







Rank-consistent Ordinal Regression for Neural Networks
摘要
分类任务的网络结构已经得到显著的发展,但是常用的损失函数(例如多类别交叉熵)不能解决ranking(排名)和序数回归的问题。
本文作者提出了一个新框架(Consistent Rank Logits,CORAL),该框架具有rank-monotonicity(排名单调性) and consistent confidence scores(置信分数一致性)的理论保证。预测一致性问题(后面有讲)
通过参数共享,降低了训练复杂度并且可以将其扩展到CNN网络结构中用于有序回归的任务。
此外,该方法在一系列用于年龄预测的人脸图像数据集上的经验评估表明,与目前最先进的有序回归方法相比,有很大的改进。(实验证明方法的有效性)
1.介绍
除年龄估计 [ 17 ]以外,序数回归的流行应用包括预测各种疾病的进展,例如阿尔茨海默氏症[ 8 ],克罗恩氏症 [ 36 ],动脉[ 34 ]和肾脏疾病[ 32 ]。同样,序数回归模型是文本消息广告[ 26 ]和各种推荐系统[ 18 ]的常见选择
常见的分类任务忽略了类别之间的顺序性,8提出扩展二分类进行有序回归的框架,但是会有分类器不一致的现象
本文作者提出了一种方法和定理保证了分类器的一致性,并且容易扩展到现有算法中使用,并且在人脸数据集上验证了算法的有效性。
2.相关工作
A. 有序回归和排名(ranking)
过去,针对线性回归已经开发了几种广义线性模型的多元扩展。
有序回归,早期14 15使用感知器和SVM,15提出了一个通用的简约框架。
1 将K ranks任务转变成K-1个二分类器,第k个任务去判断人脸年龄是否超过 r k r_k rk ,所有K - 1任务共享相同的中间层,但在输出层分配不同的权重参数。但是该方法不能保证预测一致性。论文中举了一个例子,假如第k个分类器预测年龄超过30岁,但是第k-1个分类器预测年龄低于20岁,最后的得到的预测年龄将是一个矛盾的现象。
1 作者中提出了此分类器在一致性问题上并不理想,并且要保证一致性的话会造成训练复杂度,本文作者就是在确保一致性的基础上,不增加复杂度。
B. CNN Architectures for Age Estimation
目前最先进的年龄估计方法都是使用CNN架构。1 21 —24
1 :单独训练二分类器,最后结合无关的预测结果用于排序ranking
24 :ranking-CNN,训练CNNs的ensemble,最后结合预测结果,实验显示结果优于单个模型,但是增加复杂度&出现不一致问题。
26 :siamese CNN,只有一个输出单元跟目前看到的输出不太一样,看看?
多任务CNN相比共享浅层参数的单个CNN来说performance要好
3.提出的方法
本节描述了所提出的CORAL框架,该框架解决了基于多个二进制分类任务进行排序的有序回归CNNs中分类器不一致的问题。
A. Preliminaries
符号说明:
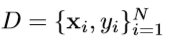
其中
x
i
x_i
xi表示第i张图片,
y
i
y_i
yi 表示相应的rank值,D表示dataset,N表示样本数
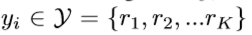
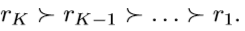
≻ \succ ≻ 表示排序的顺序,有序回归的任务就是找到一个排序规则 h : X → Y h : X \rightarrow Y h:X→Y ,最小化loss(h)
cost matrix : C ∈ K ∗ K C ∈ K*K C∈K∗K
C y , r k C_{y,r_k} Cy,rk 表示将一个样本 ( x , y ) (x,y) (x,y) 预测为 rank $r_k 的 损 失 , 的损失, 的损失,C_{y,y} = 0 ; 当 ;当 ;当y \neq r_k时,C_{y,r_k} > 0$
在有序回归任务中,cost matrix的每一行是个V型。
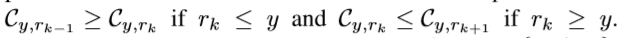
classification cost matrix :
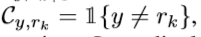
没有考虑到顺序信息。
absolute cost matrix :
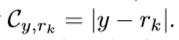
8 提出一个每一行都是凸的cost matrix
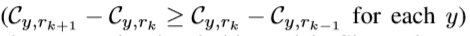
“ rank-monotonic threshold model ”,训练复杂度高,在实践中不可行
我们提出的CORAL框架既不需要具有凸条件的cost matrix,也不需要依赖于每个训练示例的显式加权项来获得rank单调阈值模型,也不需要为每个二元任务生成一致的预测。此外,CORAL允许一个可选的任务重要性加权。例如,可以使用非统一任务重要性权重的可选分配来解决标签不平衡(第三- e节),这使得CORAL框架更适用于真实世界的数据集。
B. Ordinal Regression with a Consistent Rank Logits Model
a) Label Extension and Rank Prediction
数据集
D
=
{
X
i
,
Y
i
}
i
=
1
N
D = \{X_i,Y_i\}_{i=1}^N
D={Xi,Yi}i=1N,rank label:
y
i
y_i
yi ,binary label :
y
i
(
1
)
,
.
.
.
,
y
i
(
K
−
1
)
y_i^{(1)},...,y_i^{(K-1)}
yi(1),...,yi(K−1),
y
i
k
∈
{
0
,
1
}
y_i^{k} \in \{0,1\}
yik∈{0,1}
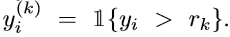
K - 1二分类任务具有相同的权值参数,但具有独立的偏差单元,解决了预测之间的不一致问题,降低了模型的复杂性(图1)。
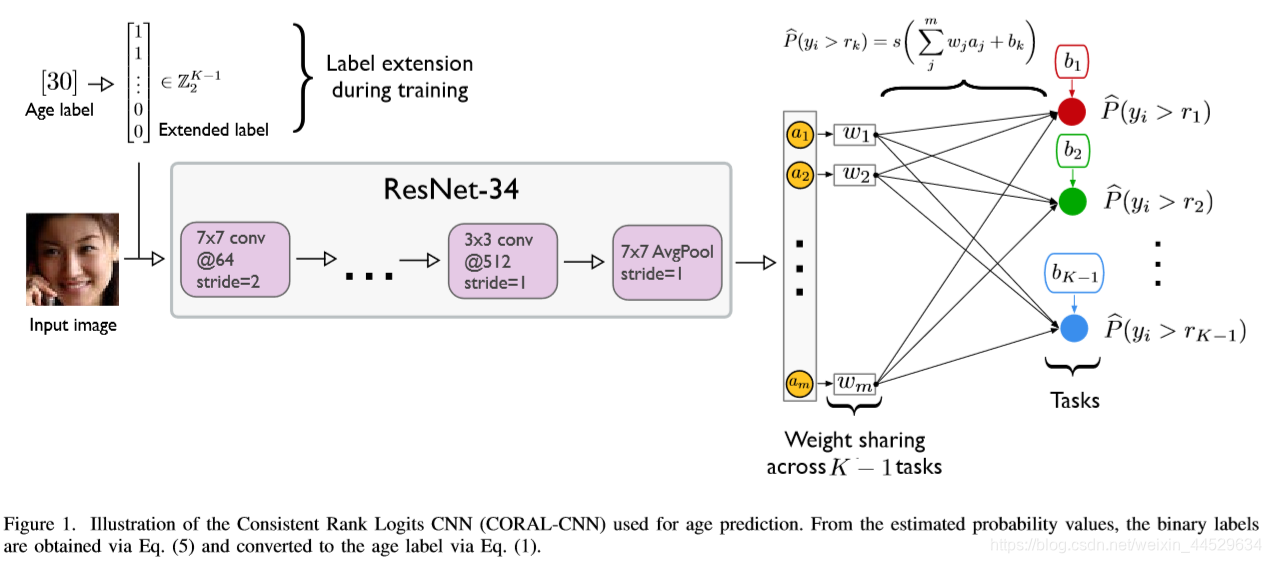
extend label
label = self.y[index] # 3,对应afad_train1.csv中的age,真实的age=3+15
levels = [1]*label + [0]*(NUM_CLASSES - 1 - label) #把label变为extend label
levels = torch.tensor(levels, dtype=torch.float32)
output:
3
[1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
给定输入
x
i
x_i
xi,其输出通过如下公式计算得到:
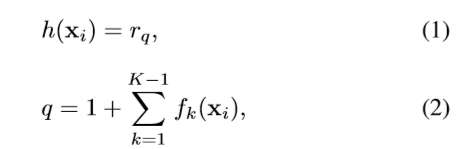
f
k
(
x
i
)
∈
{
0
,
1
}
f_k(x_i) \in \{ 0,1\}
fk(xi)∈{0,1}表示第 k 个分类器的预测值,并且要求
{
f
k
}
k
=
1
K
−
1
\{f_k\}_{k=1}^{K-1}
{fk}k=1K−1有有序信息&rank单调性
f
1
(
x
i
)
≥
f
2
(
x
i
)
≥
.
.
.
,
f
K
−
1
(
x
i
)
f_1(x_i) \geq f_2(x_i)\geq ..., f_{K-1}(x_i)
f1(xi)≥f2(xi)≥...,fK−1(xi),保证了预测的一致性
b) Loss Function
W W W表示出了bias的所有权重参数,倒数第二层的输出: G ( X i , W ) G(X_i,W) G(Xi,W)
最后一层对应的二进制分类器的输入(加上各自的bias): { G ( X i , W ) + b k } k = 1 K − 1 \{G(X_i,W)+b_k\}_{k=1}^{K-1} {G(Xi,W)+bk}k=1K−1
第k个任务的经验概率预测值:
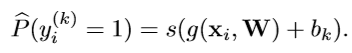
最小化损失函数:(weighted cross-entropy of K−1 binary classifiers)
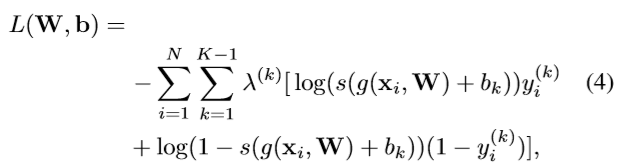
λ
(
k
)
\lambda ^{(k)}
λ(k) denotes the weight of the loss associated with the kth classifier (assuming
λ
(
k
)
\lambda ^{(k)}
λ(k) > 0).
λ ( k ) \lambda ^{(k)} λ(k) 表示任务k的重要性参数。
def cost_fn(logits, levels, imp):
val = (-torch.sum((F.logsigmoid(logits)*levels
+ (F.logsigmoid(logits) - logits)*(1-levels))*imp,
## 此处的loss代码有问题嘛?
dim=1))
return torch.mean(val)
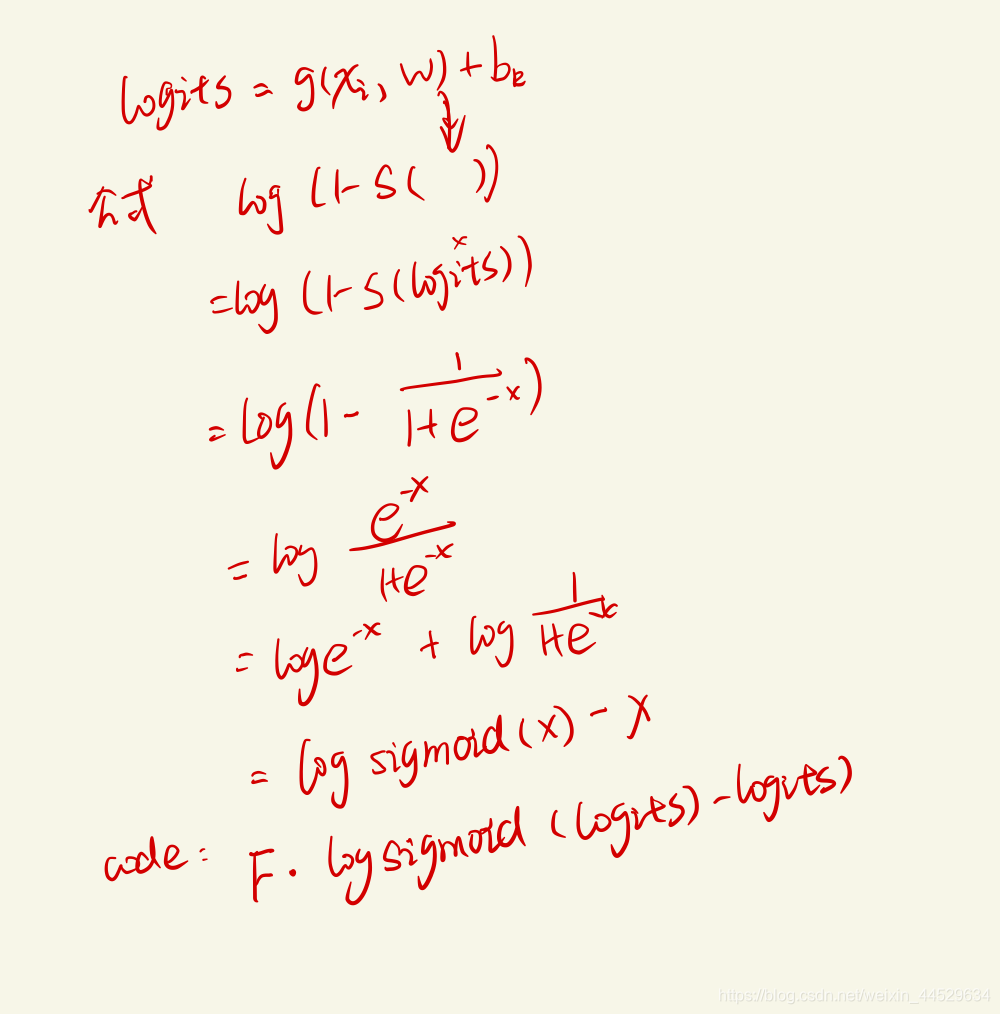
按照代码的意思,log是以e为底,化简后的形式
当概率值大于0.5时(二分类任务),第k个任务的输出预测值为1
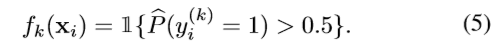
对于鲁棒性不好,或者难以优化的任务,考虑使用non-uniform的任务权重机制。【 III-E】
接下来就是理论验证分类器一致性
**C. Theoretical Guarantees for Classifier Consistency **
最小化Loss,学习到的bias是非增的,(定义1给出了证明)
E. Task Importance Weighting
某些相邻等级之间的特性可能有更细微的区别。例如,面部老化通常被认为是一个非平稳的[27]过程,在一定的年龄区间内,面部特征的变化可以更容易检测到。
weighting scheme:考虑了数据集的类别不平衡(label imbalances) ,V-C部分表示此方法在四个数据集上better
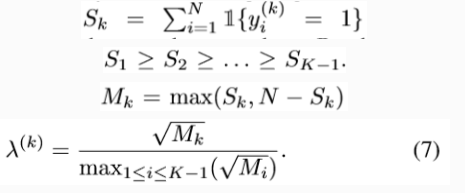
4.实验
A.数据集和预处理
MORPH-2 & CACD:使用MLxtend v0.14的facial landmark detection将鼻尖置于图片正中
80%训练集,20%测试集
training:resize:(128x128x 3)然后随机裁剪成120x120x3(augment)
testing:resize:(128x128x 3)然后中心裁剪成120x120x3
B. CNN结构
resnet-34:替换最后一层(改为K-1个二分类器)+[1] LOSS(将交叉熵改为自己设计的) ===>OR-CNN
CORAL-CNN相较于OR-CNN有较少的参数量
OR-CNN:(m+1)(K-1)*2
coral-cnn:m+k-1
C. Training and Evaluation
MAE:平均绝对误差
RMSE:均方根误差
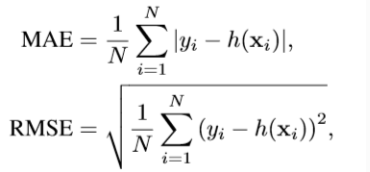
y
i
y_i
yi表示ground-truth,
h
(
x
i
)
h(x_i)
h(xi)表示预测rank。
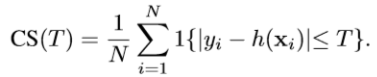
cs 曲线证明其performance better
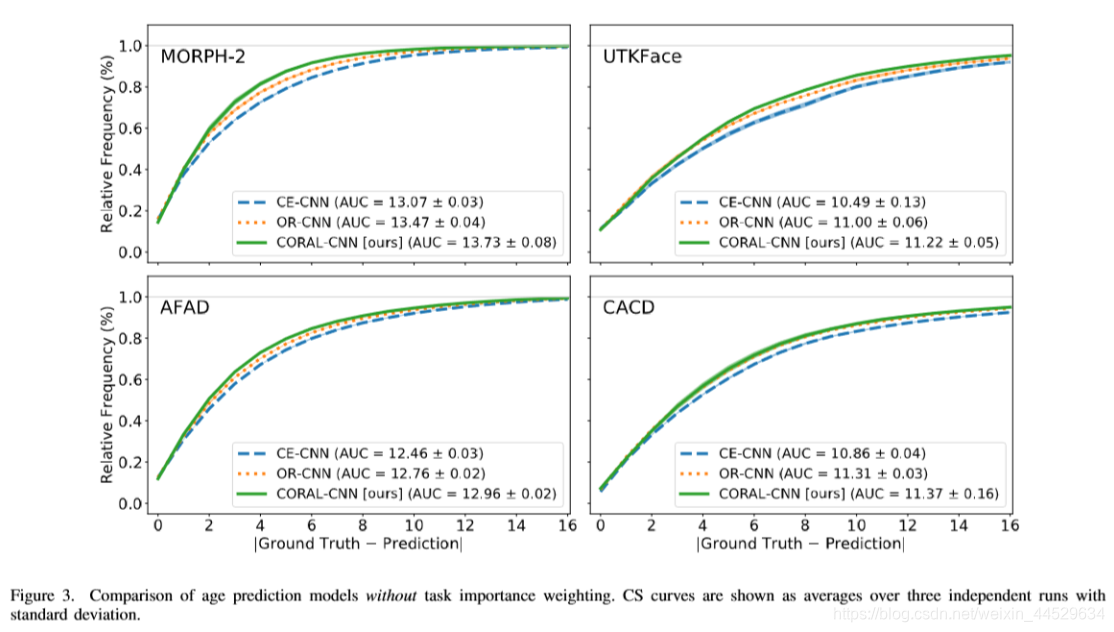
随机种子设置三次,以随机初始化三次weight(不同模型要保证随机种子一致)
所有CNN模型训练200epoch,SGD,指数衰减率 β 0 = 0.90 \beta_0 = 0.90 β0=0.90 和 β 2 = 0.99 \beta_2 = 0.99 β2=0.99(默认值)
learning rate: α = 5 ∗ 1 0 − 5 \alpha = 5*10^{-5} α=5∗10−5 best,且都是在200个epoch后模型收敛
代码中除了ResNet-34,还有Inception-v3和VGG-16的模型
D. Hardware and Software
- PyTorch 1.1.0
- NVIDIA GeForce 1080Ti
- Titan V graphics cards
- https://github.com/Raschka-research-group/coral-cnn
5. 实验结果和讨论
Estimating the Apparent Age from Face Images
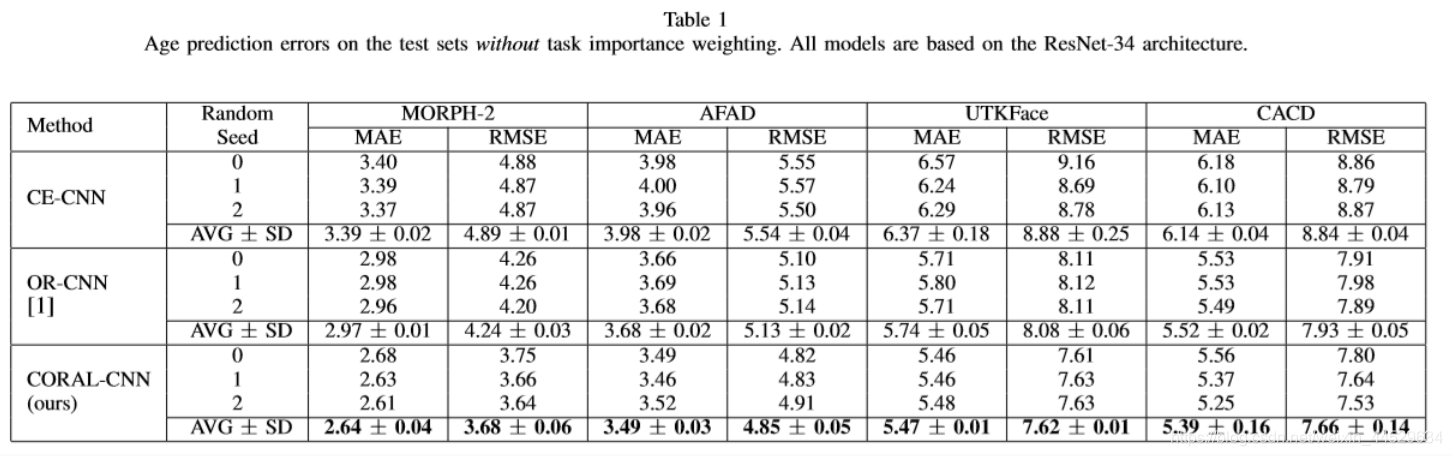
Table1中显示了OR-CNN和CORAL-CNN模型优于CE-CNN,其中CORAL-CNN best
MORPH-2 > AFAD > CACD > UTKFace
原因: MORPH-2数据集质量比较好
AFAD中低分辨率(20*20), UTKFACE比AFAD ten times smaller(指的是数据集数量)
由于CACD的大小与AFAD大致相同,所以性能较低可能是由于需要考虑的年龄范围更广(CACD为14-62岁,AFAD为15-40岁)。
6.数据集搜集
1、关于人脸
https://blog.csdn.net/qq_22734083/article/details/87868387
本文用到的四个数据集
1.1 MORPH2 (2006)
下载:http://www.faceaginggroup.com/morph/
论文:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1613043
根据论文引用情况,MORPH2数据集是目前最流行的年龄估计数据集之一,该数据集的准确率近年也已趋近饱和。MORPH2也是一个跨时间的数据集,收录了同一个人在不同年龄段的图片。该数据集分为商用和学术用版本,学术用版本包括了13000个人的55134张图片,照片收集时间跨度2003-2007年,人物年龄为16-77岁,平均年龄为33岁。MORPH2数据集除年龄外还记录了人物的其他信息,如性别、种族、是否戴眼镜等。
1.2 CACD(2014)
下载:http://bcsiriuschen.github.io/CARC/
论文:http://cmlab.csie.ntu.edu.tw/~sirius42/papers/chen14eccv.pdf
CACD收集了2000个名人的163,446张图片,年龄跨度为16 到 62。截止论文发表时间,是当时最大规模的跨年龄数据集。收集照片的时间跨度为2004-2013年。数据集同时也提供了16个人脸关键点的标注信息。CACD数据集提供者明确指出,虽然该数据集包含人物年龄信息,但只建议使用此数据集做跨年龄人物检索,不建议使用该数据集来做年龄预估。
1.3 AFAD(2016)
下载:https://github.com/afad-dataset/tarball
论文:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Niu_Ordinal_Regression_With_CVPR_2016_paper.pdf
数据集【4】规模为164432张脸,其中63680张女性、100752男性。年龄段为15-40岁。该数据集的特点是数据几乎全是中国人。该数据的数据来源为人人网,首先爬取人人网上的图片数据并获取相册所有者的年龄,然后使用人力对错误图片进行过滤。本数据年龄分布也不是很均衡,在最年轻和年纪较大的年龄段数据较少(也好理解,因为该年龄使用人人网的人少)。
根据观察,感觉数据集整体标注效果比较准确,但有一些小图片(22*22)看不清楚,且有很多同一个人的图片几乎完全一样。数据集还有一个特点就是图片截取的较小,只留了较少的脸部,发型和颈部都去除了。其实年龄估计和人的发型、身体等也有一定联系,截取太小将无法使用到这些信息
1.4 UTKFace(2017)
下载:https://susanqq.github.io/UTKFace/
论文:https://arxiv.org/pdf/1702.08423.pdf
UTKFace数据集是一个具有较长年龄跨度(范围从0到116岁)的大型人脸数据集。该数据集包含20,000多张面部图像,其中包含年龄,性别和种族的注释。图像覆盖了姿势,面部表情,光照,遮挡,分辨率等的大变化。该数据集可用于各种任务,例如,面部检测,年龄估计,年龄进展/回归,地标定位等。
7. 代码
在代码设计部分,包括了OR-CNN和CORAL-CNN
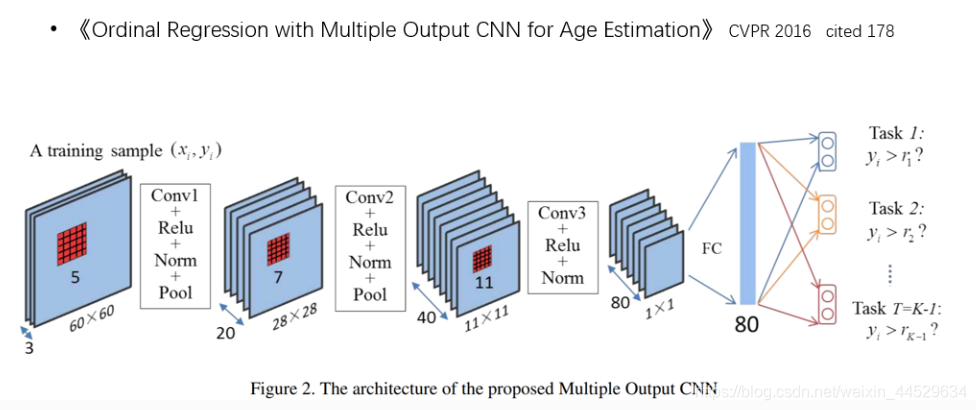
afad-ordinal.py(网络结构如上)
afad-coral.py(本论文的网络结构)

















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









