







Github Link: GitHub - bowang1981/fastcode2_clipper2
Abstract—Polygon boolean is widely used in EDA, and the performance over massive polygon boolean has become a major concern due to the chip design becoming more complicated. This document studies the possibility and challenges of parallelizing this using OpenMP and CUDA for some typical boolean operations in Clipper2
Keywords—OpenMP, CUDA, Clipper2, parallelization
- Introduction
In the EDA industry, the chip design is conceptually organized by layers, and each layer is composed of polygons. The final design is the boolean operations from different layers; the boolean operation includes different polygon operations, such as CLIP, AND, UNION, OFFSET, etc. However, as the chip size becomes smaller, the features on the chips become more complicated, and the design file becomes much larger. Each layer could have billions of polygons, and each polygon could have thousands of vertices. The boolean operation among the layers becomes very challenging. Nvidia has just released a solution called cuLitho that will use GPU to accelerate this(NVIDIA CuLitho, n.d.). However, most EDA companies still use traditional boolean engines like Clipper and Boost geometry. We are applying openMP and CUDA to parallelize the Clipper engine.
The library that we are trying to parallelize is the Clipper2 library; it’s an open-source, free library that performs lines/polygons clipping, union, and offsetting over polygons. [2]. The library is available at GitHub - AngusJohnson/Clipper2: Polygon Clipping and Offsetting - C++, C# and Delphi.
Due to the time limit, our focus is clipping on a rectangle area, polygon offsetting on non-overlap polygons, and limited study of union polygons. We also studied how to do area calculations on massive polygons.
- Polygon boolean: background
- Polygon Clipping
The RectClipping operation iterates through a given path, identifying intersections with a specified rectangle, and selectively retains segments of the path that lie inside or cross the rectangle's boundaries. It does so by sequentially comparing each point against the rectangle, calculating intersection points when necessary, and updating the path based on these intersections.

Fig 1
- Polygon Union
Polygon Union will merge overlapping polygons into one polygon that will cover the whole area of these polygons, as illustrated in Fig 2. Clipper implements this using Vatti’s clipping algorithm [1]
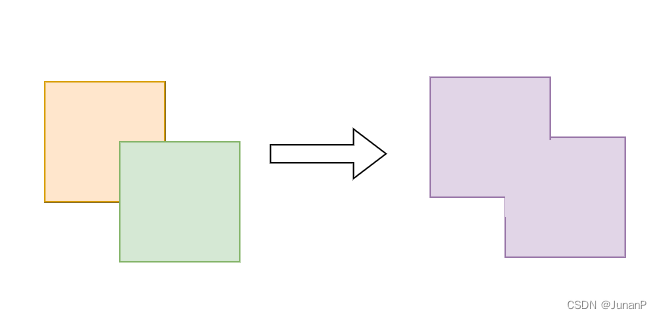
Fig 2
- Polygon Offsetting
Offsetting refers to the process of creating parallel curves that are offset a specified distance from their starting positions.
Here is an example of offsetting. Note how the curves in the outer and inner of the rabbit are offsets of each other.

Fig 3
- Parallelization methods
The primary performance challenges on those boolean options are mainly from two perspectives. There are massive polygons to be handled, or there are massive points in one polygon. Those two challenges can exist in one data set. In our study, we focus on the massive polygon scenario and only check the massive vertices case for area calculation.
Before we do the optimization, we need to have a way to check whether the output from parallelized algorithms is correct. To do this, we define a function to collect the boundary(left, right, top, down) of all the polygons and the mean of X and Y coordinates(MeanXY). MeanXY is defined as follows:
MeanXY = Avg(Avg of all X, Y in the polygon)
However, it needs to be aware that GPU and CPU could generate numerical differences on certain functions(sin, cos, etc.), and the results could be sensitive to this and cannot be precisely the same. Hence, we need to set a reasonable threshold on this (< 3% difference in the boundary and MeanXY for most cases); in the meantime, we also provide a SaveAndDisplay function to verify results visually.
- Data Structure and Test Case Generation
Clipper2 lib uses a Path concept to manage a polygon, which is essentially an STL vector of Point. A set of polygons is managed by a container called Paths; this is just a vector of Path. To parallelize the openMP, we’ll split the Paths structure into a vector of smaller Paths and distribute them into different threads. On the other hand, the same Path structure cannot be reused in the CUDA implementation; for that, new structures(cuPaths64, cuPath64, cuPoint) are defined on the device. To make efficient memory management, all the points are also saved in an array in the cuPaths64, and different sub-array is mapped to the points in one cuPath64. Unified Memory Management(cudaMallocManaged) is used to simplify the development, which could have a negative impact on the performance compared with explicit functions.
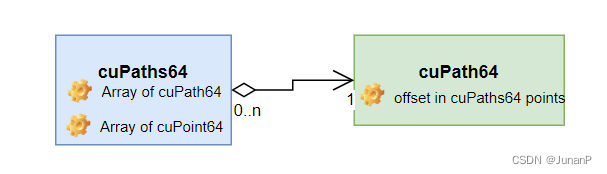
Fig 4
The test cases are automatically generated randomly, and a helper function is provided in the TestGenerator class to create different test sizes; the 10K and 1M cases are mainly used for performance testing. The test cases are non-overlapped polygons with int64 data type; an example is shown below.
Fig 5
- Area Calculation
![]()
The formula above is the Shoelace Formula, a simple yet effective algorithm used by Clipper2 for computing polygons on a 2D plane. It operates by performing a linear scan through all the points comprising the polygon to its area. There are two types of area calculation that we have parallelized.
1. Massive rectangles/polygons need to be calculated. This is a case where the sum of the area for a massive array of non-overlapping polygons needs to be calculated. Note that the calculations for each polygon's area are independent of each other. To exploit this independence, we employ a parallelization strategy where individual threads are assigned to iterate through the points of each polygon and compute its area.
2. The polygon has massive vertices. This is the case where we calculate the area of one polygon that possesses an extensive number of vertices. Since the shoelace formula only requires one linear scan through all the points, we could exploit this property by splitting the points into multiple segments equal to the number of threads we use. We then assign each thread to a segment and perform the necessary calculations. By combining the results of each thread, we could obtain the area of a polygon in a parallelized manner.
- Polygon Clipping
OpenMP: For the following 2 cases:
1. Massive rectangles/polygons need to be calculated. In the initial implementation, the function processes each path by applying the RectClipping operation, subsequently adding these processed segments to the final results. This approach utilizes multiple protected variables within the RectClip64 class to execute the algorithm. Given that only one instance of this object is created, the challenge for parallelization arises from these shared variables. To enable parallelization with OpenMP, a viable strategy involves isolating these variables, creating separate duplicates for each, and distributing them across the individual threads. We'll employ OpenMP's basic parallel for loop, and due to the complex nature of the shared 'final results' vector, including operations like emplace_back and push_back, we'll safeguard the results merging process using a critical section.
2. The polygon has massive vertices. Given the algorithm's reliance on sequential processing, where the evaluation of each point's location in relation to the rectangle is dependent on the preceding point's location (inside, outside, or on the boundary), introducing parallelism through OpenMP is impractical. This order is crucial for determining whether the path enters, exits, or crosses the rectangle, affecting how intersections are identified and handled. Attempting to parallelize this process with OpenMP could disrupt the necessary order of operations, so we decided not to do this in this part.
CUDA: In our CUDA implementation, we also choose to address only the first scenario for the same reason. Upon reviewing the code logic, we observed that the majority of polygons are entirely contained within the rectangle. Thus, the actual number of polygons requiring intersection calculations with the rectangle is relatively limited. To efficiently handle this, we introduced a filtering operation via CUDA, specifically targeting polygons that reside within the rectangle. This filter operation effectively reduces the number of polygons that need further rectclip computations. Given the significantly reduced count of polygons necessitating complex calculations, we can manage these few cases using original sequential clipping processing.
- Polygon Union
Vatti’s algorithm has a heavy dependency loop that cannot be easily parallelized without a major effort of refactoring the Clipper2 codes. However, union on massive polygons could be slow due to the heavy computation that we can parallelize. The “union operation” follows associative law, which is:
P1 + P2 + P3 + P4 = (P1 + P2) + (P3 + P4).
This means the polygons can be split into different groups and do the union separately, then do the union based on the result of each group. As the union operation only happens on overlapped polygons, our distributed strategy is dividing the whole area into a 1 x thread_num grid and assigning the polygons to the different grids. The detailed algorithm is as follows:
- Calculate the area boundary.
- Divide the polygons into different grids by checking the first point of the polygon. If the center is on the boundary of the two grids, pick the one on the left or top.
- Do the Union for each grid and save the result.
- Do the union on the grid results.
As our test generator only generates non-overlapping polygons(union will do nothing in this case), our Union test does the union on two randomly generated polygon sets.
Also, due to the limited time and the large scope of the union on CUDA implementation, the CUDA support for the union is not within the current scope.
- Polygon Offsetting
It needs to be aware that polygon offsetting has two steps in the Clipper2 library.
- Do the offsetting for each edge/point. This could cause polygon overlap
- Do the union on the result of step 1 to create a clean result.
However, due to the lack of CUDA support for the union and the lack of refactoring of the union for openMP, this study focuses on the first step, which is offsetting for each polygon without cleaning the results with the union. This is also what offsetting means in this session and later.
OpenMP: As offsetting each polygon doesn’t depend on the others, this step can be distributed to different threads without concerns. Besides, as the offset is performed per segment, our strategy is to make sure each thread takes a similar amount of vertices. The algorithm is described below:
- Split the polygons into small polygon sets evenly based on the given thread number and make sure each set has a similar number of vertices..
- Do offsetting on smaller polygon sets in parallel.
- Merge the result back into one polygon set.
CUDA: The CUDA algorithm is similar to openMP, but it’s much more complex. There are several major challenges for this:
- It has to be converted to the data structure that can be launched on devices.
- When the “ROUND” option is given, the Clipper will need to do interpolation on the corners to make it smoother; this will make the number of vertices unpredictable and make the device's memory reservation very difficult, to simplify this in the current scope, a limit is set to 3 for the interpolated points.
- Numeric differences(GPU vs CPU) make it difficult to justify the correctness of the algorithm.
The algorithm for the CUDA version is described below:
- Convert the Paths64(vector) into the cuPaths64
- Do offsetting on the kernel function, and each thread will process a batch of continuous polygons in the list. Each batch has a similar amount of polygons.
- Convert the cuPaths64 to STL Paths64.
- Result AnAlysis
- General Cost of Parallelization
There are several overhead that will be introduced during the implementation to enable the parallelization besides the cost of launching the openMP threads or the CUDA kernel. In the test, we use the polygons with less than 300 vertices.
1. Split the Paths64 to multiple smaller Paths64(Patch), the test results can be found in the following table 1:
| Original Size | Patch Number | Runtime(ms) |
| 10 K | 8 | 15 |
| 1 M | 8 | 1460 |
| 1M | 16 | 1490 |
Table 1
The test results show that this is a significant effort, and considering that in practice the users can generate all the Patch directly in the first place if the full support of the patch based solution is implemented in Clipper, this can be further saved.
2. Convert the Paths64 from/to CUDA data structure cuPaths64.The runtime information can be found in the table 2. The time of the conversion is large; this indicates that to have a better performance on CUDA, it’s better to further change the Path data structure in Clipper2 to make it more consistent with the CUDA version, at this point, as not all clipper2 functions are moved to the CUDA and some unsupported functions are still called before/after the kernel, the data structure needs to be kept for now.
| # of Polygon | to cuPaths64 (ms) | from cuPaths64(ms) |
| 10K | 13.3 | 18.7 |
| 100K | 131 | 192 |
| 1M | 1260 | 1880 |
Table 2
3. Move data between host and device. The run-time information can be found in Table 3 for both host to the device (H2D) and device-to-host (D2H)
| # of Polygon | H2D(ms) | D2H(ms) |
| 10K | 2.8 | 12.6 |
| 100K | 20 | 134 |
| 1M | 197 | 1260 |
Table 3
The test is based on the explicit data copy, not the unified memory on CUDA. For unified memory implementation, a simple kernel has been tried to simply access some points to trigger page missing/fault and data load, but no major performance difference was found for the runtime.
- Area Calculation
OpenMP:
1. Massive rectangles/polygons need to be calculated.
For this measurement, we have created an array of polygons, each containing 200 vertices. We then measure how the size of the array of polygons would affect runtime with the number of threads fixed at 4.
From the graph, we see that OMP's implementation has a shorter runtime and improves the performance for all cases.
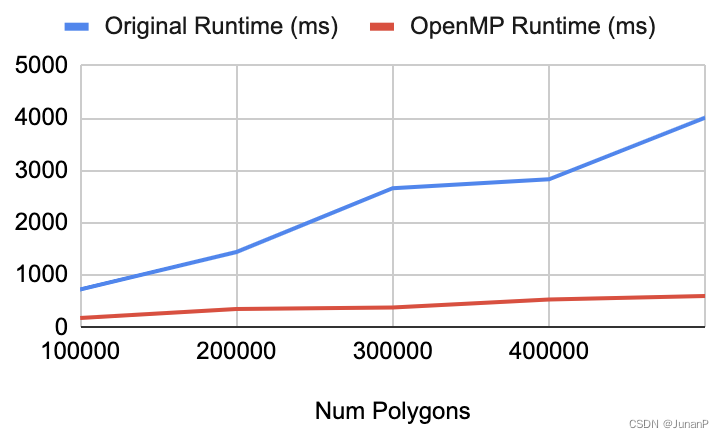
Fig 6
We then measure the performance of OpenMP's implementation when different numbers of threads are used to process an array of 50 million polygons.
As seen from the graph below, the increase in performance is drastic for the first few cases, but such difference decreases to under 100 ms after 32 threads as we reach the HW thread limit. The critical area, the server workload, and the overhead of the multiple threads contribute to why we cannot get the theoretical limit.

Fig 7
2. The polygon has massive vertices.
For this measurement, we measure the runtime of calculating the area for a polygon with a large number of vertices. The graph below shows that OpenMP's runtime is consistent with around half of the original runtime using four threads.
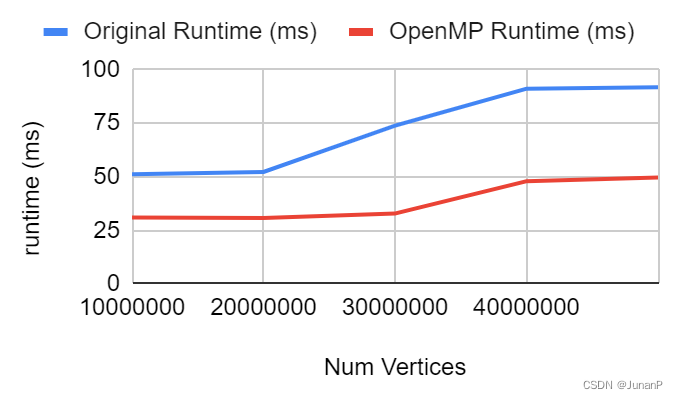
Fig 8
We then measure how using a different number of threads to calculate the area for a polygon of 50 million vertices would differ. As we can see in Fig 9, the speedup is going up until we hit the # of cores (16)

Fig 9
CUDA:
1. Massive rectangles/polygons need to be calculated.
We have launched one block and 32 threads per block for the measurement of how array size would cause the runtime to differ. The rest of the setup is identical to the measurement performed in OpenMP. As seen from the graph below, running CUDA is way slower than the original implementation. As we mentioned earlier, the time required to convert the data structure between CPU and GPU is the key factor that prevents us from having better performance.

Fig 10
2. The polygon has massive vertices.
We maintain the setup of launching one block and 32 threads per block to measure how the number of vertices of a polygon affects runtime. As shown in Fig 11, the CUDA runtime time is higher than the original. This shows that using CUDA for polygon area calculation does not improve performance, and kernel runtime is just a small portion of the total runtime. The result is expected with what we mentioned earlier. The data conversion and moving is taking more time and there is not enough computation that can beat that.

Fig 11
- Polygon Clipping
OpenMP:
We tested various thread counts, from 4 up to 32, and rectangles dataset sizes ranging from 100 to 10,000,000. The y-axis represents execution cycles, and the x-axis denotes the number of rectangles. The performance results were quite similar with hw1: the 32-thread setup delivered the poorest outcome. In contrast, setups with 4, 8, and 16 threads surpassed the baseline, with the 4-thread setup achieving the best overall performance. However, the performance was not significantly better than the baseline; we think the bottleneck would be the critical section in the implementation.
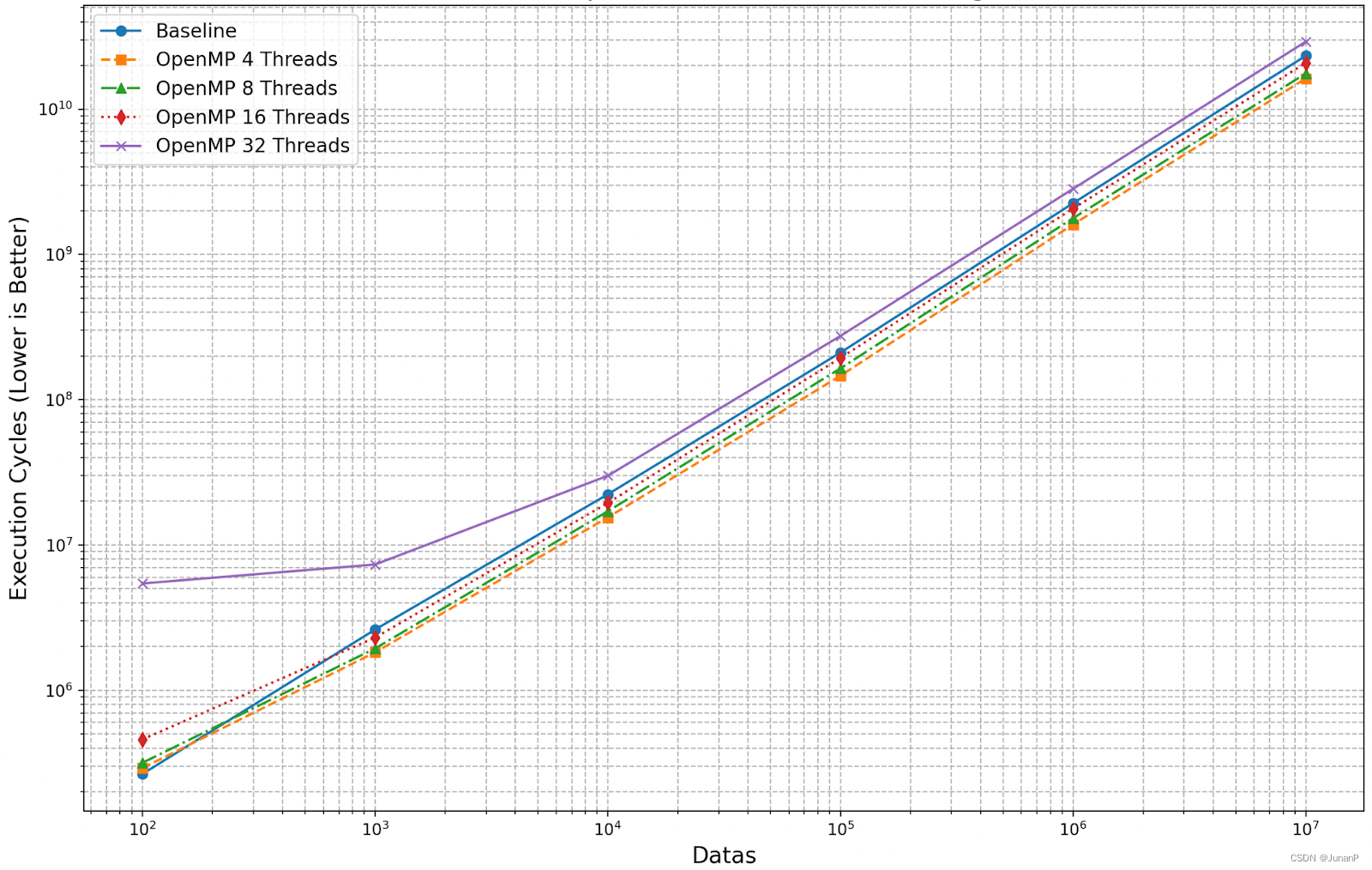
Fig 12
Considering the critical section, since the algorithm has already been implemented, the critical section in the code is only for the display process, which needs one final large result as input. If we don't need to display it, or we have functions to display the partial result at the same time, we can remove the critical section.
Here is the comparison when we don’t use the critical section to merge the result for display. (To make it fair, the baseline also didn’t operate the final result.)
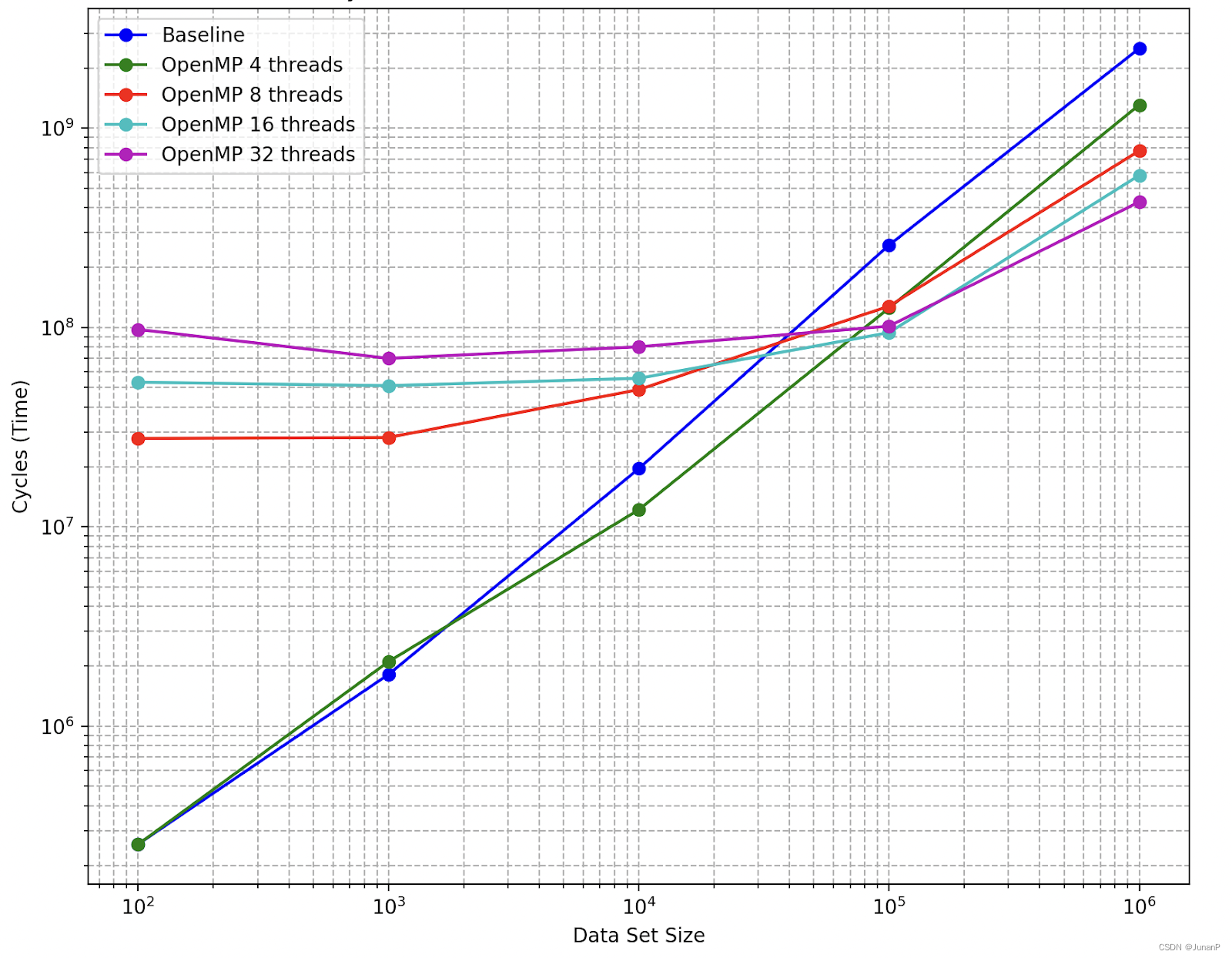
Fig 13
We can see when the dataset was small, the baseline was better than OpenMP. When the number of rectangles reached 10^4, the 4 threads approach became better, and when the number of rectangles reached 10^5, all multi-threads OpenMP implementations became better than the baseline. Notably, When the dataset became very large, the 32 threads approach was the best, while the 32 threads approach was the worst when the dataset was small at the beginning.
The reason may be when the dataset size is small, the overhead of managing multiple threads, including thread creation and synchronization, can outweigh the benefits gained from parallel processing. This leads to poorer performance with more threads in smaller datasets. As the dataset size increases, the computation workload becomes significant enough that the benefits of parallel processing start to surpass the overhead costs.
CUDA:
We conducted tests with datasets of varying sizes to compare the performance of original rectClipping against CUDA-accelerated methods. Similar to area calculation, the results demonstrate that while CUDA kernel run times are shorter than the original rectangle clipping times, the total CUDA rect clipping times are longer. This discrepancy suggests that the major time expenditure in the CUDA approach is due to data transfer and conversion overheads. Despite the computational efficiency of CUDA kernels, the time required to move and prepare data between the host and the GPU counteracts the speed gains from the computation, resulting in an overall increase in processing time.
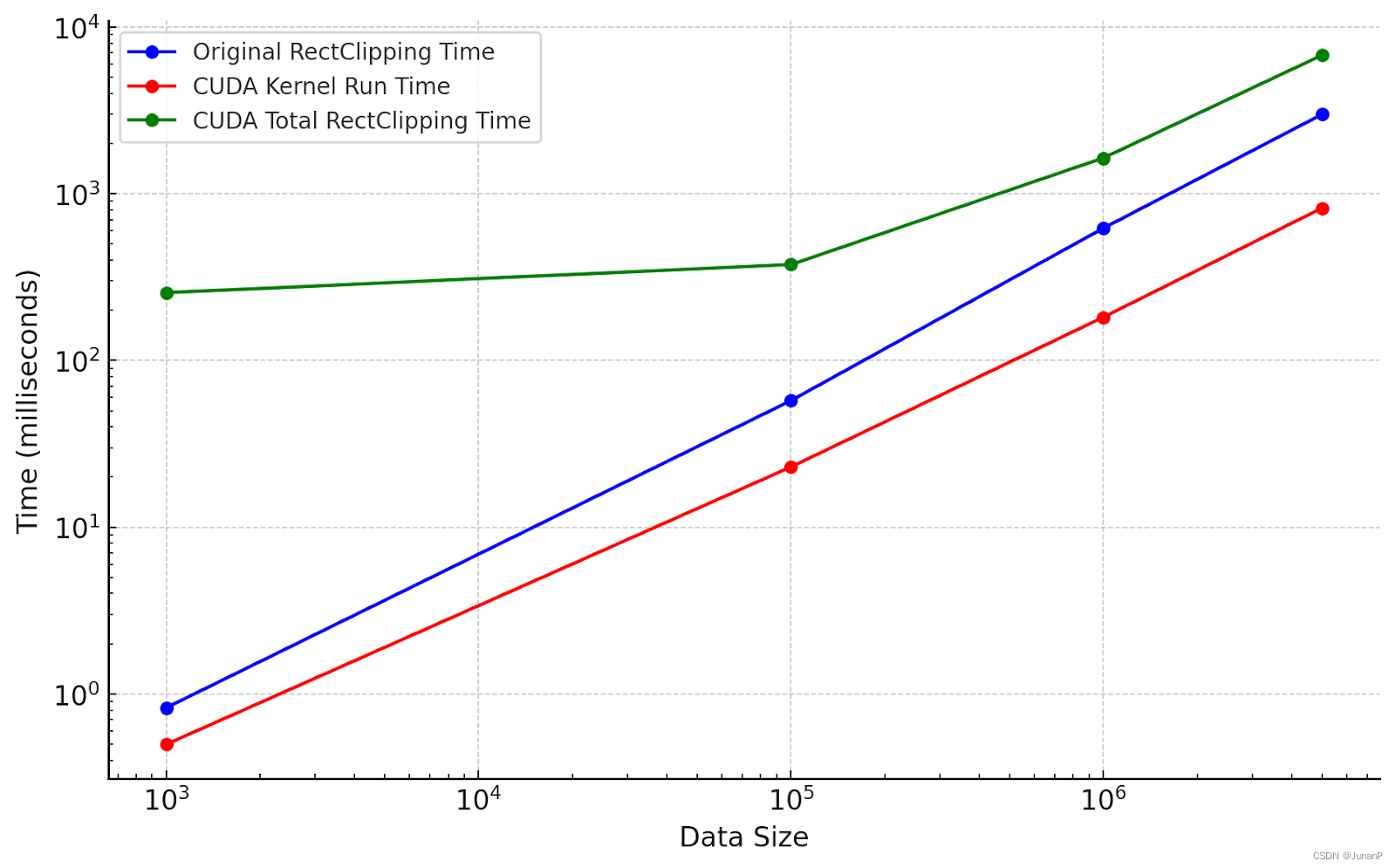
Fig 14
- Polygon Union
Union only has openMP implementation, the test results can be found in Fig 15.

Fig 15
The Fig shows that the speedup for union with this method is very limited and starts to show some benefit on large datasets. However, the performance gain is still very small. Further study shows that the performance has increased almost linearly in the 1st step of doing union on small patches, and the merge time in the second step is fixed, see Fig 16, parallelization in the second step has been tried but generates limited efforts as well. The main reason is that the Clipper will try to traverse all the points in the Union; hence merge steps will not have major efforts here. Further improvement needs to be updated in Clipper2’s algorithm to skip unnecessary union operations on un-overlapped polygons; however, as clipper2 tries to use the same engine for all different types of boolean operations, this is not a small change and is not in the current scope.
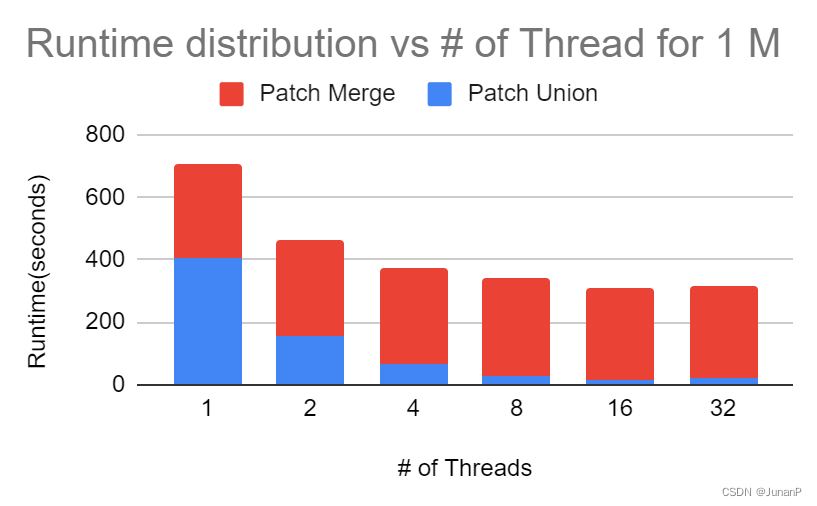
Fig 16
- Polygon Offsetting
OpenMP: The performance of the offsetting implementation is shown in Fig 17. Please note that this speedup factor doesn’t include the data conversion time. With that included, the performance gain will be much smaller, but that step can be skipped if the kernels can be updated to take a range index to do the polygon set split. The clipper engine now takes parameters Paths64 and does the offset on all of them, it can be changed to take a start_index and end_index so that the engine only does offsetting in this range in each thread. The data structure was not changed this way as we want to keep the data structure to have a clean baseline for CUDA, and the current method is good enough to prove the concept. It also needs to be mentioned that the speedup factor is not good for large datasets or more thread numbers. This is explained by the busy servers, and we failed to find a clean environment for benchmarking on this with multiple attempts. We confirm this by the following:
- Check the run time for each thread.
- Split the set into 16 small sets, and use 4 threads and 16 threads to run those 16 sets separately, we confirmed that the runtime of each set is much smaller in 4 thread setting. As our algorithm doesn’t use any critical area and no dependencies between threads, this concluded the algorithm’s performance can increase linearly in a clean environment.

Fig 17
CUDA: The performance of the CUDA implementation is shown in Fig 18. With a kernel size of 32 blocks x 64 threads, the overall speedup is not a good performance gain and is not worth the cost of the GPU. However, by looking at the kernel run time only, the speedup is more than 30 over 1M polygons.
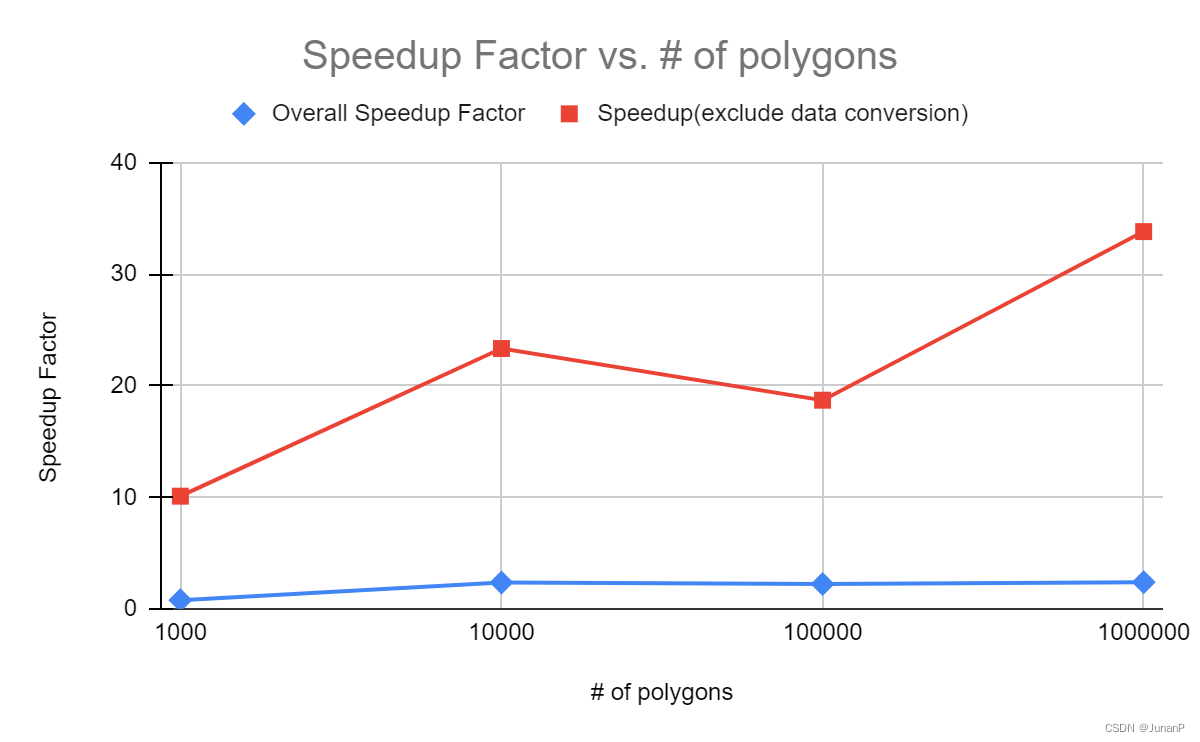
Fig 18
The further breakdown shows that this offset operation is a memory-intensive operation that requires reading and writing massive data and the computation time doesn’t outperform the extra time spent on this. In general, to support this in CUDA, it needs to do the following operations:
- Convert the Paths64 into the data structure that can be used on CUDA(cuPaths64), and move that to the device.
- Launch the kernel to do the computation.
- Move the result out from the device to the host and convert it to the Clipper2 data structure.
As described earlier, the time to do the data structure conversion is not ignorable, detail breakdown is listed in Fig 19. The kernel runtime is already very short compared to the data copy time. To improve this, the clipper2 data structure should be changed to avoid the data conversion step.

Fig 19
Future study
Future parallelization on the general boolean engine is needed, and from the result of OpenMP (offsetting and union), this is computation-heavy, and doing parallelizing on this would help both union and offsetting. Defining and exposing a new data structure of polygon in clipper2 is also desired to simplify the data conversion on CUDA, and dealing with the uncertain rounding interpolation points in CUDA is another area that we can improve. Further study of improving the performance by shared memory is also needed, for example, when do the offsetting, we can just keep the offsetting polygons in the shared memory.
References
- Bala R. Vatti, “A Generic Solution to Polygon Clipping,” Communication of the ACM, vol. 35, No7, pp. 57–63, July 1992.
- Clipper2 - Polygon Clipping and Offsetting Library. (n.d.). Clipper2 - Polygon Clipping and Offsetting Library
- Harris, M. (2022, August 21). Unified Memory for CUDA Beginners | NVIDIA Technical blog. NVIDIA Technical Blog. Unified Memory for CUDA Beginners | NVIDIA Technical Blog















 4053
4053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











