






什么是 k k k-NN分类
k
k
k-NN分类器是最简单的机器学习分类算法之一,它的基本思想是:从训练样本集中找出与测试样本“距离”最近的k个样本作为此测试样本的“邻居”,然后根据这k个样本的类别基于一定规则进行投票表决,最高的决定为测试样本的预测类别。用一个词来说就是“近朱者赤近墨者黑”。
由以上所述可以得知,k近邻分类算法主要涉及3个因素:
- k的数值;
- 训练样本集;
- “距离”的衡量标准。
该算法的决策结果仅依赖于距离最近的k个“邻居”的类别。
如图所示的例子中,为方便展示我们所选取的均为二维的数据样本。图中橙色正方形为测试样本,绿色圆圈和蓝色三角形均为已知分类的样本,即训练样本。
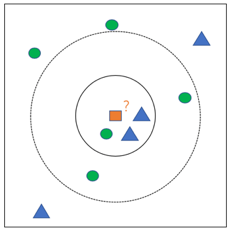
分类过程如下:
- 先确定k的数值大小(一般不大于20),也就是先确定要寻找距离待分类样本距离最近的几个“邻居”,如图所示实线圆圈为k=3,虚线圆圈为k=5;
- 根据事先确定的“距离”的衡量标准(此例使用欧式距离),计算带分类样本到所有训练样本的距离,并在其中找到距离待分类样本距离最近的k个“邻居”;
- 统计这k个邻居的类别,由此得到预测结果。包括简单投票表决和加权投票表决。
如本例所示,当选定k=3时,蓝色三角形有2个,占比例2/3,绿色圆圈有1个,占比例1/3。所以由简单投票表决的话,将橙色方块与蓝色三角形分为同一类。但是当选定k=5时,蓝色三角形有2个,占比例2/5,绿色圆圈有3个,占比例3/5。所以由简单投票表决的话,将橙色方块与绿色圆圈分为同一类。可以看出当k的值选择不同时,分类结果也会因此发生变化,k近邻分类器的分类结果很大程度上依赖于k的选择。
k近邻分类器中的距离一般选择欧式距离
d
E
d_{E}
dE或者曼哈顿距离
d
M
d_{M}
dM。
d
E
=
∑
(
x
k
−
y
k
)
2
)
d_{E} = \sqrt{\sum (x_{k}-y_{k})^{2})}
dE=∑(xk−yk)2)
d
M
=
∑
∣
x
k
−
y
k
∣
d_{M} = \sum \left | x_{k}-y_{k} \right |
dM=∑∣xk−yk∣
k k k-NN分类算法代码
def kNN(k, test_X, train_X, train_Y):
knc = KNeighborsClassifier(n_neighbors=k)
knc.fit(train_X, train_Y)
y_predict = knc.prefict(test_X)
return y_predict
上边为直接引用了Python的sklearn库里的neighbors.KNeighborsClassifier函数,其中test_X为测试样本数据,k为设置的邻居个数,train_X为训练样本数据,train_Y为训练样本标签,返回值y_predict为预测的测试样本标签。下边手写一下:
# k为邻近的样本点数量
def KNN(test_X,k):
predY = []
i=0
for x in test_X:
i+=1
# 计算样本点训练集的欧氏距离
distance = [np.sum(np.power(x_train - x, 2)) for x_train in trainX]
# 按照每个数的索引位置来从小到大排序
indexSort = np.argsort(distance)
# 获得距离样本点最近的K个点的标记值y
nearK_y = [trainY[i] for i in indexSort[:k]]
# print('it is nearK_y',nearK_y)
# 统计邻近K个点标记值的数量
cntY = collections.Counter(nearK_y)
# 返回标记值最多的那个标记
y_predict = cntY.most_common(1)[0][0]
# print( i ,'-------', cntY,y_predict)
predY.append(y_predict)#把标记值最多的标记加入predY数组
return predY
k k k近邻分类器算法的优缺点如下:
(1) 优点:相对于其他算法较为简单,可以很容易的实现。不需要在预测前对模型进行训练,除了k以外没有别的参数需要估计,并且对于多分类问题可以取得不错的效果。
(2) 缺点:不需要在预测前对模型进行训练同样也是k近邻分类器的缺点,这样决定了k近邻分类属于“懒惰学习”[1]。对于每一个测试样本都需要重新算一遍到所有训练样本的距离,计算量大,消耗时间久,内存开销也跟着变大。当样本每一类的数量分布不均匀时,可能会导致输入一个待分类样本时,某一类数量非常多的样本占大多数导致分类精度下降,但是此缺点可以用加权投票表决的方法进行改进,即设置距离近的权值大。
[1] 周志华.机器学习[M].北京:清华大学出版社,2016















 9544
9544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









