






我们在之前的文章快速上手LSTM-CSDN博客中提及了RNN的几种不同的类型,其中有同步的 many to many 的根据视频的每一帧对视频分类任务,以及异步的 many to many 文本翻译。对于这种输入和输出不等长的序列,我们采用seq2seq(sequence to sequence)模型解决。
1. Seq2seq
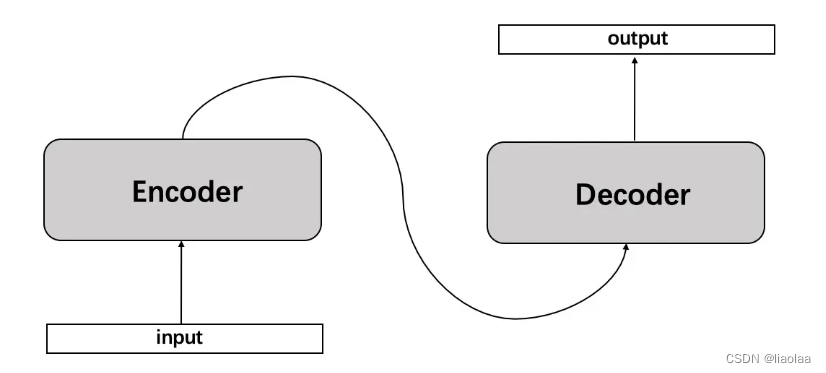
seq2seq 是由 encoder(编码器)和 decoder(解码器)构成,这个 encoder 和 decoder 都是由 RNN 组成的。其中 encoder 负责对输入句子的理解,转化为 context vector(语义向量),decoder 负责对理解后的句子的向量进行处理,解码,获得输出。这个过程就和我们人在看到一段话,理解段落大意之后按照自己的方式表达出来。
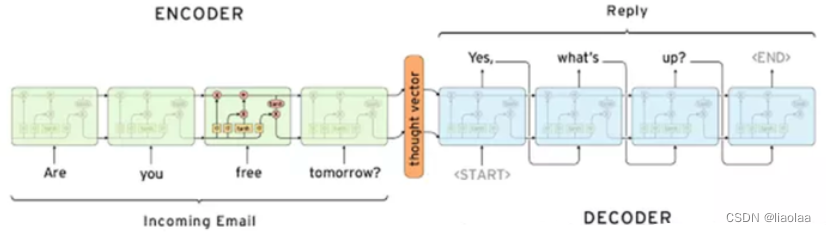
那么在这需要注意一个问题,在 encoder 的过程中得到的 context vector 作为 decoder 的输入,那么这样一个输入如何得到多个输出呢?
其实就是当前时间步输出,作为下一个单元的输入,然后得到下一个时间步的输出,依次循环直至遇到结束符 “<EOS>”(“<END>”)。当然,我们收集的数据都是没有这些特殊词元(“<UNK>”,“<PAD>”,“<SOS>”, “<EOS>”等)的,需要我们在数据集中自行添加。
2. encoder
encoder 的目的就是对文本进行编码,这里首先要明白我们的输入是会先经过 embedding 的得到的embedded,我们在 encoder 和 decoder 中可以使用rnn,lstm或者是gru,两个编码器都得使用同样的。在encoder中每一个时间步的输入都会得到结果,比如上面这句“Are you free tomorrow?” 会被处理成 'Are' 'you' 'free' 'tomorrow' '?' <EOS>,所以我们输入的句子长度是比原始句子多一出一个 <EOS> 词元的,整个过程是一个和句子长度相关(包含<EOS>词元)的循环。
注意:1. 我们一般使用 encoder 最后一个时间步的输出作为句子的编码结果。
2. <EOS> 词元只会在 encoder 中被使用。
"""
编码器
"""
import torch.nn as nn
from torch.nn.utils.rnn import pad_packed_sequence, pack_padded_sequence
import config
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(num_embeddings=len(config.num_sequence),
embedding_dim=config.embedding_dim,
padding_idx=config.num_sequence.PAD) # padding_idx 不会被更新,注意传入的是数值不是字符串
self.gru = nn.GRU(input_size=config.embedding_dim,
num_layers=config.num_layer,
hidden_size=config.hidden_size,
bidirectional=False, batch_first=True,
dropout=0.5)
def forward(self, input, input_length):
"""
:param input: [batch_size, seq_len]
:param input_length: 输入进编码器的句子的真实长度
:return:
"""
input_embedded = self.embedding(input) # input_embedded: [batch_size, seq_len, embedding_dim]
# 打包,加速计算
input_embedded = pack_padded_sequence(input_embedded, input_length, batch_first=True)
out, hidden = self.gru(input_embedded) # hidden: [num_layers*num_directions, batch_size, hidden_size]
# out: [batch_size, seq_len, hidden_size]
# 解包
out, out_length = pad_packed_sequence(out, padding_value=config.num_sequence.PAD,
batch_first=True)
return out, out_length, hidden
我们可以看一下输出打印一下 encoder的结构 和 encoder的输出
if __name__ == '__main__':
from dataset import train_data_loader
encoder = Encoder()
print(encoder)
for data, label, data_length, label_length in train_data_loader:
out, out_length, hidden = encoder(data, data_length)
print(out.shape)
print(hidden.shape)
print(out_length)
breakEncoder(
(embedding): Embedding(14, 50, padding_idx=0)
(gru): GRU(50, 32, num_layers=2, batch_first=True, dropout=0.5)
)
torch.Size([128, 8, 32])
torch.Size([2, 128, 32])
tensor([8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 6, 6, 5])补充:
在上面使用了 torch.nn.utils.rnn 提供的一对函数 pack_padded_sequence() 用来打包数据和 pad_packed_sequence() 用来解包数据,这里有个比较坑的点,它输入的数据需要根据输入句子真实长度降序排序,且要求输入的数据是填充过的。它能够帮我们加速计算,因为我们的每一个 batch 中的句子长度都必须一致,但是输入的文本的句子大多数情况都是长短不一的,所以我们会对句子长度进行填充,截断,使句子保持一致,对于我们用于填充的特殊词元,我们并不希望它进入encoder,如果填充的值进入了 encoder 里会对句子语义的理解出现误差,因为填充的地方在原来的句子是没有词的,还有就是会加大计算量。
例如:
有一个batch_size为2的数据sentence_1:[9, 4, 6, 6, 3, 7, 8, 1],sentence_1:[3, 5, 6, 0, 0, 0, 0, 0]真实的句子长度分别为8和3。填充词元 <PAD> 的值是0,先不考虑embedding,首先我们会根据句子长度降序排序得到:
batch: [[9, 2, 4, 6, 3, 7, 8, 1],
[3, 5, 6, 0, 0, 0, 0, 0]]
pack_padded_sequence() 会根据传入的真实句子长度,以及填充词元的值0,传入encoder的数据会被打包成
batch: [[9, 2, 4, 6, 3, 7, 8, 1],
[3, 5, 6] ]
pad_packed_sequence() 会将压缩完数据填充回去。
3.context vector(语义向量C)
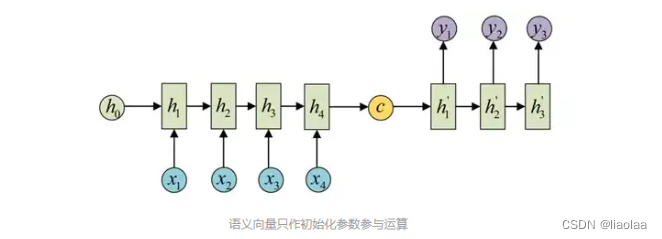
对于 encoder 的输出结果我们使用它的 context vector ,参与 decoder 的计算,有两种方式,第一中方式是只参与 decoder 中第一个时间步,每个时间步的输出做为下一个时间步的输入。如下:
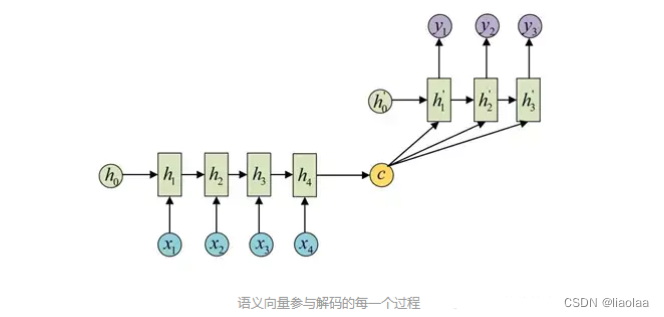
第二种方式是参与 decoder 中的每一个时间步,每个时间步的输出做为下一个时间步的输入。如下:
4. decoder
在解码器中,通过循环依次计算每个时间步。在这里我们将 context vector 作为初始的隐层状态,输入置为 [batch_size, 1] (特殊词元“<SOS>”值为1,代表句子开始,编码器开始工作),每一次时间步输出[batch_size, hidden_size] ,,hidden_size映射到vocab_size,当前这这个输出的词作为下一个时间步的输入再进行解码。解码器完成整个句子的解码之后会获得 seq_len 的输出拼接(concat)成 [batch_size, seq_len, vocab_size] 。
"""
解码器
1.获取encoder的输出,作为decoder初始的hidden_state
2.decoder的第一个时间步输入 <SOS>:[batch_size, 1]
3.得到第一个时间步输出 hidden_state
"""
import torch.nn as nn
import torch
import torch.nn.functional as F
import config
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(num_embeddings=len(config.num_sequence),
embedding_dim=config.embedding_dim,
padding_idx=config.num_sequence.PAD)
self.gru = nn.GRU(input_size=config.embedding_dim,
hidden_size=config.hidden_size,
num_layers=config.num_layer,
bidirectional=False, batch_first=True,
dropout=0.5)
self.fc = nn.Linear(config.hidden_size, len(config.num_sequence))
def forward(self, label, context_vector):
"""
:param label:
:param context_vector: 语义向量 context vector
:return:
"""
# 获取encoder的输出,作为decoder初始的hidden_state
decoder_hidden = context_vector
# 得到 [batch_size, 1] 实现 <SOS>
# 作为decoder的第一个时间步的输入
batch_size = label.size(0)
decoder_input = torch.LongTensor(torch.ones([batch_size, 1], dtype=torch.int64)*config.num_sequence.SOS).to(config.device)
# 保存预测的结果
decoder_outputs = torch.zeros([batch_size, config.max_sentence_len+2, len(config.num_sequence)]).to(config.device)
for i in range(config.max_sentence_len+2):
decoder_output_t, decoder_hidden_t = self.forward_step(decoder_input, decoder_hidden)
# 保存
decoder_outputs[:, i, :] = decoder_output_t
value, idx = torch.topk(decoder_output_t, 1)
decoder_input = idx # 拿到这个词的序列
return decoder_outputs, decoder_hidden_t
def forward_step(self, decoder_input, decoder_hidden):
"""
完成每一个时间步的计算
:param decoder_input: [batch_size, 1]
:param decoder_hidden: [1, batch_size, hidden_size]
"""
decoder_input_embedded = self.embedding(decoder_input) # [batch_size, 1, embedding_dim]
out, decoder_hidden = self.gru(decoder_input_embedded, decoder_hidden) # out: [batch_size, 1, hidden_size]
# decoder_hidden: [1, batch_size, hidden_size]
# 完成到词表的映射hidden_size -> vocab_size
out = out.squeeze(1) # out: [batch_size, 1, hidden_size] -> [batch_size, hidden_size]
out = self.fc(out) # out: [batch_size, hidden_size] -> [batch_size, vocab_size]
output = F.log_softmax(out, dim=-1)
# print("output:", output.shape)
return output, decoder_hidden5. 结语
总之,seq2seq模型通过encoder接收一个长度为N的序列,得到一个context vector ,然后由 decoder 把这一个 context vector 转化为长度为M的序列作为输出,从而实现了一个N to M的模型,用于处理输入序列和输出序列不同的任务,比如,文本翻译、文章摘要、问答等等。
代码实现可参考seq2seq实现案例已上传仓库liaolaa / string-prediction · GitCode














 2130
2130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









