






简介
很多算法可以回归也可以分类
把连续值变为离散值:
1.回归模型可以做分类:可以依据阀值(二元分类或多元分类)来分类
2.逻辑回归二元分类,一个阀值。
3.连续值进行分箱,实现多元分类
4.把离散值变为连续值:插值法(1~2,在离散值之间插入足够密集的值)
降维算法
1.特征过多:特征工程、筛选特征
2.单个特征维度过高
3.通过降维算法来避免维度灾难。
4.通过将降维放入特征工程范畴,降维往往是中间过程。
5.线性降维、非线性降维
6.可以归纳到非监督学习范畴,有些算法需要一些标签来验证,这些标签不是用来训练模型,只是用来验证
7.将高维度空间降低到低维度特征空间,过程中损失信息越少越好。(距离矩阵不变、权重矩阵不变)
PCA降维(主成分分析)
1.方差用来衡量数据离散程度,方差越大范围越小。
2.只是最大化类间样本的方差。最大可能保留数据之间的信息。
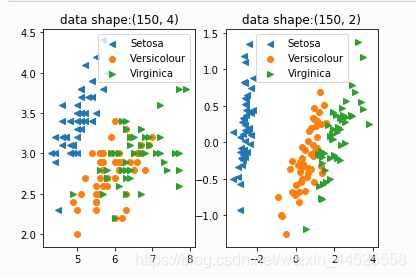
例一:
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn import decomposition
from sklearn import datasets
centers = [[1, 1], [-1, -1], [1, -1]]
iris = datasets.load_iris()
X = iris.data
y = iris.target
plt.subplot(121)
for name, label, m in [('Setosa', 0, "<"), ('Versicolour', 1, "o"), ('Virginica', 2, ">")]:
plt.scatter(X[y==label, 0], X[y==label,1], label=name, marker=m)
plt.legend()
plt.title("data shape:%s"%(X.shape,))
plt.subplot(122)
pca = decomposition.PCA(n_components=2) # n_components:目标维度
pca.fit(X)
X = pca.transform(X)
for name, label, m in [('Setosa', 0, "<"), ('Versicolour', 1, "o"), ('Virginica', 2, ">")]:
plt.scatter(X[y==label, 0], X[y==label,1], label=name, marker=m)
plt.legend()
plt.title("data shape:%s"%(X.shape,))
plt.show()
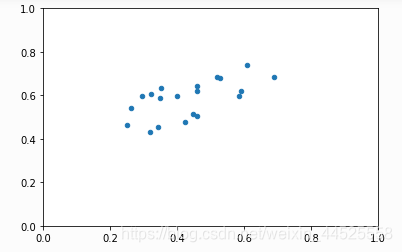
例二:
import matplotlib.pyplot as plt
import numpy as np
mean = [0, 0]
cov = [[1, 0], [0, 100]]
x, y = np.random.multivariate_normal(mean, cov, 5000).T
np.random.seed(1)
X = (np.random.rand(20)+0.5)/2
Y = X*0.4 + np.random.rand(20)/5 + 0.3
plt.scatter(X, Y, s=20)
plt.xlim((0, 1))
plt.ylim((0, 1))
print(X, Y)
plt.show()
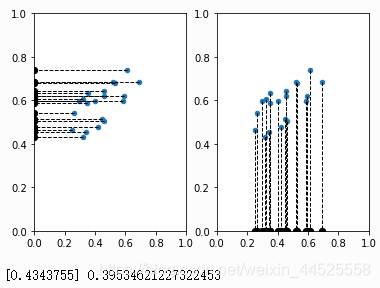
plt.subplot(121)
plt.scatter(X, Y, s=20)
for idx, x in enumerate(X):
plt.plot((x, 0), (Y[idx], Y[idx]), 'k--', linewidth=1)
plt.scatter((0,), (Y[idx],), color='k', s=40)
plt.xlim((0, 1))
plt.ylim((0, 1))
plt.subplot(122)
plt.scatter(X, Y, s=20)
for idx, x in enumerate(X):
plt.plot((x, x), (Y[idx], 0), 'k--', linewidth=1)
plt.scatter((x,), (0,), color='k', s=40)
plt.xlim((0, 1))
plt.ylim((0, 1))
plt.show()
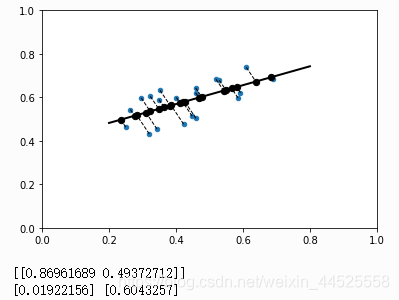
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit(X.reshape(-1, 1), Y)
print(reg.coef_, reg.intercept_)
def f(x):
return x*reg.coef_[0]+reg.intercept_
plt.scatter(X, Y, s=20)
plt.plot((0.2, 0.8), (f(0.2), f(0.8)), 'k', linewidth=2)
for idx, x in enumerate(X):
coef = -1/reg.coef_[0]
cept = Y[idx]-coef*x
c_x = (cept-reg.intercept_)/(reg.coef_[0]-coef)
c_y = f(c_x)
plt.plot((x, c_x), (Y[idx], c_y), 'k--', linewidth=1)
plt.scatter((c_x,), (c_y,), color='k', s=40)
plt.xlim((0, 1))
plt.ylim((0, 1))
plt.show()
from sklearn.decomposition import PCA
pca = PCA(n_components=1).fit(np.concatenate((X.reshape(-1, 1), Y.reshape(-1, 1)), axis=1))
print(pca.components_)
print(pca.explained_variance_, pca.singular_values_)

例三:
import ssl
try:
_create_unverified_https_context = ssl._create_unverified_context
except AttributeError:
pass
else:
# Handle target environment that doesn't support HTTPS verification
ssl._create_default_https_context = _create_unverified_https_context
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_olivetti_faces
from sklearn import decomposition
n_row, n_col = 2, 4
n_components = n_row * n_col
image_shape = (64, 64)
# #############################################################################
# Load faces data
dataset = fetch_olivetti_faces(shuffle=True)
faces = dataset.data
n_samples, n_features = faces.shape
faces -= faces.mean(axis=1).reshape(n_samples, -1)
def plot_gallery(title, images, n_col=n_col, n_row=n_row):
plt.figure(figsize=(2. * n_col, 2.26 * n_row))
plt.suptitle(title, size=16)
for i, comp in enumerate(images):
plt.subplot(n_row, n_col, i + 1)
vmax = max(comp.max(), -comp.min())
plt.imshow(comp.reshape(image_shape), cmap=plt.cm.gray,
interpolation='nearest',
vmin=-vmax, vmax=vmax)
plt.xticks(())
plt.yticks(())
plt.subplots_adjust(0.01, 0.05, 0.99, 0.93, 0.04, 0.)
plot_gallery("Olivetti faces", faces[:n_components])
estimator = decomposition.PCA(n_components=n_components, svd_solver='randomized',
whiten=True)
estimator.fit(faces)
plot_gallery('Eigen faces', estimator.components_[:n_components])
plt.show()

LDA降维(线性判别分析)
是有监督的线性分类器: fit()
LDA与PCA最大区别:最大化类间样本的方差,最小化类内样本的方差
例一:
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
iris = datasets.load_iris()
X = iris.data
y = iris.target
# plt.subplot(131)
# for name, label, m in [('Setosa', 0, "<"), ('Versicolour', 1, "o"), ('Virginica', 2, ">")]:
# plt.scatter(X[y==label, 0], X[y==label,1], label=name, marker=m)
# plt.legend()
# plt.title("data shape:%s"%(X.shape,))
plt.subplot(121)
pca = PCA(n_components=2)
pca.fit(X)
X_pca = pca.transform(X)
for name, label, m in [('Setosa', 0, "<"), ('Versicolour', 1, "o"), ('Virginica', 2, ">")]:
plt.scatter(X_pca[y==label, 0], X_pca[y==label,1], label=name, marker=m)
plt.legend()
plt.title("PCA")
print(pca.explained_variance_ratio_)
plt.subplot(122)
lda = LDA( n_components=2).fit(X, y)
X_lda = lda.transform(X)
for name, label, m in [('Setosa', 0, "<"), ('Versicolour', 1, "o"), ('Virginica', 2, ">")]:
plt.scatter(X_lda[y==label, 0], X_lda[y==label,1], label=name, marker=m)
plt.legend()
plt.title("LDA")
print(pca.explained_variance_ratio_)
print(lda.explained_variance_ratio_)
plt.show()
结果为:
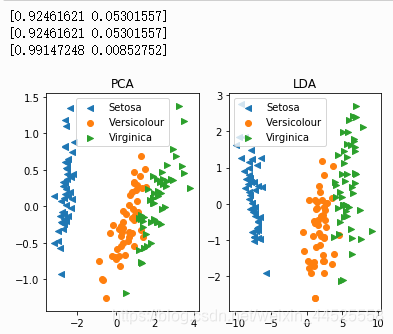
例二:
import matplotlib.pyplot as plt
import numpy as np
mean = [0, 0]
cov = [[1, 0], [0, 100]]
x, y = np.random.multivariate_normal(mean, cov, 5000).T
np.random.seed(1)
X = (np.random.rand(20)+0.5)/2
Y = X*0.4 + np.random.rand(20)/5 + 0.3
# X1 = (np.random.rand(20)+0.5)/2 +0.3
# Y1 = X*0.7 + np.random.rand(20)/5 + 0.2
# X = np.concatenate((X, X1))
# Y = np.concatenate((Y, Y1))
T = np.array(X/2+Y>0.7)
# T = np.random.choice(2, X.shape[0])
# T = np.concatenate((np.zeros(X.shape[0]//2), np.ones(X.shape[0]//2)))
T = T + np.zeros(X.shape[0])
T[14] = 1
plt.scatter(X[T==0], Y[T==0], s=20, color='r', marker='o')
plt.scatter(X[T==1], Y[T==1], s=20, color='b', marker='x')
plt.xlim((0.2, 0.8))
plt.ylim((0.2, 0.8))
print(X, Y)
plt.show()
# plt.subplot(121)
# plt.scatter(X[T==0], Y[T==0], s=20, color='r')
# plt.scatter(X[T==1], Y[T==1], s=20, color='b')
# for idx, x in enumerate(X):
# plt.plot((x, 0), (Y[idx], Y[idx]), 'k--', linewidth=1)
# plt.scatter((0,), (Y[idx],), color='k', s=40)
# plt.xlim((0, 1))
# plt.ylim((0, 1))
# plt.subplot(122)
# plt.scatter(X, Y, s=20)
# for idx, x in enumerate(X):
# plt.plot((x, x), (Y[idx], 0), 'k--', linewidth=1)
# plt.scatter((x,), (0,), color='k', s=40)
# plt.xlim((0, 1))
# plt.ylim((0, 1))
# plt.show()
plt.subplot(121)
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit(X.reshape(-1, 1), Y)
print(reg.coef_, reg.intercept_)
def f(x):
return x*reg.coef_[0]+reg.intercept_
plt.scatter(X[T==0], Y[T==0], s=20, color='r', marker='o')
plt.scatter(X[T==1], Y[T==1], s=20, color='b', marker='x')
plt.plot((0.2, 0.8), (f(0.2), f(0.8)), 'k', linewidth=2)
for idx, x in enumerate(X):
coef = -1/reg.coef_[0]
cept = Y[idx]-coef*x
c_x = (cept-reg.intercept_)/(reg.coef_[0]-coef)
c_y = f(c_x)
plt.plot((x, c_x), (Y[idx], c_y), 'k--', linewidth=1)
plt.scatter((c_x,), (c_y,), color='k', s=20)
plt.xlim((0.2, 0.8))
plt.ylim((0.2, 0.8))
plt.title("PCA")
plt.subplot(122)
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
lda = LDA(solver="svd", n_components=2).fit(np.concatenate((X.reshape(-1, 1), Y.reshape(-1, 1)), axis=1), T)
from sklearn import linear_model
print(lda.coef_, lda.intercept_, T)
lda_coef = lda.coef_[0][1]/lda.coef_[0][0]
lda_intercept = lda.intercept_[0] /lda.coef_[0][0]
def f(x):
return x*lda_coef + lda_intercept
plt.scatter(X[T==0], Y[T==0], s=20, color='r', marker='o')
plt.scatter(X[T==1], Y[T==1], s=20, color='b', marker='x')
plt.plot((0.41, 0.45), (f(0.41), f(0.45)), 'k', linewidth=2)
for idx, x in enumerate(X):
coef = -1/lda_coef
cept = Y[idx]-coef*x
c_x = (cept-lda_intercept)/(lda_coef-coef)
c_y = f(c_x)
plt.plot((x, c_x), (Y[idx], c_y), T[idx]==0 and 'r--' or 'b--', linewidth=1)
plt.scatter((c_x,), (c_y,), color=(T[idx]==0 and 'k' or 'k'), s=20)
plt.xlim((0.2, 0.8))
plt.ylim((0.2, 0.8))
plt.title("LDA")
plt.show()
结果为:
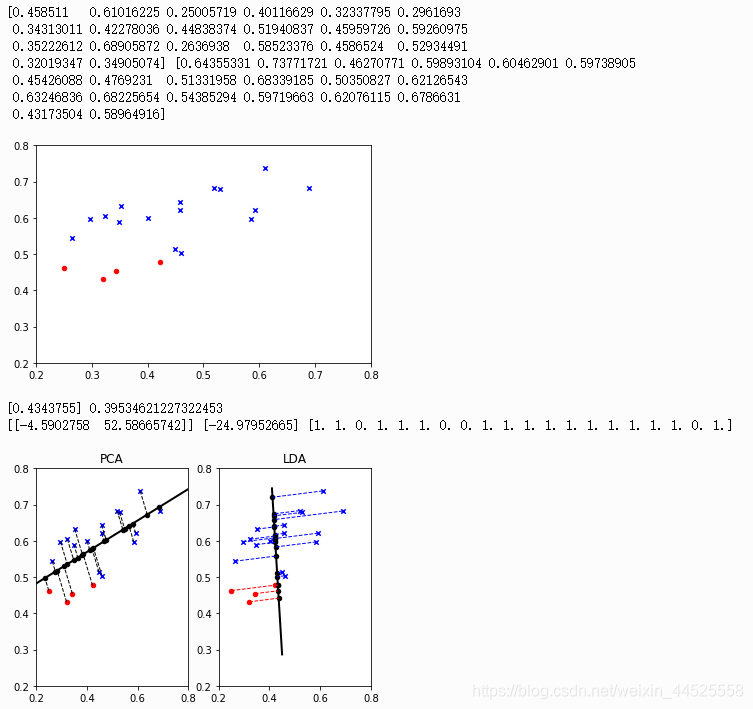
MDS降维(多维标度法)
已知样本两两之间的距离,如何恢复所有样本的坐标?
常用于市场调研、心理学数据分析
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import PCA
from sklearn.manifold import MDS
iris = datasets.load_iris()
X = iris.data
y = iris.target
plt.subplot(121)
pca = PCA(n_components=2)
pca.fit(X)
X_pca = pca.transform(X)
for name, label, m in [('Setosa', 0, "<"), ('Versicolour', 1, "o"), ('Virginica', 2, ">")]:
plt.scatter(X_pca[y==label, 0], X_pca[y==label,1], label=name, marker=m)
plt.legend()
plt.title("PCA")
print(pca.explained_variance_ratio_)
plt.subplot(122)
mds = MDS( n_components=2, metric=True)
X_mds = mds.fit_transform(X)
for name, label, m in [('Setosa', 0, "<"), ('Versicolour', 1, "o"), ('Virginica', 2, ">")]:
plt.scatter(X_mds[y==label, 0], X_mds[y==label,1], label=name, marker=m)
plt.legend()
plt.title("MDS")
plt.show()
结果:
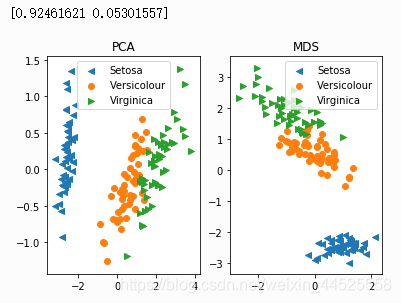
流形学习Isomap
流形学习是非线性降维的主要方法
是MDS在流形学习上的扩展
将非欧几里德空间转换从欧几里德空间
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import PCA
from sklearn.manifold import Isomap
iris = datasets.load_iris()
X = iris.data
y = iris.target
plt.subplot(221)
X_pca = PCA( n_components=2).fit_transform(X)
for name, label, m in [('Setosa', 0, "<"), ('Versicolour', 1, "o"), ('Virginica', 2, ">")]:
plt.scatter(X_pca[y==label, 0], X_pca[y==label,1], label=name, marker=m)
plt.legend()
plt.title("PCA")
for idx, neighbor in enumerate([2, 20, 100]):
plt.subplot(222 + idx)
isomap = Isomap( n_components=2, n_neighbors=neighbor)
X_isomap = isomap.fit_transform(X)
for name, label, m in [('Setosa', 0, "<"), ('Versicolour', 1, "o"), ('Virginica', 2, ">")]:
plt.scatter(X_isomap[y==label, 0], X_isomap[y==label,1], label=name, marker=m)
plt.legend()
plt.title("Isomap (n_neighbors=%d)"%neighbor)
plt.show()
结果:
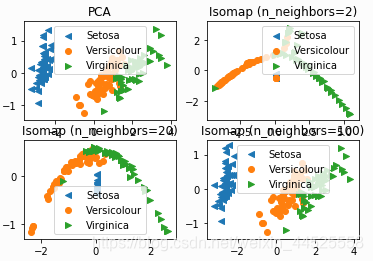














 2495
2495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









