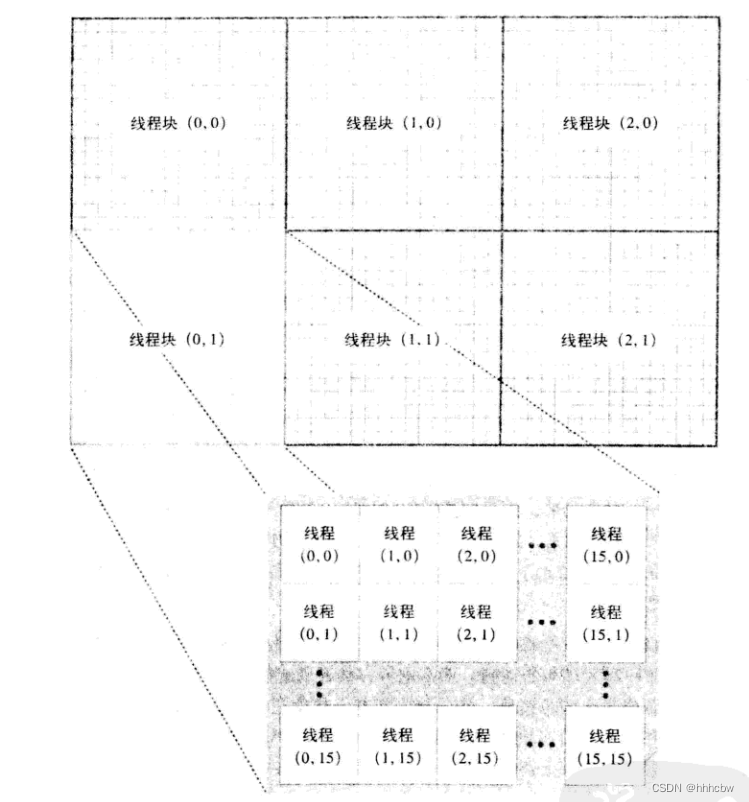
其次,核函数需要知道当前的动画时间以便生成正确的帧。在 CPUAnimBitmap 的代码中将当前时间 ticks 传递给 generate_frame(),因此只需直接将这个值传递给核函数。
核函数的代码如下所示:
__global__ void kernel(unsigned char* ptr, int ticks) {
// 将threadIdx/BlockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
// 现在计算这个位置的值
float fx = x - DIM / 2;
float fy = y - DIM / 2;
float d = sqrtf(fx * fx + fy * fy);
unsigned char grey = (unsigned char)(128.0f + 127.0f * cos(d / 10.0f - ticks / 7.0f) / (d / 10.0f + 1.0f));
ptr[offset * 4 + 0] = grey;
ptr[offset * 4 + 1] = grey;
ptr[offset * 4 + 2] = grey;
ptr[offset * 4 + 3] = 255;
}
前三行代码是核函数中最重要的代码
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
在这几行代码中,每个线程都得到了它在线程块中的索引以及这个线程块在线程格中的索引,并将这两个值转换为图形中的唯一索引 (x , y)。例如,当位于线程格中 (12, 8) 处的线程块中的 (3, 5) 处的线程开始执行时,它知道在其左边有 12 个线程块,而在它上边有 8 个线程块。在这个线程块内,(3,5) 处线程的左边有 3 个线程,并且在它上边有 5 个线程。由于每个线程块都有 16 个线程,这就意味着这个线程有:

这个计算就是计算前两行中的 x 和 y,也是将线程和线程块的索引映射到图像坐标的算法。然后,我们对 x 和 y 的值进行线性化从而得到输出缓冲区中的一个偏移。
int offset = x + y * blockDim.x * gridDim.x;
既然我们知道了线程要计算的像素值 (x, y),以及在何时计算这个值,那么就可以计算 (x, y, t) 的任意函数,并将这个值保存在输出缓冲区中。在这里的情况中,函数将生产一个随时间变化的正弦曲线 “波纹”。
float fx = x - DIM / 2;
float fy = y - DIM / 2;
float d = sqrtf(fx * fx + fy * fy);
unsigned char grey = (unsigned char)(128.0f + 127.0f * cos(d / 10.0f - ticks / 7.0f) / (d / 10.0f + 1.0f));
完整代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "../common/cpu_anim.h"
#include "../common/book.h"
#include <stdio.h>
#define DIM 256
struct DataBlock {
unsigned char* dev_bitmap;
CPUAnimBitmap* bitmap;
};
__global__ void kernel(unsigned char* ptr, int ticks) {
// 将threadIdx/BlockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
// 现在计算这个位置的值
float fx = x - DIM / 2;
float fy = y - DIM / 2;
float d = sqrtf(fx * fx + fy * fy);
unsigned char grey = (unsigned char)(128.0f + 127.0f * cos(d / 10.0f - ticks / 7.0f) / (d / 10.0f + 1.0f));
ptr[offset * 4 + 0] = grey;
ptr[offset * 4 + 1] = grey;
ptr[offset * 4 + 2] = grey;
ptr[offset * 4 + 3] = 255;
}
// 释放在GPU上分配的内存
void cleanup(DataBlock* d) {
cudaFree(d->dev_bitmap);
}
void generate_frame(DataBlock* d, int ticks) {
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel << <blocks, threads >> > (d->dev_bitmap, ticks);
HANDLE_ERROR(cudaMemcpy(d->bitmap->get_ptr(), d->dev_bitmap, d->bitmap->image_size(), cudaMemcpyDeviceToHost));
}
int main()
{
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
HANDLE_ERROR(cudaMalloc((void**)&data.dev_bitmap, bitmap.image_size()));
bitmap.anim_and_exit((void(*)(void*, int))generate_frame, (void(*)(void*))cleanup);
return 0;
}
运行结果如下(其中的一帧)

共享内存和同步
到目前为止,将线程块分解为线程的目的只是为了解决线程块数量的硬件限制。这是一个很勉强的动机,因为这完全可以由CUDA运行时在幕后自动完成。显然,还有其他的原因需要将线程块分解为多个线程。
CUDA C 支持共享内存。这块内存引出了对于 C 语言的另一个扩展,这个扩展类似于 __device__ 和 __global__。在编写代码时,你可以将 CUDA C 的关键字 __share__ 添加到变量声明中,这将使这个变量驻留在共享内存中。
对于在GPU上启动的每个线程块,CUDA C 编译器都将创建该变量的一个副本。线程块中的每个线程都共享这块内存,但线程却无法看到也不能修改其他线程块的变量副本。这就实现了一种非常好的方式,使得一个线程块中的多个线程能够在计算上进行通信和协作。而且,共享内存缓冲区驻留在物理GPU上,而不是驻留在GPU之外的系统内存中。因此,在访问共享内存时的延迟要远远低于访问普通缓冲区的延迟,使得共享内存像每个线程块的高速缓存或者中间结果暂存器那样高效。
但是如果想要在线程之间进行通信,那么还需要一种机制来实现线程之间的同步。例如,线程 A 将一个值写入到共享内存,并且我们希望线程 B 对这个值进行一些操作,那么将发生竞态条件(Race Condition),在这种情况下,代码执行结果的正确性将取决于硬件的不确定性。
点积运算
点积运算公式如下(包含4个元素的矢量),结果是一个标量
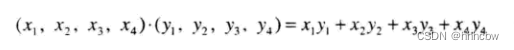
下面的代码实现了点积函数的第一个步骤
#include "../common/book.h"
#define imin(a,b) (a<b?a:b)
const int N = 33 * 1024;
const int threadsPerBlock = 256;
__global__ void dot(float* a, float* b, float* c) {
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// 设置cache中相应位置上的值
cache[cacheIndex] = temp;
}
在代码中声明了一个共享内存缓冲区,名字为 cache。这个缓冲区将保存每个线程计算的加和值。要声明一个驻留在共享内存中的变量是很容易的,这相当于在标准C中声明一个 static 或 volatile 类型的变量。
__shared__ float cache[threadsPerBlock];
我们将数组的大小声明为 threadsPerBlock,这样线程块中的每个线程都能将它计算的临时结果保存到某个位置上。之前在分配全局内存时,我们为每个执行核函数的线程都分配了足够的内存,即线程块的数量乘以 threadPerBlock。但对于共享变量来说,由于编译器将为每个线程块生产共享变量的一个副本,因此只需根据线程块中线程的数量来分配内存。
在分配了共享内存后,像前面一样计算数据索引:
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
最后,设置了共享内存缓冲区相应位置上的值,以便随后能将整个数组相加起来,并且无需担心某个特定的位置上是否包含有效的数据:
// 设置cache中相应位置上的值
cache[cacheIndex] = temp;
如果输入矢量的长度不是线程块中线程数量的整数倍,那么 cache 中的元素将不会被全部用到。在这种情况中,最后一个线程块中将有一些线程不做任何事情。
每个线程都计算数组 a 和 b 中相应元素乘积的总和,然后当到达数组末尾时,再将临时加和值保存到共享缓冲区中。
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// 设置cache中相应位置上的值
cache[cacheIndex] = temp;
当算法执行到这一步时,我们需要将 cache 中所有的值相加起来。在执行这个运算时,需要通过一个线程来读取保存在 cache 中的值。然而,在前面已经提到过,这可能是一种危险的操作。我们需要某种方法来确保所有对共享数组 cache[] 的写入操作在读取 cache 之前完成。方法如下:
// 对线程块中的线程进行同步
__syncthreads();
这个函数调用将确保线程块中的每个线程都将执行完 __syncthreads() 前面的语句后,才会执行下一条语句。这正是我们需要的功能。现在,我们知道,当一个线程执行 __syncthreads() 后面的第一条语句时,线程块中的其他线程肯定都已经执行完了 __syncthreads()。
这时,我们可以确信 cache 已经填好了,因此可以将其中的值相加起来。这个相加过程可以抽象为更一般的形式:对一个输入数组执行某种计算,然后产生一个更小的结果数组,这种过程也称为归约(Reduction)。
实现归约运算的最简单方法是,由一个线程在共享内存上进行迭代并计算出总和值。计算的时间与数组的长度成正比。然而,在这里的示例中有数百个线程可用,因此,我们可以以并行的方式来执行归约运算,这样所花的时间将与数组长度的对数成正比。
代码的基本思想是,每个线程将 cache[] 中的两个值相加起来,然后将结果保存回 cache[]。由于每个线程都将两个值合并为一个值,那么在完成这个步骤后,得到的结果数量就是计算开始时数值数量的一半。在下一个步骤中,我们对这一半数值执行相同的操作。在将这种操作执行 log2(threadsPerBlock) 个步骤后,就能得到 cache[] 中所有值的总和。对这里的示例来说,我们在每个线程块中使用了256个线程,因此需要 8 次迭代将 cache[] 中的 256 个值归约为 1 个值。
归约运算的代码如下
// 对于归约运算来说,以下代码要求 threadPerBlock 必须是2的指数
int i = blockDim.x / 2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
在第一个步骤中,我们取 threadsPerBlock 的一半作为 i 值,只有索引小于这个值的线程才会执行。只有当线程的索引小于 i 时,才可以把 cache[] 的两个数据项相加起来,因此我们将加法运算放在 if(cacheIndex < i) 的代码块中。执行加法运算的线程将 cache[] 中线程索引位置上的值和线程索引加上 i 得到的位置上的值相加起来,并将结果保存回 cache[] 中线程索引位置上。
假设在 cache[] 中有 8 个元素,因此 i 的值为 4。归约运算的其中一个步骤如下图所示:

在完成了一个步骤后,将出现在计算完两两元素乘积后相同的问题。在读取 cache[] 中的值之前,首先需要确保每个写入 cache[] 的线程都已经执行完毕。因此,在赋值运算后面,增加了 __syncthreads 调用以确保满足这个条件。
在结束了 while() 循环后,每个线程块都得到了一个值。这个值位于 cache[] 的第一个元素中,并且就等于该线程块中两两元素乘积的加和。然后,我们将这个值保存到全局内存并结束核函数:
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
为什么只有 cacheIndex==0 的线程执行这个保存操作?这是因为只有一个值写入到全局内存,因此只需要一个线程来执行这个操作。当然,每个线程都可以执行这个写入操作,但这么做将使得在写入单个值时带来不必要的内存通信量。为了简单,这里选择了索引为 0 的线程,当然也可以选择任何一个线程将 cache[0] 写入到全局内存。最后,由于每个线程块都只写入一个值到全局数据 c[] 中,因此可以通过 blockIdx 来索引这个值。
我们得到了一个数组 c[],其中该数组的每个元素中都包含了某个线程块计算得到的加和值。点积运算的最后一个步骤就是计算 c[] 中所有元素的总和。此时,尽管点积运算还没有完全计算完毕,但我们却退出核函数并将执行控制返回到主机。那么,为什么要在尚未计算完成之前就返回到主机?
我们在前面将点积运算称为一种归约运算。大体来说,这是因为最终生成的输出数据数量要小于输入数据的数量。在点积运算中,无论输入的数量有多少,通常只会生成一个输出结果。**事实证明,将GPU这种大规模的并行机器在执行最后的归约步骤时,通常会浪费计算资源,因为此时的数据集往往非常小。**例如,当使用 480 个数学处理单元将 32 个数值相加时,将难以充分使用每一个数学处理单元。
因此,我们将执行控制返回到主机,并且由CPU来完成最后一个加法步骤,即将计算数组 c[] 中所有元素的总和。如果在一个更大的应用程序中,此时的GPU就可以开始执行其他的点积运算或者其他的大规模计算。
下面为 main() 函数及其对核函数的调用
const int blocksPerGrid = imin(32, (N + threadsPerBlock - 1) / threadsPerBlock);
int main()
{
float* a, * b, c, * partial_c;
float* dev_a, * dev_b, * dev_partial_c;
// 在CPU上分配内存
a = new float[N];
b = new float[N];
partial_c = new float[blocksPerGrid];
// 在GPU上分配内存
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(float)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(float)));
HANDLE_ERROR(cudaMalloc((void**)&dev_partial_c, blocksPerGrid * sizeof(float)));
// 填充主机内存
for (int i = 0; i < N; i++) {
a[i] = i;
b[i] = i * 2;
}
// 将数组 a 和 b 复制到GPU上
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(float), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(float), cudaMemcpyHostToDevice));
dot << < blocksPerGrid, threadsPerBlock >> > (dev_a, dev_b, dev_partial_c);
return 0;
}
简单总结上述代码:
- 为输入数组和输出数组分配主机内存和设备内存。
- 填充输入数组
a[]和b[],然后通过cudaMemcpy()将它们复制到设备上。 - 在调用计算点积的核函数时指定线程格中线程块的数量以及每个线程块中的线程数量。
这里选择了 32 个线程块,选择其他的值可能会产生更好或者更差的性能,这要取决于 CPU 和 GPU 的相对速度。
然而,对于一段非常短的代码,选择 32 个线程块,并且每个线程块包含 256 个线程,那么是否会造成线程过多的情况?如果有 N 个数据元素,那么通常只需要 N 个线程来计算点积。但在这里的情况中,线程数量应该为 threadsPerBlcok 的最小整数倍,并且要大于或者等于 N。这里采用的计算公式为 (N + threadsPerBlock - 1) / threadsPerBlock。最后选择二者中较小的。
const int blocksPerGrid = imin(32, (N + threadsPerBlock - 1) / threadsPerBlock);
在核函数执行完毕后,我们将保存临时和值的数组复制回来,并在CPU上完成最终的求和运算。
// 将数组 c 从GPU复制到CPU
HANDLE_ERROR(cudaMemcpy(partial_c, dev_partial_c, blocksPerGrid * sizeof(float), cudaMemcpyDeviceToHost));
// 在CPU上完成最终的求和运算
c = 0;
for (int i = 0; i < blocksPerGrid; i++) {
c += partial_c[i];
}
最后,检查是否得到了正确的结果,并释放了在CPU和GPU上分配的内存。检查结果的过程很容易,因为我们有规律地将数据填充进输入数组,其中 a[] 中的值是从 0 到 N-1 的整数,而 b[] 则是 2*a[]。
// 填充主机内存
for (int i=0; i<N; i++) {
a[i] = i;
b[i] = i * 2;
}
点积计算结果应该是从 0 到 N-1 中每个数值的平方再乘以 2 下面给出了闭合形式解
main 函数剩余代码如下
printf("Does GPU value %.6g = %.6g?\n", c, 2 * sum_squares((float)(N - 1)));
// 释放GPU上的内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_partial_c);
// 释放CPU上的内存
delete[] a;
delete[] b;
delete[] partial_c;
完整代码如下
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "device_functions.h"
#include "../common/book.h"
#include <stdio.h>
#define imin(a,b) (a<b?a:b)
#define sum_squares(x) (x*(x+1)*(2*x+1)/6)
const int N = 33 * 1024;
const int threadsPerBlock = 256;
__global__ void dot(float* a, float* b, float* c) {
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// 设置cache中相应位置上的值
cache[cacheIndex] = temp;
__syncthreads();
// 对于归约运算来说,以下代码要求 threadPerBlock 必须是2的指数
int i = blockDim.x / 2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
}
const int blocksPerGrid = imin(32, (N + threadsPerBlock - 1) / threadsPerBlock);
int main()
{
float* a, * b, c, * partial_c;
float* dev_a, * dev_b, * dev_partial_c;
// 在CPU上分配内存
a = new float[N];
b = new float[N];
partial_c = new float[blocksPerGrid];
// 在GPU上分配内存
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(float)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(float)));
HANDLE_ERROR(cudaMalloc((void**)&dev_partial_c, blocksPerGrid * sizeof(float)));
// 填充主机内存
for (int i = 0; i < N; i++) {
a[i] = i;
b[i] = i * 2;
}
// 将数组 a 和 b 复制到GPU上
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(float), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(float), cudaMemcpyHostToDevice));
dot << < blocksPerGrid, threadsPerBlock >> > (dev_a, dev_b, dev_partial_c);
// 将数组 c 从GPU复制到CPU
HANDLE_ERROR(cudaMemcpy(partial_c, dev_partial_c, blocksPerGrid * sizeof(float), cudaMemcpyDeviceToHost));
// 在CPU上完成最终的求和运算
c = 0;
for (int i = 0; i < blocksPerGrid; i++) {
c += partial_c[i];
}
printf("Does GPU value %.6g = %.6g?\n", c, 2 * sum_squares((float)(N - 1)));
// 释放GPU上的内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_partial_c);
// 释放CPU上的内存
delete[] a;
delete[] b;
delete[] partial_c;
return 0;
}
运行结果如下:

(不正确的)点积运算优化
在前面曾简要地介绍了点积运算示例中的第二个 __syncthreads()。现在,我们来进一步分析这个函数调用,并尝试对其进行改进。之所以需要第二个 __syncthreads(),是因为在循环迭代中更新了共享内存变量 cache[],并且在循环的下一次迭代开始之前,需要确保当前迭代中所有线程的更新操作都已经完成。
int i = blockDim.x / 2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
为什么需要在循环的下一次迭代开始之前,要确保当前迭代中所有线程的更新操作都已经完成。我们看下图,索引 5 会更新索引 1,索引 3 在下一次迭代中也会更新索引 1,那么就会产生竞态条件(Race Condition)。

在上面的代码中,我们发现只有当 cacheIndex 小于 i 时才需要更新共享内存缓冲区 cache[]。由于 cacheIndex 实际上就等于 threadIdx.x,因而这意味着只有一部分的线程会更新共享内存。由于调用 __syncthreads 的目的只是为了确保这些更新在下一次迭代之前已经完成,因此如果将代码修改为只等待那些需要写入共享内存的线程,是不是就能获得性能提升?我们通过将同步调用移动到 if() 线程块中来实现这个想法:
int i = blockDim.x / 2;
while (i != 0) {
if (cacheIndex < i) {
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
}
i /= 2;
}
虽然这种优化代码的初衷不错,但却不起作用。事实上,这种情况比优化之前的情况还要糟糕。在对核函数进行修改后,GPU将停止响应,不得不强行终止程序。
这是因为,线程块中的每个线程依次通过代码,每次一行。每个线程都执行相同的指令,但对不同的数据进行运算。然而,当每个线程执行的指令位于一个条件语句中,例如 if(),那么将出现什么情况?显然,并不是每个线程都会执行这个指令,CUDA架构将确保,除非线程块中的每个线程都执行了 __syncthreads(),否则没有任何线程能执行 __syncthreads() 之后的指令。遗憾的是,如果 __syncthreads() 位于发散分支中,那么一些线程将永远都无法执行 __syncthreads()。因此,由于要确保在每个线程执行完 __syncthreads() 后才能执行后面的语句,硬件将使这些线程保持等待。一直等,一直等,永久地等待下去。
基于共享内存的位图
下面看一个只有使用 __syncthreads() 才能保证正确性的图形示例。我们将给出预计的输出结果,以及在没有 __syncthreads() 时的输出结果。
main 函数如下,一次在每个线程块中启动多个线程:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "cuda.h"
#include <stdio.h>
#include <math.h>
#include "device_functions.h"
#include "../common/book.h"
#include "../common/cpu_bitmap.h"
#define DIM 1024
#define PI 3.1415926535897932f
int main()
{
CPUBitmap bitmap(DIM, DIM);
unsigned char* dev_bitmap;
HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size()));
dim3 grids(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel << <grids, threads >> > (dev_bitmap);
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost));
bitmap.display_and_exit();
cudaFree(dev_bitmap);
return 0;
}
每个线程都将为一个输出位置计算像素值。每个线程要做的第一件事情就是计算输出图像中相应的位置 x 和 y。这种计算类似于矢量加法示例中对 tid 的计算,只是这次计算的是一个二维空间。
__global__ void kernel(unsigned char* ptr) {
// 将threadIdx/BlockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
由于将使用一个共享内存缓冲区来保存计算结果,我们声明了一个缓冲区,在 16 x 16 的线程块中的每个线程在该缓冲区中都有一个对应的位置。
__shared__ float shared[16][16];
然后,每个线程都会计算出一个值,并将其保存到缓冲区中。
// 现在计算这个位置上的值
const float period = 128.0f;
shared[threadIdx.x][threadIdx.y] = 255 * (sinf(x * 2.0f * PI / period) + 1.0f) * (sinf(y * 2.0f * PI / period) + 1.0f) / 4.0f;
最后,我们将把这些值保存回像素,保留 x 和 y 的次序:
ptr[offset * 4 + 0] = 0;
ptr[offset * 4 + 1] = shared[15 - threadIdx.x][15 - threadIdx.y];
ptr[offset * 4 + 2] = 0;
ptr[offset * 4 + 3] = 255;
}
运行之后,可以看到图像出现了一点问题

这是因为在代码中忽略了一个重要的同步点。当线程将 shared[][] 中的计算结果保存到像素中时,负责写入到 shared[][] 的线程可能还没有完成写入操作。确保这种问题不会出现的唯一方法就是使用 __syncthreads()。没有使用 __syncthreads() 的结果就是得到一张被破坏的图片,充满了绿色的球形。
要解决这个问题,我们需要在写入共享内存与读取共享内存之间添加一个同步点。
shared[threadIdx.x][threadIdx.y] = 255 * (sinf(x * 2.0f * PI / period) + 1.0f) * (sinf(y * 2.0f * PI / period) + 1.0f) / 4.0f;
__syncthreads();
ptr[offset * 4 + 0] = 0;
ptr[offset * 4 + 1] = shared[15 - threadIdx.x][15 - threadIdx.y];
ptr[offset * 4 + 2] = 0;
ptr[offset * 4 + 3] = 255;
}
在添加 __syncthreads() 调用后,我们就可以获得一个预期的结果。
完整代码如下
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "cuda.h"
#include <stdio.h>
#include <math.h>
#include "device_functions.h"
#include "../common/book.h"
#include "../common/cpu_bitmap.h"
#define DIM 1024
#define PI 3.1415926535897932f
__global__ void kernel(unsigned char* ptr) {
// 将threadIdx/BlockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
__shared__ float shared[16][16];
// 现在计算这个位置上的值
const float period = 128.0f;
shared[threadIdx.x][threadIdx.y] = 255 * (sinf(x * 2.0f * PI / period) + 1.0f) * (sinf(y * 2.0f * PI / period) + 1.0f) / 4.0f;
__syncthreads();
ptr[offset * 4 + 0] = 0;
ptr[offset * 4 + 1] = shared[15 - threadIdx.x][15 - threadIdx.y];
ptr[offset * 4 + 2] = 0;
ptr[offset * 4 + 3] = 255;
}
int main()
{
CPUBitmap bitmap(DIM, DIM);
unsigned char* dev_bitmap;
HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size()));
dim3 grids(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel << <grids, threads >> > (dev_bitmap);
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost));
bitmap.display_and_exit();
cudaFree(dev_bitmap);
return 0;
}
运行结果如下

遇到的问题及解决方案
主要就是 __syncthreads() 不存在的问题,这个需要导入 device_functions.h 的头文件
#include "device_functions.h"














 1135
1135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









