






@toc
特征预处理
什么是特征预处理?
包含内容:数值型数据的无量钢化:归一化、标准化
特征预处理API:sklearn.preprocessing
为什么要进行归一化或标准化?
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征
1 归一化
如:在进行欧氏距离时:
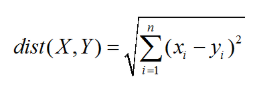
有一组数值太小,对结果影响不大,也就是该属性值无法起到相应作用
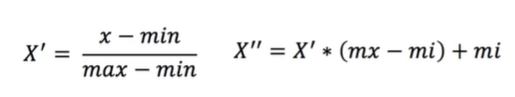
mx、mi:归一化的区间
如:属性:90,100,50
计算:
①X’=(90 - 50)/(100 - 50)
②X’’= X’*(1 - 0) + 0
X’'就是归一化后的值
注意:这种方法鲁棒性较差,只适用传统精准小数据集场景
接口:
sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)...)
feature_range=(0,1) 范围在0到1
MinMaxScaler.fit_transform(X)
X:numpy array 格式的数据[n_samples, n_features]
返回值:转换后的形状相同的array
def minmax_demo():
"""
归一化
:return:
"""
# 1、获取数据
data = pd.read_csv("dating.txt")
# 所有行,前三列
data = data.iloc[:, :3]
print("data:\n", data)
# 2、实例化一个转换器类
transfer = MinMaxScaler(feature_range=[2, 3])
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









