







原文链接:https://zhuanlan.zhihu.com/p/59075508


最近放出来了一篇CVPR2019论文,文章提出了一种新的高效卷积方式:HetConv,在CIFAR10、ImageNet等数据集超过了标准卷积以及DW+PW的高效卷积组合形式,取得了更高的分类性能。
论文链接:https://arxiv.org/abs/1903.04120
【Motivation】
目前提高CNN性能的主要手段有:
- 增加模型宽度和深度。这样带来的代价是计算量会变得非常大。
- 设计更高效的卷积结构。比如depthwise conv、pointwise conv、groupwise conv等。这一类卷积结构的特点是计算量相比标准卷积小,代替原始的标准卷积方式可以较少一定的计算量,同时保持较高的精度。
- 为追求更快更小的网络结构,用剪枝(model pruning)的手段进行模型压缩(model compression),包括connection pruning、filter pruning、quantization等方式。模型剪枝的方式在某些方面很有效,缺点是得到一个好的模型通常需要大量的训练时间。训练-剪枝-再训练(fine-tune)的方式带来的计算资源和时间成本非常大,且最后不一定能得到令人满意的压缩模型。
目前来看,性价比最高的就是采用高效的轻量级网络,代表性的有:Xception、MobileNet系列、ShuffleNet系列。为了取得更高的性能,必须要精心设计网络结构,实现accuracy-speed trade-off。
设计一个新的有效的网络结构不是一件容易的事,需要不断的试错、总结,文章从卷积方式入手,提出了一种新的卷积方式来代替原来的卷积,取得了更好的实验效果。
像标准卷积、DW、PW、GW式的卷积的一个共同点就是所有的卷积核大小一致,称为“Homogeneous Convolution”,比如3x3x256的conv2d,每个卷积核的尺寸都是3x3大小。
文章提出的“Heterogeneous Convolution”,顾名思义,就是卷积核的尺寸大小不一。比如在有256个通道的卷积核中,一部分kernel size为1,另一部分kernel size为3。
HetConv带来的好处是可以无缝替换VGG、ResNet、MobileNet等结构的卷积形式,这种新的卷积形式,可以向标准卷积一样,从新开始训练,得到比pruning更好的性能效果。文章还指出,HetConv与标准卷积一样,实现latency zero。

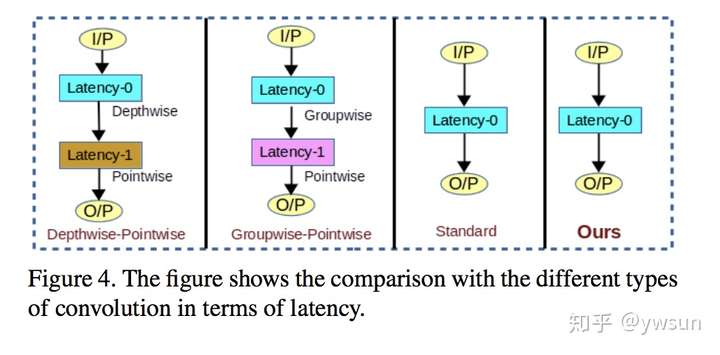
【Method】
HetConvolution的方式很简单,就是将一部分卷积核尺寸设置为K,另一部分设置为1。更直观的可以看下图。

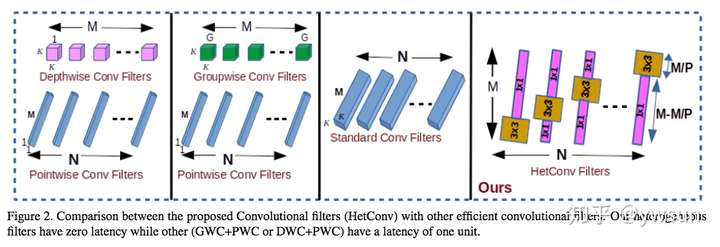
计算量的分析:
【标准卷积】计算量:
其中 是卷积输出特征图的尺寸,M是输入通道数,N是输出通道数,K是卷积核尺寸。
HetConvolution:假设输入通道数为M,有比例为P的卷积核尺寸为K,这样的kernel数为 ,其他都是
大小,这样的kernel数为
,
那么 卷积的计算量为:
卷积的计算量为:
因此总的计算量为:
HetConvolution与标准卷积的计算量之比:
当P=1时,HetConv变为标准卷积,计算量之比为1。
【DW+PW】计算量: (原文有误)
DW+PW与标准卷积的计算量之比:
由公式(3)可知,增大P,HetConv变为标准卷积,控制P的大小,可以控制accuracy和FLOPs。
极端情况下,P=M的时候,公式(3)和(5):
因此,MobileNet比HetConvolution计算量更大。
【GW+PW】计算量:
与标准卷积的计算量之比:
由公式(3)和(8)可知,P=G的时候:
HetConv的计算量比GW+PW更少。
【Experiments】
作者选取了VGG、ResNet、MobileNet等网络,通过在CIFAR-10、ImageNet数据集上的实验验证HetConv的有效性。



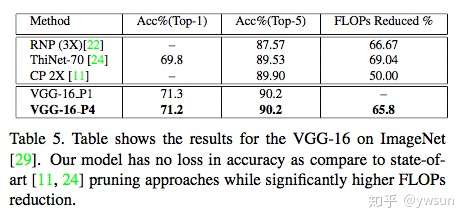

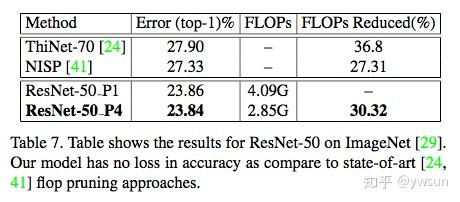

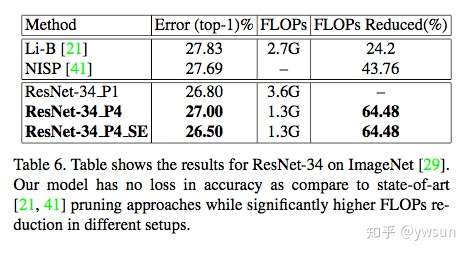
【总结】
文章提出了一种新的卷积方式,通过计算FLOPs和实验证明,HetConv可以在更少计算量的上面取得更高的精度,文章也和model conpression进行了对比,从实验结果来看,效果也挺明显。HetConv可以和现有的网络结构结合,操作简单方便。
对于HeConv的实用性方面可能还需要时间来证明,毕竟理论计算量和实际情况还是有些差距,另外作者没有在detection、segmentation任务做实验,但从分类任务来说,缺少一定的可信度。希望尽快有开源实现。














 1169
1169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









