






(提要:这是卡内基梅隆大学即Detect-and-Track论文后又一篇姿态跟踪的论文,本文的算法运用到了卡内基梅隆大学在姿态估计中OpenPose的PAFs部分亲和场的问题。)
摘要:
1.提出了一个可跨视频序列编码的预测时空亲和场的结构(Spatio-Temporal Affinity Fields (STAF)
2.提出了一种跨肢体连接的结构图
3.从以前帧的STAFheatmap来估计当前帧的情况
 多人追踪是编码跨时间域内关键点和肢体的位置和方向作为TAFs
多人追踪是编码跨时间域内关键点和肢体的位置和方向作为TAFs
网络结构图:
本文采用的是递归神经网络,并将其分为四个阶段:
网络同OpenPose前面的基础部分依然采用的是VGG网络做特征提取
 其中:
其中:
a). K为关键点集合:K={K1,K2,K3…Kk}
b). L为部分亲和场集合PAFs: L={L1,L2,L3…Ll} 根据每帧的关键点生成的,亲和场的目的就是知道哪些关键点在哪片部位上
c). R为时空亲和场集合TAFs: R={R1,R2,R3…Rr} 捕获递归并跨帧连接关键点
”以上共同组成STAF结构“
其中每层的运算方法如下,本文在此提供了三种算法,但经过测试只有前两种的算法获得的MOTA更高些:
第一种方法
这种算法中使用了递归CNN,缺点是计算量大
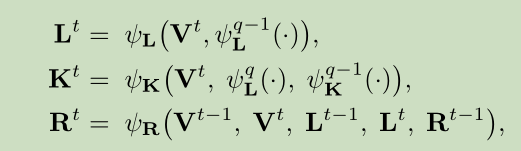
第二种方法
第二种方法并没有采用上面的CNN结构
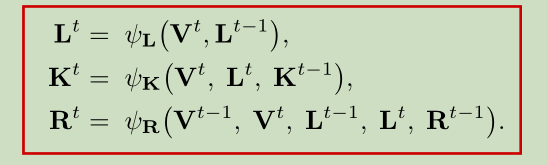
从图中我们可以看出这是一个Online的系统(只能利用前一帧的情况来估计下一帧的情况)。该结构利用了视频中的冗余信息,即前一帧中的PAFs和keypoints来预测当前帧中PAFs和keypoints位置。
不同帧的肢体连接又有以下三种情况:

**
推断与追踪:
**
推断下一帧的姿势
每帧内姿势由一个集合{Pt1,Pt2…Ptn}组成
其中每一个姿势Ptn又由众多个预测的关节点集合组成
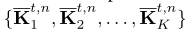
这里的每一个Ktn都是将heatmap经过缩放到原始图像的分辨率+NMS得到的
追踪
根据PAFs和TAFs的得分进行排序推测姿势和关联其id
(i) 如果PAF中的两个关键点都是未分配的,我们初始化一个新的姿势;
(ii)如果其中一个关键点被分配,则添加到现有姿势;
(iii)如果两个关键点都被分配到同一姿势,则更新PAF在姿势中的得分;
(iv)如果关键点属于不同姿势,且相反的关键点未分配,则合并两个姿势














 1480
1480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









