







KolektorSDD数据集中包
含了 50组电子换向器图片,其中每组包含 8张图
片以及对应的语义分割标签,图像宽均为 500像
素,高为 1 240~1 273像素
1、FCN
2、U-net
3、PSPnet
4、deeplab
5、seg-net
6、Refinenet
[CVPR 17]RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
提出了一套网络架构以实现高精度的语义分割任务。从网络结构来看,是U-Net的一个变种。文章的主要贡献和创新在于U-Net折返向上的通路之中。
相同感知野下残差卷积和空洞卷积优缺点对比:
- 残差卷积:防止梯度爆炸、计算量小,但会损失特征图分辨率
- 空洞卷积:计算量大,训练成本高,但能保存较大特征图分辨率,利于边界的定位细化。
设计目的:利用残差卷积,做到全局特征融合
- 编码部分:RESNET,生成四个不同大小特征层
- 解码部分:提出refinenet模块,进行残差堆叠和特征融合。
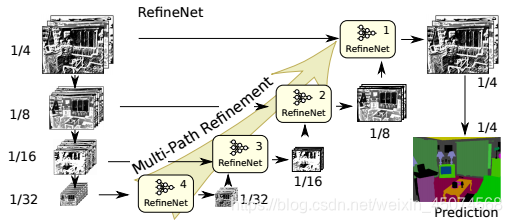
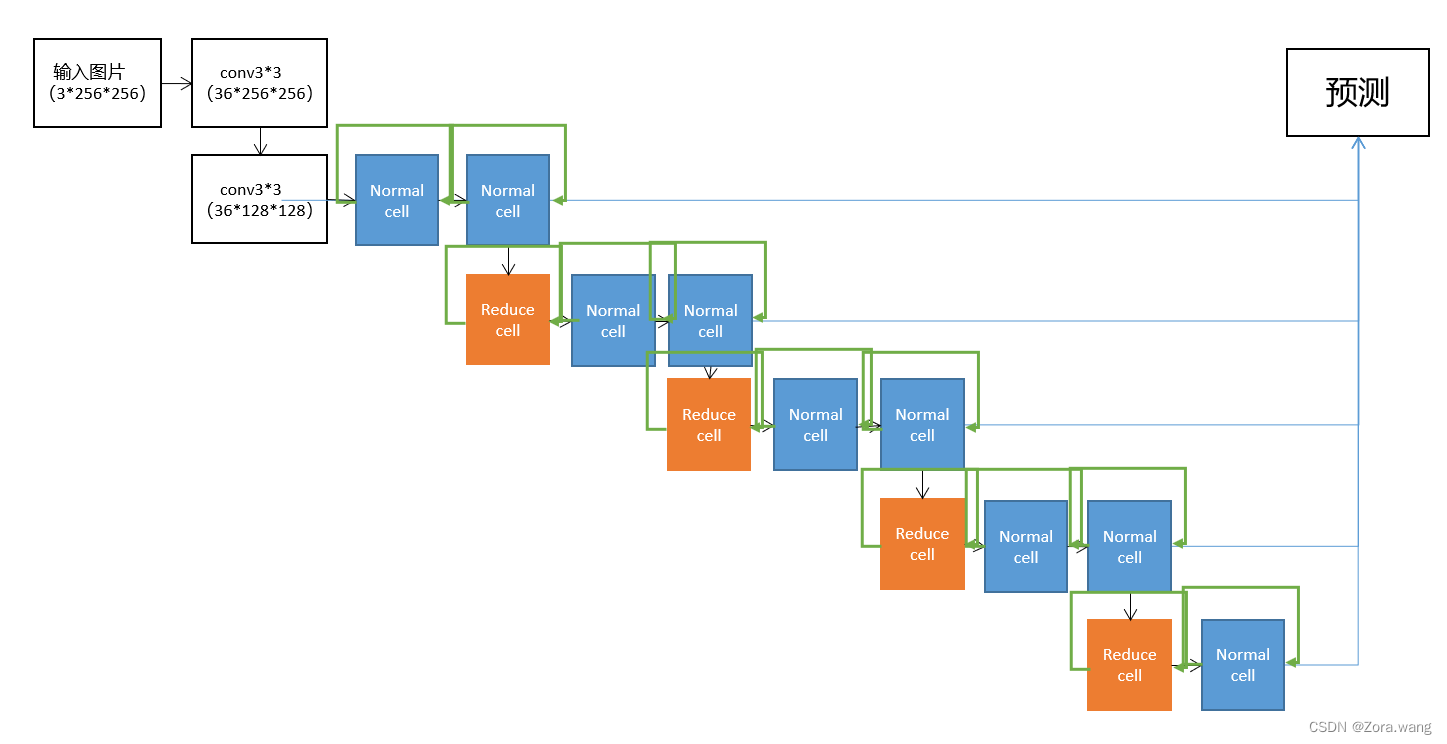
最左边一列就是FCN的encoder部分(用VGG作为主干特征提取网络),先把pretrained ResNet按feature map的分辨率分成四个ResNet blocks,然后向右把4个blocks分别作为4个path通过RefineNet block进行融合,最后得到一个refined feature map (接softmax再双线性插值输出)。注意除了RefineNet4之外,所有的RefineNet block都有两个输入,用于融合不同尺寸的特征层做refine。
RefineNet Block
主要组成部分是Residual convolution unit,Multi-resolution Fusion,chained Residual Pooling,output convolutions。作用是融合多个level的feature map输出单个level的feature map。

- RCU就是去除了BN的恒等残差块(identity residual unit)。两个RCU模块构成一条残差边,每个分辨率的特征层应用两个串联的RCU模块,提取分割结果的残差,最后相加来校正原始分割结果。除RefineNet 4中为512个卷积核外,其余所有输入路径上的卷积核个数均为256。
- Multi-resolution fusion(多分辨率融合)将所有的输入通过这个模块融合到高分辨率特征图上。网络首先通过一个卷积层处理输入的不同分辨率卷积层,得到各通道下的适应性权重。随后,应用上采样,将所有输入卷积层上采样到所有输入中的最大size,并根据不同通道权重加权求和。【若只有一个输入路径,例如RefineNet-4,则输入将直接经过此块而不做任何更改。若有多个输入,比如RefineNet-3,输入1为resnet压缩后为1/16原图大小的特征层,输入2为RefineNet-4输出的为1/32原图大小的特征层,则经过RefineNet-3,两个输入会上采样为1/16原图大小的特征层,再加权相加,最后输出1/16原图大小的特征层,作为RefineNet-2的输入。】
- chained residual pooling(串联残差池化)通过残差校正的方式,优化前两步融合得到的分割结果。由一个残差结构、一个池化层和一个卷积层组成。池化层加卷积层用来习得用于校正的残差。Relu对接下来的池化的有效性很重要,还可以使模型对学习率的变化没这么的敏感,这个链式结构能从很大范围区域上获取背景,此外,这个结构中大量使用了identity mapping这样的连接,无论长距离或者短距离,这样的结构允许梯度从一个block直接向其他任一block传播。
- Output convolutions就是输出前再加一个RCU。平衡所有的权重,最终得到与输入空间尺寸相同的分割结果。
- RefineNe用了一个比较巧妙的做法:用前一级的残差结果作为下一级的残差学习模块的输入,而非直接从校正后的分割结果上再重新习得一个独立的残差。这样做的目的,RefineNet的作者是这样解释的:可以使得后面的模块在前面残差的基础上,继续深入学习,得到一个更好的残差校正结果。

7、HRNet

7、Deep layer aggregation
8、Deeply Supervised Salient Object Detection with Short Connections
-
实验数据记录:
| 网络结构 | 数据集 | 结果 |
| FCN-resnet50 · 200epoch · ./params/fcn_resnet50_coco-1167a1af.pth | NEU-seg | global correct: 96.8 average row correct: ['98.4', '77.7', '89.1', '84.3'] IoU: ['96.5', '65.0', '82.6', '74.6'] mean IoU: 79.7 |
| PSP-mobilenet · 200epoch,downsample_factor=16 · 无预训练 --{netmodel_199.pth} | NEU-seg | global correct: 96.3 average row correct: ['98.2', '72.9', '90.1', '74.1'] IoU: ['95.9', '60.6', '83.0', '63.4'] mean IoU: 75.7 |
| PSP-resnet50 · 200epoch,downsample_factor=16 · 无预训练 --{resnet50_netmodel_199.pth} --{resnet50[8]_netmodel_199.pth} | NEU-seg | downsample_factor=16 global correct: 96.4 downsample_factor=8 global correct: 97.2 |
| deeplabV3 · 200epoch,downsample_factor=16 · 无预训练 | NEU-seg | global correct: 97.1 average row correct: ['98.5', '78.0', '91.1', '86.2'] IoU: ['96.8', '67.4', '84.3', '76.5'] mean IoU: 81.3 |
-
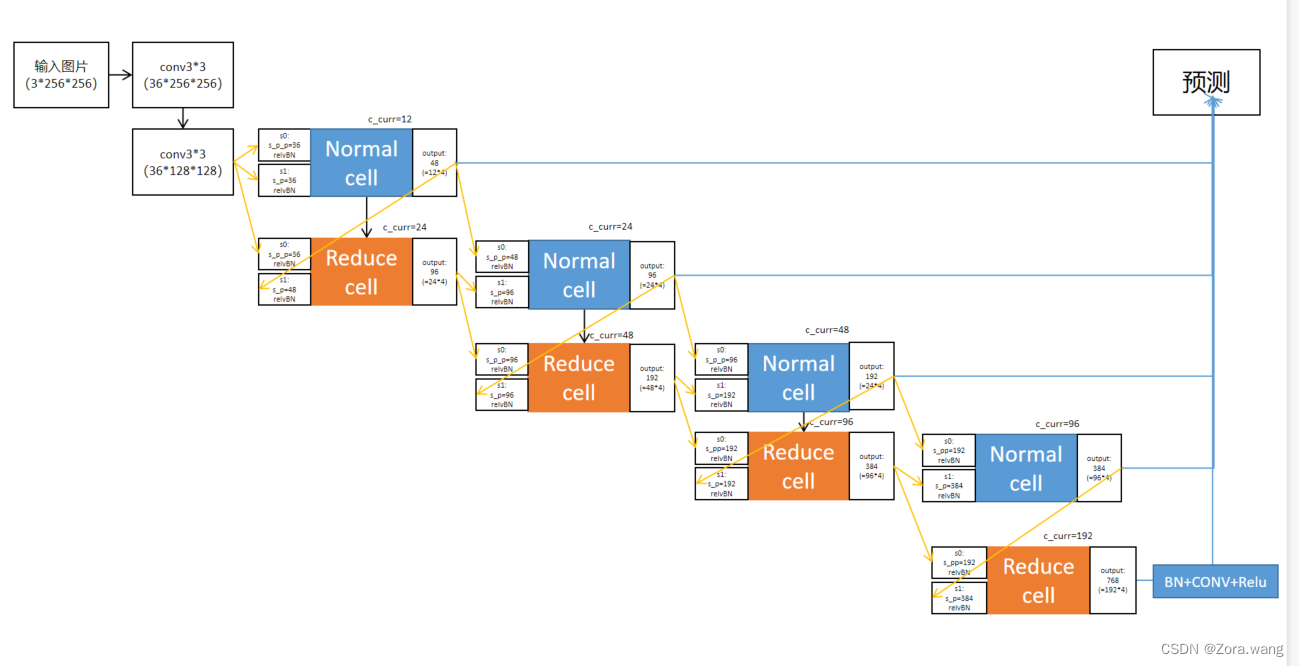
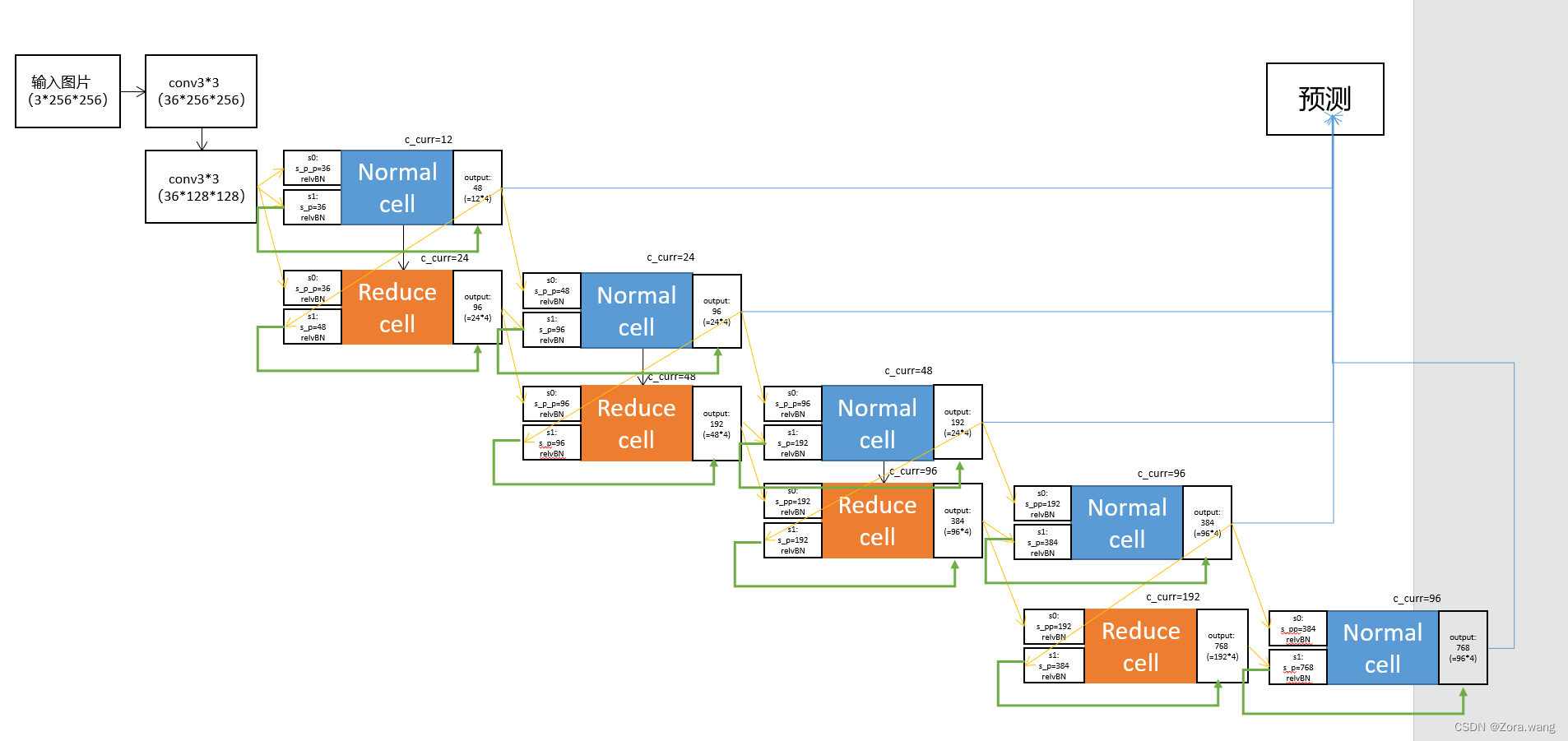
NAS实验数据记录:
| 网络结构 | cell | 结果 |
| normal+reduce(8个)
| DARTS (cell_step=4) | NASNet_zora; 2022-10-21 global correct: 97.9 |
| normal+reduce(8个)
'none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3' 'dil_conv_5x5', | 改变搜索策略为Pdarts P-DARTS (cell_step=4) 【剪枝设置:3.2.2】 这个搜索的效果不好,可能是因为剪枝剪得暴力了。 | NASNet_Pdarts_zora; 2022-10-25; 2022-10-27 08:07:04,838 global correct: 97.9 |
| normal+reduce(8个)
'none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3' 'dil_conv_5x5','conv_7x1_1x7' | 增加了'conv_7x1_1x7'操作,剪枝数量变了 P-DARTS (cell_step=4) 【剪枝设置:3.2.2.1】 ----------------------------------- 做了两次实验: 2022-10-28:取得是过程训练最佳结果的结构; 2022-10-28(1):取得是最后一个结果结构。 | NASNet_Pdarts_zora; 2022-10-28: average row correct: ['99.1', '70.7', '89.4', '84.2'] ---------------------------------- 2022-10-28(1): average row correct: ['99.0', '74.4', '89.9', '86.4'] 【80, 79.9, 79.8, 79.8, 79.6】 |
| normal+reduce(13个)
'none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3' 'dil_conv_5x5','conv_7x1_1x7' | 网络块从8个变成了13个,增加了'conv_7x1_1x7'操作,同样采用Pdarts搜索策略 P-DARTS (cell_step=4) 【剪枝设置:3.2.2.1】 | NASNet12_Pdarts_zora; 2022-10-28; average row correct: ['99.0', '77.4', '89.8', '84.7'] 【79.9, 79.7, 79.6, 79.5, 79.3】 |
| normal+reduce(13个)
| 用了原始的DARTS搜索策略 DARTS (cell_step=4) | NASNet12_zora; 2022-10-31; global correct: 97.9 【78.6, 78.4, 78.2, 78.1, 78.0】 |
| normal+reduce(9个)
'none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3' 'dil_conv_5x5', 'conv_7x1_1x7' | 加残差模块 P-DARTS (cell_step=4) 【剪枝设置:3.2.2.1】 | NasNet_resnet_Pdarts_Zora global correct: 97.9 【78.6, 78.6, 78.5, 78.5, 78.5】 |
| normal+reduce(13个)
'none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3' 'dil_conv_5x5', 'conv_7x1_1x7' | 加残差模块 P-DARTS (cell_step=4) 【剪枝设置:3.2.2.1】 | NasNet12_resnet_Pdarts_Zora global correct: 98.0 【79.4, 79.2, 78.9, 78.9, 78.9,】 |
| normal+reduce(9个)
| 改变通道数12->30,cell变9个,上采样加1*1卷积 P-DARTS (cell_step=4) 【剪枝设置:3.2.2.1】 | NasNet_channel30_Pdarts_Zora global correct: 98.1 【79.9, 79.8, 79.8, 79.7, 79.6】 ---------------------------------- global correct: 98.1 【80.0, 79.8,79.7, 79.6,79.6】 |
| normal+reduce(9个)
| 改变搜索策略:ADARTS (cell_step=4) |
 'none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3' 'dil_conv_5x5',
'none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3' 'dil_conv_5x5',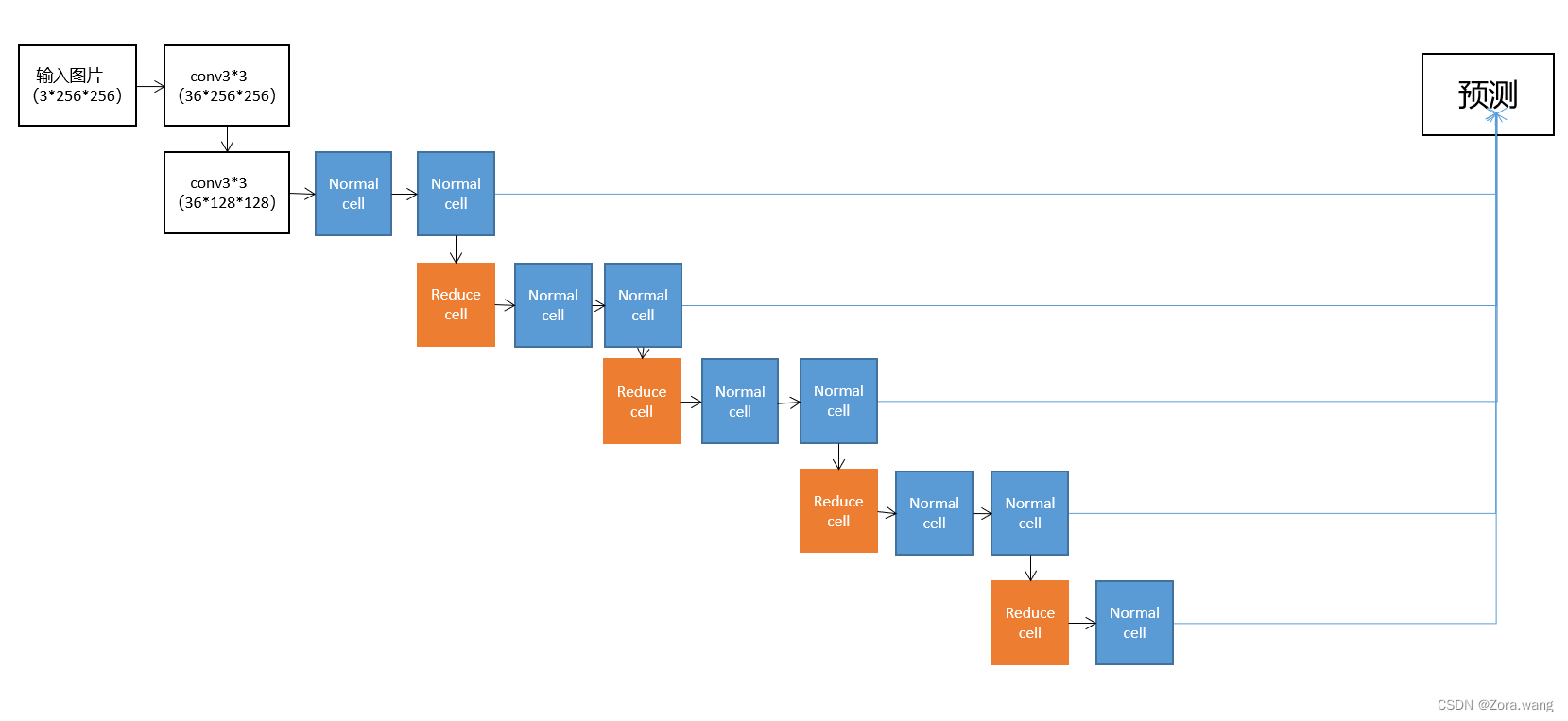

SSD网络结构
(1)采用多尺度特征图用于检测
CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,这正如图3所示,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标。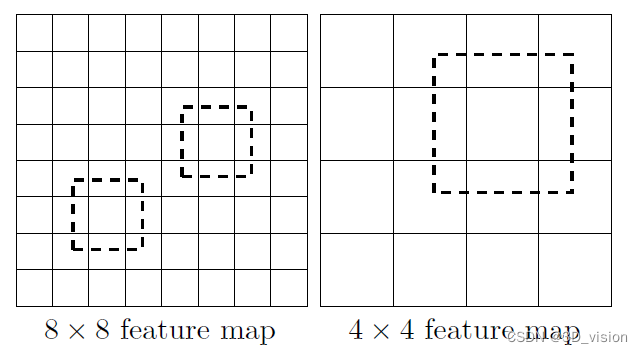
(2)采用卷积进行检测
SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为mnp的特征图,只需要采用33p这样比较小的卷积核得到检测值。
(每个添加的特征层使用一系列卷积滤波器可以产生一系列固定的预测。)
(3)设置先验框
SSD借鉴faster rcnn中ancho理念,每个单元设置尺度或者长宽比不同的先验框,预测的是对于该单元格先验框的偏移量,以及每个类被预测反映框中该物体类别的置信度。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









