







Soft Labels for Ordinal Regression
CVPR-2019
Abstract
提出了简单有效的方法约束类别之间的关系(其实就是在输入的label中考虑到类别之间的顺序关系)
这种encoding使得NN可以自动学习类内和类间的关系,不需要显示修改网络结构
我们的方法将数据标签转换成软概率分布,使其与常见的分类损失函数(如交叉熵)很好的匹配
结果表明,该方法在图像质量排序、年龄估计、地平线回归和单目深度估计四种不同的情况下都是有效的。
1. Introduction
有序分类又称有序回归,是机器学习任务的一种,类似于实值度量的传统回归和独立、多分类任务的混合
举例:电影评级、用户满意度调查
有序回归解决的问题:not all wrong classes are equally wrong
前人研究【21】【14】【9】【37】
回归角度:把输入映射到一条实线上,然后根据决策面(线 boundaries )预测最终的输出
分类角度:采用K-rank公式把问题转化为多个等级或阈值问题~~(将多分类任务转化成多个二分类任务)~~
【14】举例:K-1个二分类器,每个分类器都被拿去训练对于输入的x,是否有输出y>k,(注意与前面的大K不一样,这里k表示这个二分类器的等级)《A simple approach to ordinal classification 》ECML 2001 温度的例子
结论:这个方法用在神经网络进行分类任务特别适合
本文贡献:提出一种将问题看作分类任务的有序回归方法;
提出soft target encoding scheme for data labels (这个encoding可以很好地和CNN结合用于分类任务)
结果显示soft优于hard one-hot
2.Related Work
最流行的方法:K-rank 方法【14】
Soft methods
soft 损失项对于 domain and task transfer 是有用的,主要是为了避免数据集的偏差,【45】中有详细的损失函数的定义。
Age estimation 可被认为是个 image ranking 问题。
Image ranking
一个有序回归很流行的应用。将每个图片都分成离散等距的标签
【26】Age estimation使用浅层卷积网络避免过拟合 (三层卷积+两层fc+softmax)
《Age and Gender Classification using Convolutional Neural Networks 》CVPR_2015
【32】使用相似的CNN+K-1个二分类器
https://blog.csdn.net/u011961856/article/details/78984696
https://blog.csdn.net/MatouKariya/article/details/82562358
《Ordinal Regression with Multiple Output CNN for Age Estimation》 CVPR_2016
30使用了深度NN框架, uses multiple instances of the VGG-16 network
Monocular depth estimation
很有用: 机器人和自动驾驶,如场景理解,三维重建,和三维物体分析
二维图像的深度研究【34】【1】【24】【35】
CNN出现后:【49】【13】【11】【47】【12】【17】,效果好很多
ordinal regression 出现更好了!DORN network 【15】
Horizon estimation
一般来说,只要参数空间适当地离散化,任何涉及度量回归的任务都可以解释为有序回归任务。
Horizon estimation在单目和多视点的场景理解任务中显示出许多优点 【22】【10】
【48】 传统的分类方法是利用图像中地平线参数的离散值和候选值来估计图像的消失点。
【46】subwindow aggregation method
【25】horizon被提取为潜在的语义线。
3.Method
与K-rank方法不同,提出一种简单直观的方法,将有序回归的问题看作是传统分类问题
最后一层不是像K-rank方法输出神经元是类别的2倍,而是和类别一样的数量。
不显式修改网络架构;
3.1.Encoding Regression as Classification
分类通常表示为one-hot向量;训练时使用像交叉熵这样的损失函数;输出层的激活函数通常是softmax;通过loss尽可能使得网络输出值和真实label(one-hot)接近。
问题:存在一些比真实label值更接近的类(个人理解:比如电影评级时候,评3级,可能3.4级更接近真实label)
K-rank解决方式:最后加了多个二分类 one-hot向量( 但是在标签属于连续域的情况下,会丢失有价值的信息 )
ours:
引入了一个新的公式来描述类别,它自然地封装了类之间的显式顺序关系。
y
=
{
r
1
,
r
2
,
.
.
.
,
r
k
}
y = \{r_1,r_2,...,r_k \}
y={r1,r2,...,rk}
表示在这个分类问题中的有序类别或等级

y表示一个特定rank rt下样本的ground-truth label
从该式子可以看出,其实就是在输入label的时候将其转换为带顺序的label
按照论文给出的公式敲了一下5分类的代码,以及最后的soft label结果


φ ( r t , r i ) φ(r_t,r_i) φ(rt,ri)表示loss function,(衡量真实ground truth label r t r_t rt和 r i r_i ri之间的距离)
———————————上式为Soft Ordinal vectors (or SORD)—————————————————
其实就是比较像softmax
3.2.Backpropagation of Metrics
优点:梯度容易计算
假设使用交叉熵作为loss function,其梯度为

yi is the element of a soft label vector for rank ri ,and pi is the network’s Softmax value of the logit output node oi that corresponds to the same rank.
给定真实rank rt的一个输入,C是个大于0的常数使得softmax分母和SORD分母匹配

令
O
i
′
=
o
i
+
l
o
g
C
O_i'=o_i+logC
Oi′=oi+logC则可以简化损失函数的梯度

直观上,SORD能训练网络使得在接近真实类节点的值大,而不接近的话,值小
当
loss最小
3.3. SORD Properties
优点:
1、公式容易复现,只需两行代码。1)计算所有φ,2)通过φ计算soft label y
2、 可以使用现有的分类架构来进行有序回归,而不需要显式地修改单个层(开始批评K-rank方法,在最后一层时使用了二倍类别的神经元,而本文就不一样了,就和类别数一样)
3、既可以在最后一层使用argmax作为输出,也可以使用一个简单求期望的值
4、 SORD能轻易的封装来自连续域的数据 。举了个例子,在单目深度估计任务中,真实深度值rt=2.3,不属于Y。现在有两个连续的ranks,ri=2m,ri+1=3m,那SORD就会慢慢向ri去平衡,但是最终不会达到ri,最后呢rt_predication=2.1m并且产生一个y_predication
4.Experimental Results
图像美学数据集 Image Aesthetics dataset —>image quality
Adience dataset —> age estimation
https://www.douban.com/note/643300888/ + https://blog.csdn.net/qq_24819773/article/details/88596521
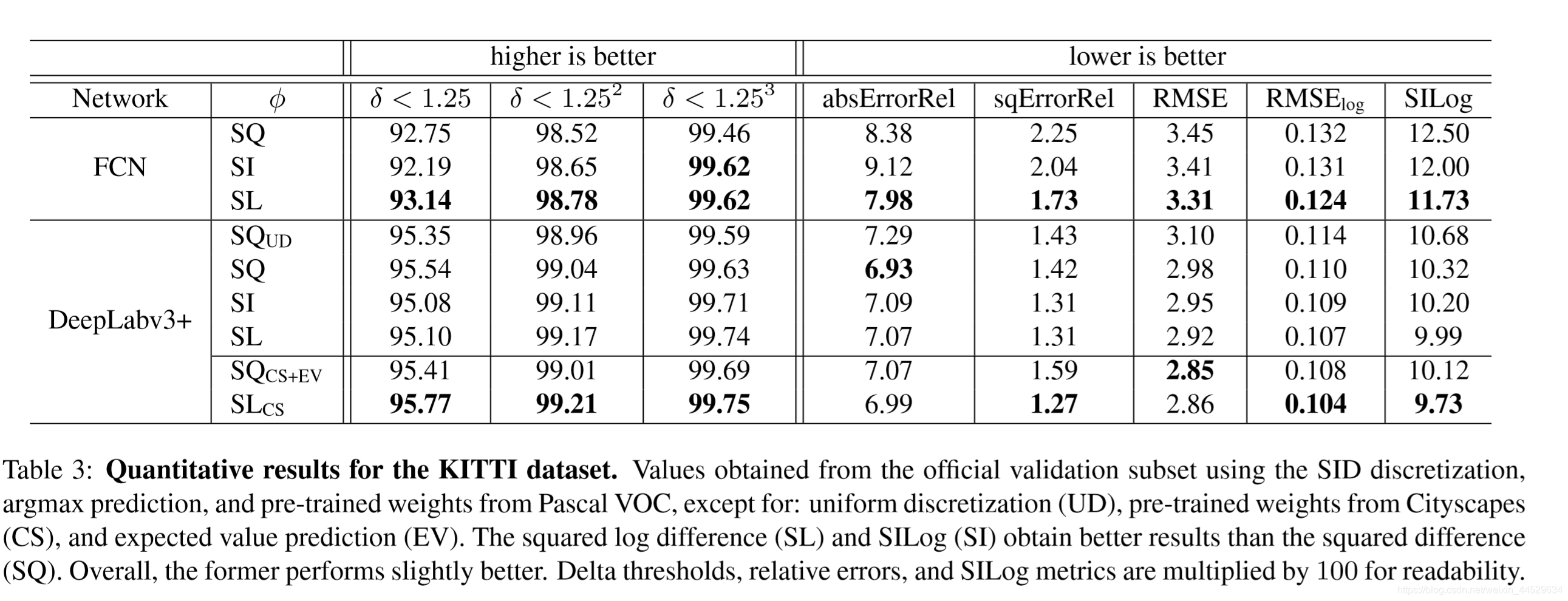
自动驾驶场景 KITTI dataset —> predict depth
Wild dataset —> estimate the horizon line parameters ???
setup:
Intel i7+1080Ti GPU+Keras+pre-trained network+当误差稳定时,lr*0.1+SGD(momentum=0.9)+loss(KL散度)
4.1. Image Ranking
Image aesthetics
The Aesthetics dataset 类别:
1、 “unacceptable” :质量极差、失焦、曝光不足或画框差;
2、“flawed” : 低质量图像(稍微模糊,过度/曝光不足,框架不正确),没有艺术价值
3、 “ordinary”:没有技术缺陷(画框好,焦点清晰),但没有艺术价值;
4、 “professional” :(完美的取景、对焦、闪电),或具有一定的艺术价值;
5、 “exceptional”:非常吸引人的图像,表现出突出的质量(摄影和/或编辑技术)和很高的艺术价值
图片由至少5个不同等级的人进行注释,最后的ground-truth label为所有评级取均值

75%, 5%, and 20% for training, validation, and test respectively
VGG-16 LR=10-4 mini_batch=32 epoch=50
Training images are resized to 256 × 256 pixels, and randomly cropped to 224 × 224 when fed to the network.(数据增强)
5折交叉验证
与【30】baseline作比较
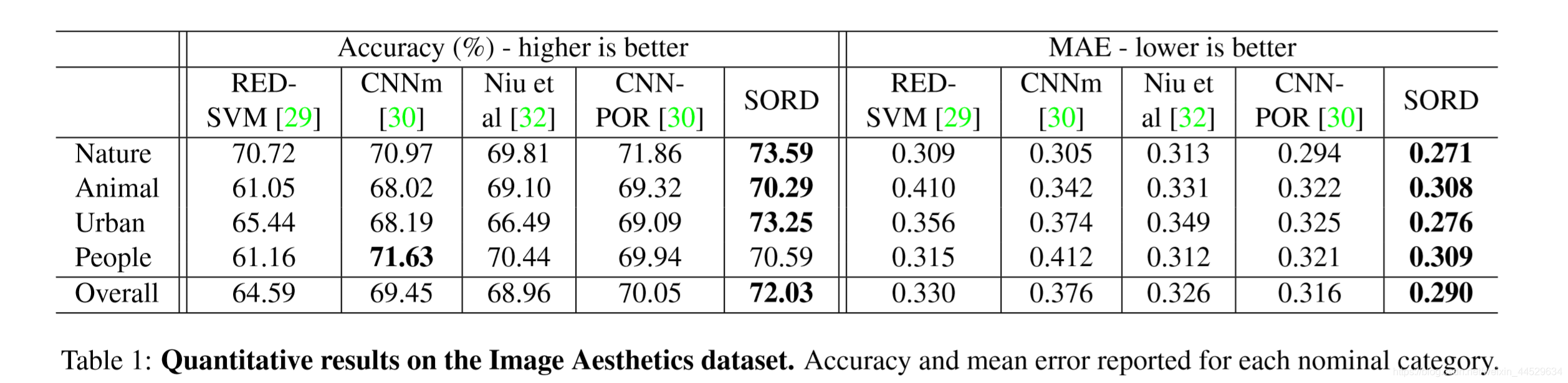
accuracy平均提高2% MAE平均提高0.02
Age estimation
https://blog.csdn.net/chaipp0607/article/details/90739483
The Adience dataset
2284个人 36k个人脸图像 5折交叉
年龄分成八个组:0-2, 4-6, 8-13, 15-20, 25-32, 38-43, 48-53, 大于60
对性别&年龄分类
VGG-16 LR=10-3 mini_batch=32 epoch=50
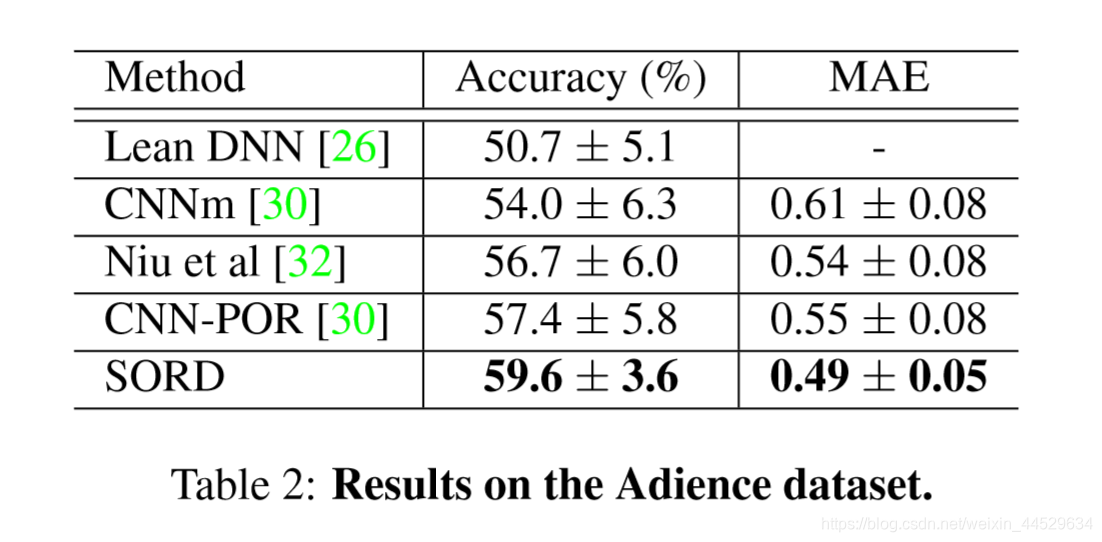
accuracy平均提高2% MAE平均提高0.05
4.2. Monocular Depth Estimation
之后有一篇《Deep Ordinal Regression Network for Monocular Depth Estimation》是ROB2018 中深度预测的冠军方案。**(抓紧看)**https://blog.csdn.net/kingsleyluoxin/article/details/82377902
用到了空间递增离散化(SID)
size about 375×1241. There are 42,949 stereo training pairs and 3,426 validation pairs. The official test set consists of 500 images that have been cropped to size 352×1216
三种loss:
SQ
SL
【12】SILog error 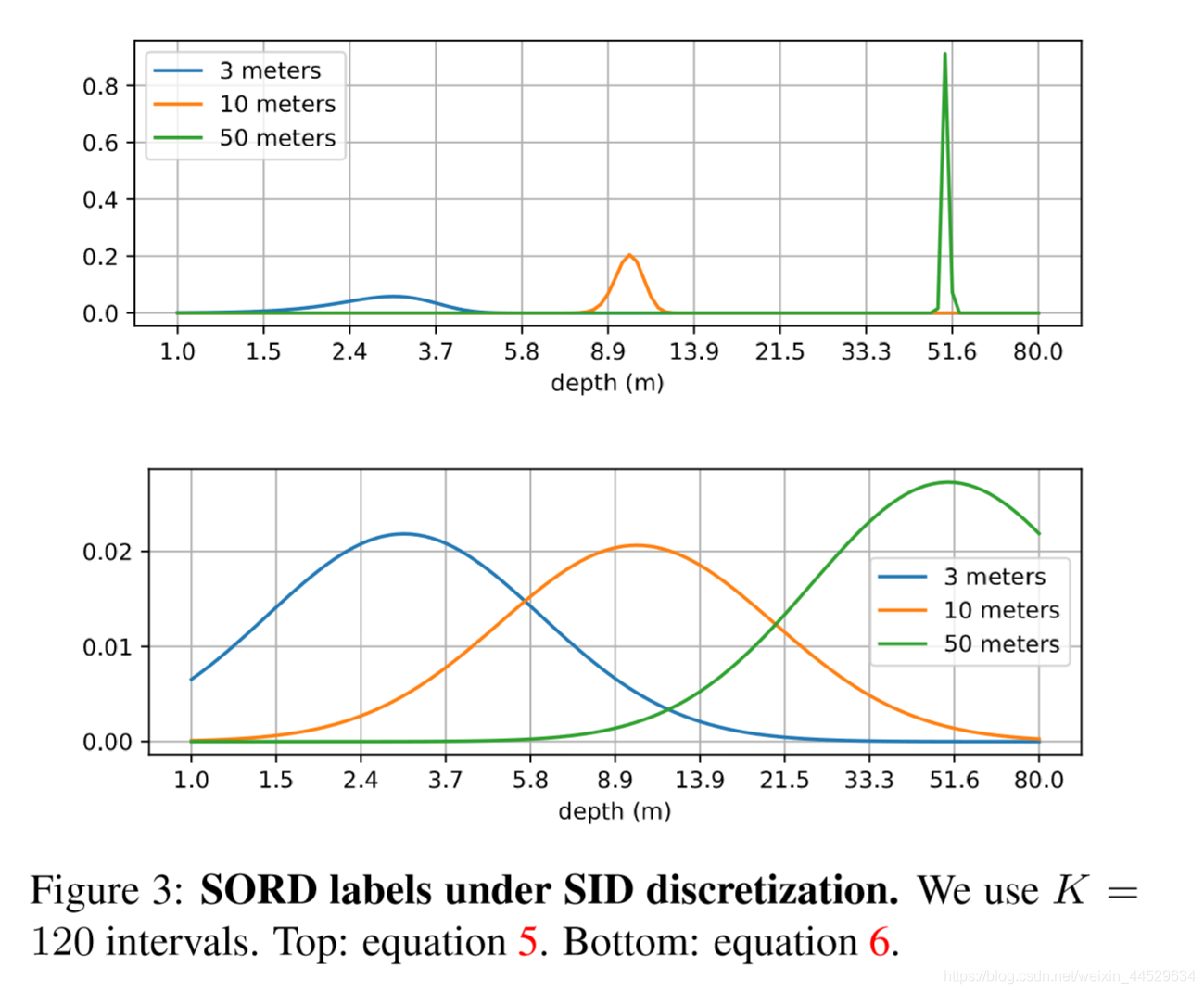
Number of intervals
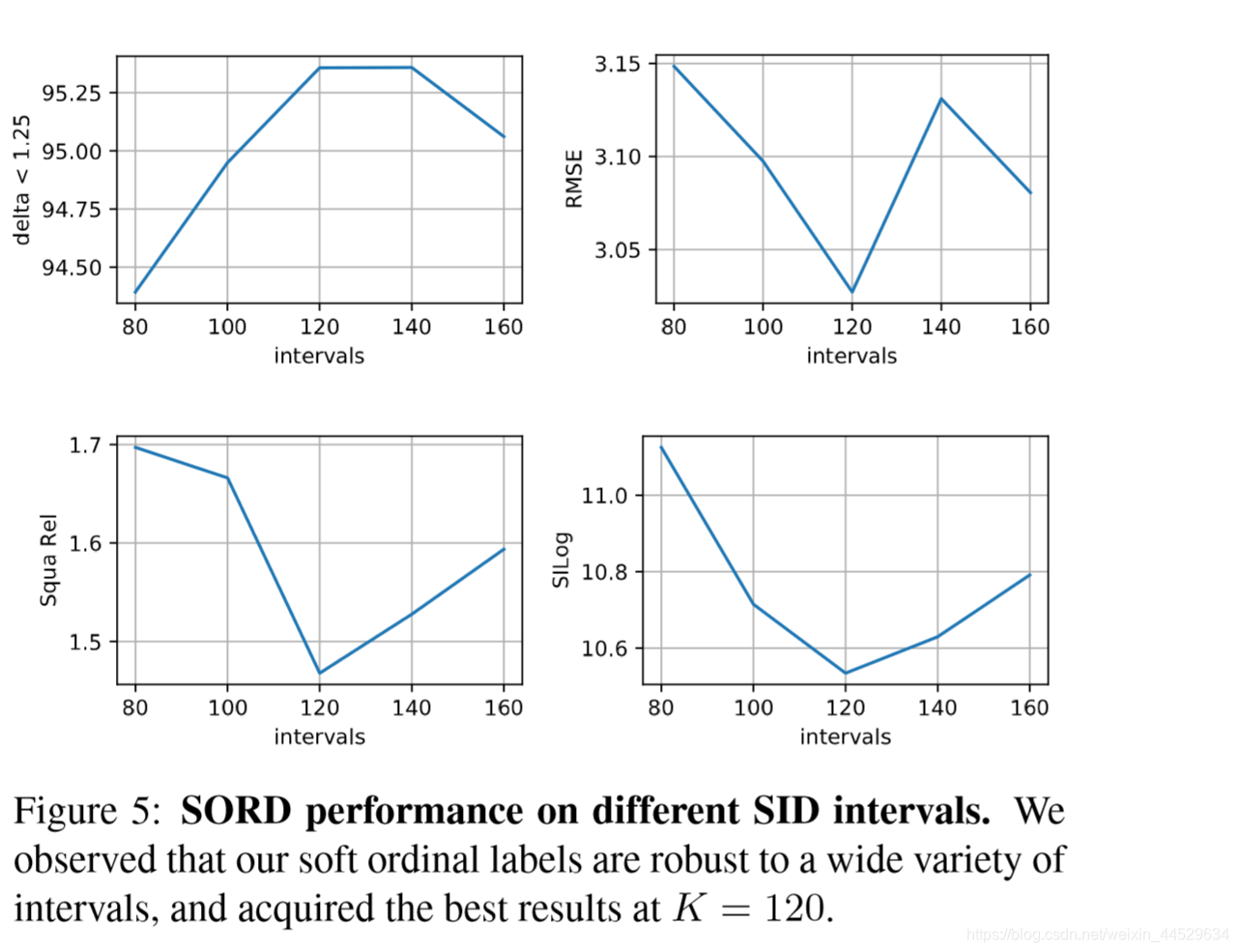
4.3. Horizon Estimation


















 2748
2748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









