







参考链接:https://blog.csdn.net/qq_37541097/article/details/117653177
https://blog.csdn.net/Strive_For_Future/article/details/115220627
为什么要归一化:
在机器学习和深度学习中,有一个共识:独立同分布的数据可以简化模型的训练以及提升模型的预测能力——这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。也就是说我们在使用机器学习和深度学习的时候,会把数据尽可能的做一个独立同分布的处理,用来加快模型的训练速度和提升模型的性能。
差别:
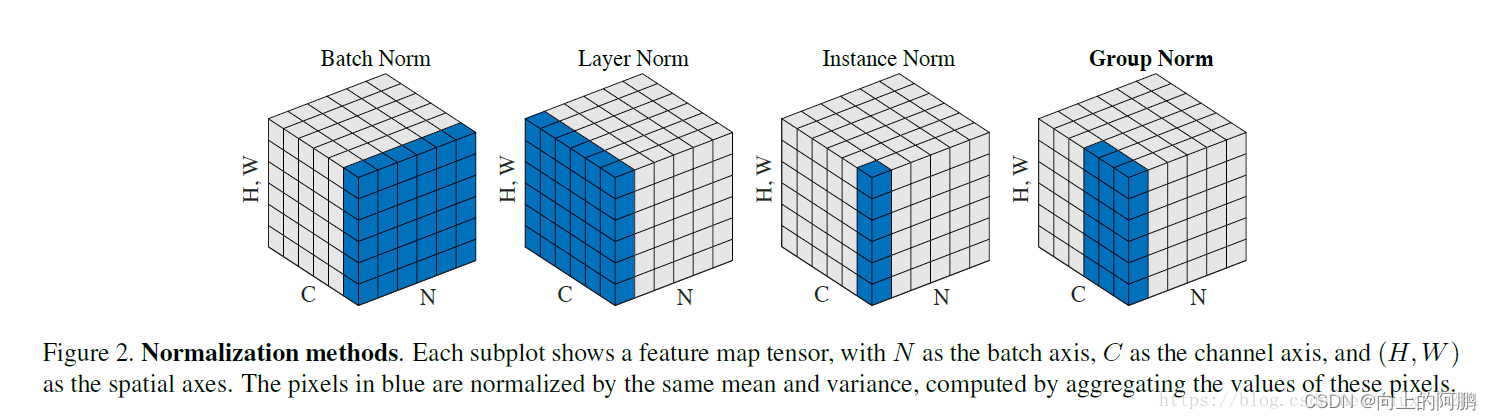
BN的均值和标准差是在小批量上按维度计算的会考虑到batch上的每一个数据,对一个batch数据的每个channel进行Norm处理,因此在小batch上的效果较差,然而,LN是主要用于NLP领域的,每个词向量的含义不同,若按照整个batch的数据进行归一化会产生较大误差,因此LN是对单个数据的指定维度进行Norm处理与batch无关。
总结:
BN:取不同样本的同一个通道的特征做归一化,逐特征维度归一化;
LN:取的是同一个样本的不同通道做归一化,即整个样本归一化,逐个样本归一化。

















 2158
2158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









